深度学习分布式训练框架:Horovod介绍及应用
版权申诉
分布式深度学习与Horovod
分布式深度学习是指在多个计算节点上并行训练深度学习模型的技术。其主要目的是为了加速深度学习模型的训练过程,提高模型的训练速度和效率。分布式深度学习可以分为两种类型:模型并行和数据并行。
模型并行是指将深度学习模型拆分成多个部分,每个部分在不同的计算节点上运行。这种方法可以使模型训练速度加快,但是需要手动指定模型存放的硬件,编码复杂,伸缩性比较差,不能随意的增减GPU的数量,且不同节点模型计算有依赖关系,整体效率不高。
数据并行是指将训练数据分配到多个计算节点上,每个节点上运行相同的模型,但是使用不同的数据。这种方法可以使模型训练速度加快,且可以方便地扩展到更多的计算节点上。数据并行可以使用参数服务器或Ring-AllReduce算法来实现参数同步。参数服务器是指将模型参数存储在一个中央服务器上,并将其分配到不同的计算节点上。Ring-AllReduce算法是指将模型参数同步到所有计算节点上,并使用环形网络来减少通信开销。
Horovod是Uber开源的跨平台分布式训练框架,目标是让分布式深度学习训练快。Horovod支持多种分布式训练方案,包括MirroredStrategy、TPUStrategy、MultiWorkerMirroredStrategy、CentralStorageStrategy和ParameterServerStrategy等。Horovod也支持Pytorch分布式方案,包括torch.nn.DataParallel(DP)和torch.nn.parallel.DistributedDataParallel(DDP)。
Pytorch分布式方案中,DP模式采用的是PS架构,存在负载不均衡问题,主卡往往会成为训练的瓶颈,因此训练速度会比DDP模式慢一些。而DDP模式本身是为多机多卡设计的,在单机多卡的情况下也可以使用。DDP采用的是all-reduce架构,基本解决了PS架构中通信成本与GPU的数量线性相关的问题。在单机多卡情况下,使用DDP通常会比DP模式快一些。
分布式深度学习可以通过模型并行和数据并行两种方式来实现,Horovod是跨平台分布式训练框架,可以支持多种分布式训练方案,包括Pytorch分布式方案。
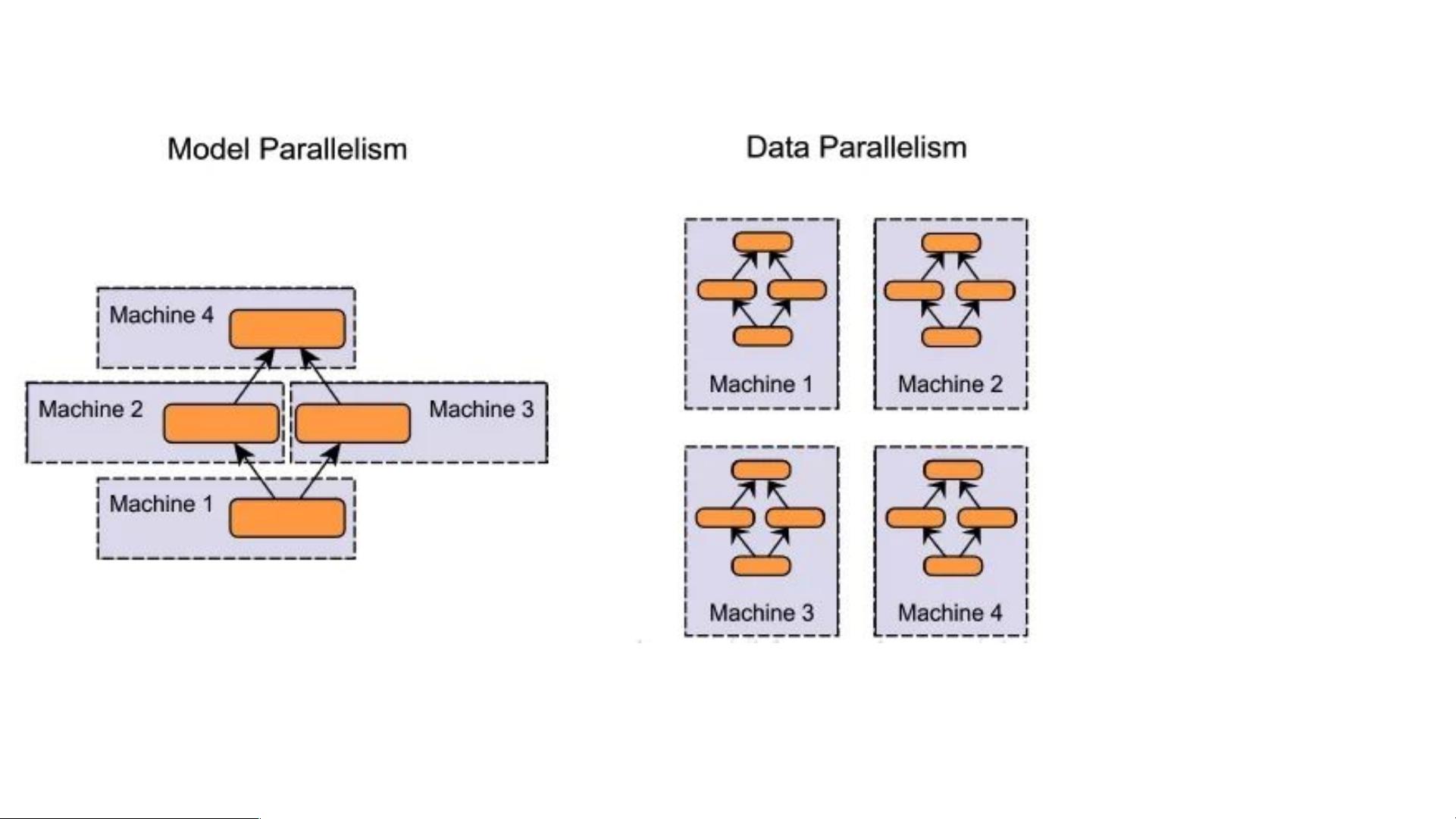
分布式深度学习类型
1. 模型并行
优点:
•
模型较大,单卡无法承载的
解决方案
缺点:
•
需要手动指定模型存放的硬
件,编码复杂
•
伸缩性比较差,不能随意的
增减 GPU 的数量
•
不同节点模型计算有依赖关
系,整体效率不高
2. 数据并行
优点:
•
GPU 相互独立,方便扩缩容
•
独立计算,加速效果好
缺点:
•
模型参数同步开销较大
剩余20页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-03-03 上传
2022-05-10 上传
247 浏览量
136 浏览量

weixin_41813620
- 粉丝: 13
- 资源: 8
 我的内容管理
展开
我的内容管理
展开







最新资源
- Windows编程之API函数大全
- 89s51 好程序 各种
- TOGAF-tutorial-presentation
- 89s51数字钟 程序
- GCC 中文用户手册
- mobile phone
- The Implement of Remote Control Software by using Java
- 自己整理的websphere portal主题皮肤开发资料
- websphere portal6.1主题皮肤开发资料
- VB入门实用教程(全)
- VMware Workstation使用手册
- 计算机专业英语教材计算机专业英语教材
- 000-960 的资料
- Flash读取数据库技术4
- Flash读取数据库技术3
- Flash读取数据库技术2
