大规模深度学习广告系统:分布式GPU分层参数服务器
需积分: 10 148 浏览量
更新于2024-07-16
1
收藏 729KB PDF 举报
"大规模深度学习广告系统的分布式分层GPU参数服务器是一种优化的深度学习训练架构,旨在处理在线广告系统中的海量参数。该系统利用GPU的高带宽内存、CPU主存和SSD作为三层分层存储,实现了高效的数据管理和计算。通过将神经网络训练过程集中在GPU上,并结合分层工作流,确保了模型训练的有效性和可扩展性。"
深度学习在广告系统中的应用已经越来越广泛,尤其是在推荐和排名等关键任务中。这些系统通常需要处理来自多个来源的输入,如查询-广告的相关性、广告特性以及用户画像,这些输入被编码成稀疏的一热或多热二进制特征。然而,每个样本中非零特征值的比例很小,这给模型训练带来了挑战。
传统的深度学习模型在面对TB级别的参数时,可能会超出单个计算节点的GPU或CPU内存限制。例如,一个赞助在线广告系统可能包含超过10^11个稀疏特征,导致神经网络成为一个具有约10TB参数的庞大模型。为了解决这个问题,论文提出的分布式GPU分层参数服务器架构提供了一个创新的解决方案。
这个架构的核心是将存储层次结构分为三部分:GPU高带宽内存、CPU主存和SSD。GPU主要用于执行计算密集型的神经网络训练,而CPU主存和SSD则作为辅助存储,以处理大量的稀疏特征。通过这种分层设计,系统能够根据数据访问模式智能地缓存和调度参数,降低了数据传输延迟,提高了训练效率。
此外,该系统还可能采用了异步更新策略,允许不同GPU节点并行地进行参数更新,进一步提升了训练速度。同时,通过动态调整工作流,系统能够适应不同的工作负载和资源可用性,确保了整体的可扩展性。大量的实验结果验证了该系统在处理大规模深度学习广告系统时的性能和有效性。
"分布式分层GPU参数服务器"是一个强大的工具,它为处理大规模深度学习模型提供了有效的途径,特别是在在线广告这样需要处理海量数据和复杂模型的领域。这一技术的实施,不仅可以加速训练过程,还能帮助公司更有效地利用硬件资源,提升广告系统的性能和用户体验。
Distributed Hierarchical GPU Parameter Server for Massive Scale Deep Learning Ads Systems
justification of adopting DNN models for CTR prediction.
•
Hashing reduces the accuracy. Even with
k = 2
34
, the
test AUC is dropped by 0.7%.
•
Hash+DNN is a good combination for replacing LR.
Compared to the original baseline LR model, we can re-
duce the number of nonzero weights from 31B to merely
14.6M without affecting the accuracy.
Table 2 summarizes the experiments on web search ads data.
The trend is essentially similar to Table 1. The main differ-
ence is that we cannot really propose to use Hash+DNN for
web search ads CTR models, because that would reduce the
accuracy of current DNN-based models and consequently
would affect the revenue for the company.
Table 2. OP+OSRP for Web Search Sponsored Ads Data
# Nonzero Weights Test AUC
Baseline LR 199,359,034,971 0.7458
Baseline DNN 0.7670
Hash+DNN (k = 2
32
) 3,005,012,154 0.7556
Hash+DNN (k = 2
31
) 1,599,247,184 0.7547
Hash+DNN (k = 2
30
) 838,120,432 0.7538
Hash+DNN (k = 2
29
) 433,267,303 0.7528
Hash+DNN (k = 2
28
) 222,780,993 0.7515
Hash+DNN (k = 2
27
) 114,222,607 0.7501
Hash+DNN (k = 2
26
) 58,517,936 0.7487
Hash+DNN (k = 2
24
) 15,410,799 0.7453
Hash+DNN (k = 2
22
) 4,125,016 0.7408
Summary.
This section summarizes our effort on develop-
ing effective hashing methods for ads CTR models. The
work was done in 2015 and we had never attempted to pub-
lish the paper. The proposed algorithm, OP+OSRP, actually
still has some novelty to date, although it obviously com-
bines several previously known ideas. The experiments are
exciting in a way because it shows that one can use a single
machine to store the DNN model and can still achieve a
noticeable increase in AUC compared to the original (large)
LR model. However, for the main ads CTR model used in
web search which brings in the majority of the revenue, we
observe that the test accuracy is always dropped as soon
as we try to hash the input data. This is not acceptable in
the current business model because even a
0.1%
decrease in
AUC would result in a noticeable decrease in revenue.
Therefore, this report helps explain why we introduce the
distributed hierarchical GPU parameter server in this paper
to train the massive scale CTR models, in a lossless fashion.
3 DISTRIBUTED HIERARCHICAL
PARAMETER SERVER OVERVIEW
In this section, we present the distributed hierarchical param-
eter server overview and describe its main modules from
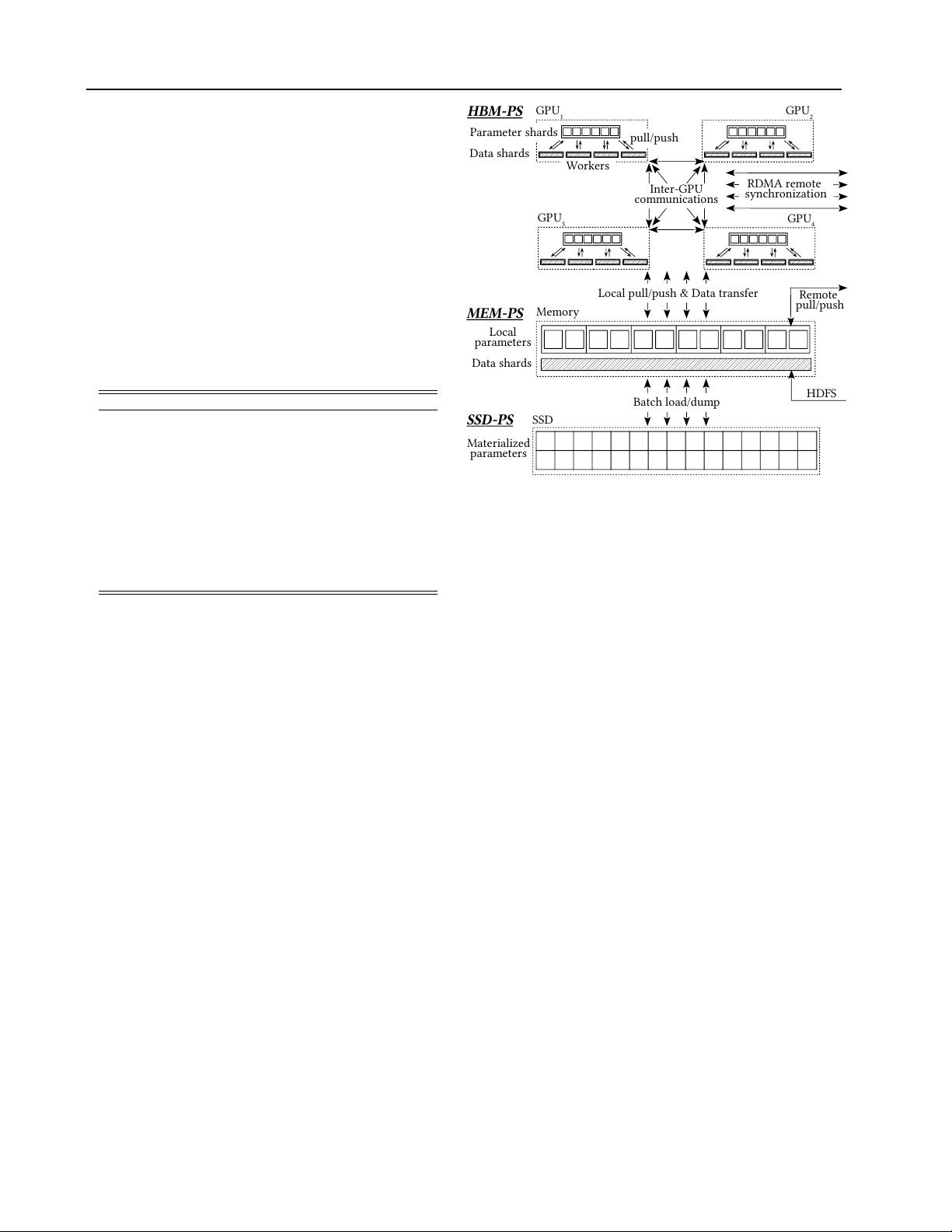
a high-level view. Figure 2 illustrates the proposed hier-
archical parameter server architecture. It contains three
major components: HBM-PS, MEM-PS and SSD-PS.
Workers
pull/push
Parameter shards
GPU
3
Inter-GPU
communications
Data shards
GPU
1
GPU
4
GPU
2
HDFS
Memory
Local
parameters
Data shards
SSD
Batch load/dump
Materialized
parameters
Local pull/push & Data transfer
SSD-PS
MEM-PS
HBM-PS
Remote
pull/push
RDMA remote
synchronization
Figure 2. Hierarchical parameter server architecture.
Workflow.
Algorithm 1 depicts the distributed hierarchi-
cal parameter server training workflow. The training data
batches are streamed into the main memory through a net-
work file system, e.g., HDFS (line 2). Our distributed train-
ing framework falls in the data-parallel paradigm (Li et al.,
2014; Cui et al., 2014; 2016; Luo et al., 2018). Each node
is responsible to process its own training batches—different
nodes receive different training data from HDFS. Then, each
node identifies the union of the referenced parameters in
the current received batch and pulls these parameters from
the local MEM-PS/SSD-PS (line 3) and the remote MEM-
PS (line 4). The local MEM-PS loads the local parameters
stored on local SSD-PS into the memory and requests other
nodes for the remote parameters through the network. Af-
ter all the referenced parameters are loaded in the memory,
these parameters are partitioned and transferred to the HBM-
PS in GPUs. In order to effectively utilize the limited GPU
memory, the parameters are partitioned in a non-overlapped
fashion—one parameter is stored only in one GPU. When a
worker thread in a GPU requires the parameter on another
GPU, it directly fetches the parameter from the remote GPU
and pushes the updates back to the remote GPU through
high-speed inter-GPU hardware connection NVLink (Foley
& Danskin, 2017). In addition, the data batch is sharded
into multiple mini-batches and sent to each GPU worker
thread (line 5-10). Many recent machine learning system
studies (Ho et al., 2013; Chilimbi et al., 2014; Cui et al.,
2016; Alistarh et al., 2018) suggest that the parameter stale-
ness shared among workers in data-parallel systems leads to
slower convergence. In our proposed system, a mini-batch
contains thousands of examples. One GPU worker thread
is responsible to process a few thousand mini-batches. An
剩余16页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-10-25 上传
2021-08-08 上传
2024-04-20 上传
439 浏览量
381 浏览量
368 浏览量

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







最新资源
- JavaScript实现的高效pomodoro时钟教程
- CMake 3.25.3版本发布:程序员必备构建工具
- 直流无刷电机控制技术项目源码集合
- Ak Kamal电子安全客户端加载器-CRX插件介绍
- 揭露流氓软件:月息背后的秘密
- 京东自动抢购茅台脚本指南:如何设置eid与fp参数
- 动态格式化Matlab轴刻度标签 - ticklabelformat实用教程
- DSTUHack2021后端接口与Go语言实现解析
- CMake 3.25.2版本Linux软件包发布
- Node.js网络数据抓取技术深入解析
- QRSorteios-crx扩展:优化税务文件扫描流程
- 掌握JavaScript中的算法技巧
- Rails+React打造MF员工租房解决方案
- Utsanjan:自学成才的UI/UX设计师与技术博客作者
- CMake 3.25.2版本发布,支持Windows x86_64架构
- AR_RENTAL平台:HTML技术在增强现实领域的应用
