理解SVM:支持向量机详解与应用
需积分: 10 122 浏览量
更新于2024-07-31
收藏 482KB PDF 举报
"支持向量机SVM是Cortes和Vapnik在1995年提出的一种非线性分类方法,具有处理小样本、非线性和高维数据的优势,广泛应用于模式识别和函数拟合。SVM基于统计学习理论的VC维理论和结构风险最小化原则,寻求最佳的模型复杂性和学习能力之间的平衡,以提升泛化能力。Vapnik的《Statistical Learning Theory》深入探讨了统计机器学习的思想,区别于传统机器学习的盲目实践。VC维衡量问题复杂度,而SVM对样本维数不敏感,适合处理高维文本分类问题。结构风险最小化是指在未知真实模型的情况下,选择最优化的假设模型来逼近问题的真实解。"
支持向量机(SVM)是一种强大的机器学习算法,主要用于二元分类和回归分析,但也可以通过扩展处理多类分类问题。其核心思想是构建一个最大边距超平面,将不同类别的数据点分离得尽可能远。在这个过程中,SVM特别关注那些距离超平面最近的数据点,即支持向量,这些点对于决定分类边界至关重要。
SVM的理论基础是Vapnik-Chervonenkis(VC)维,它量化了模型的复杂性。VC维高的模型可以表示更复杂的决策边界,但也可能导致过拟合,即对训练数据过度适应,而在未见过的新数据上表现不佳。为了克服这个问题,SVM采用结构风险最小化策略,通过正则化避免过拟合,同时追求良好的泛化性能。
在实际应用中,SVM引入了核函数这一关键概念。核函数能够将低维数据映射到高维空间,使得原本在原始空间中难以分隔的数据在高维空间中变得容易区分。常见的核函数有线性核、多项式核、高斯核(RBF)等,不同的核函数适用于不同的数据分布和问题情境。
除了上述理论,SVM在实际操作中还需要考虑一些重要因素,比如参数调整(如惩罚系数C和核函数的参数)、预处理(如特征缩放和缺失值处理)、以及选择合适的核函数。此外,对于大规模数据集,SVM的训练时间可能会很长,这时可以采用启发式方法或者核近似技术来提高效率。
总结来说,支持向量机SVM是一种基于统计学习理论的高效分类工具,它的优势在于处理非线性问题和高维数据,通过优化模型复杂性和泛化能力的平衡,以及利用核函数进行非线性映射,实现了在多种任务中的优秀性能。理解和掌握SVM的基本原理和应用技巧,对于机器学习领域的研究者和实践者来说都是至关重要的。
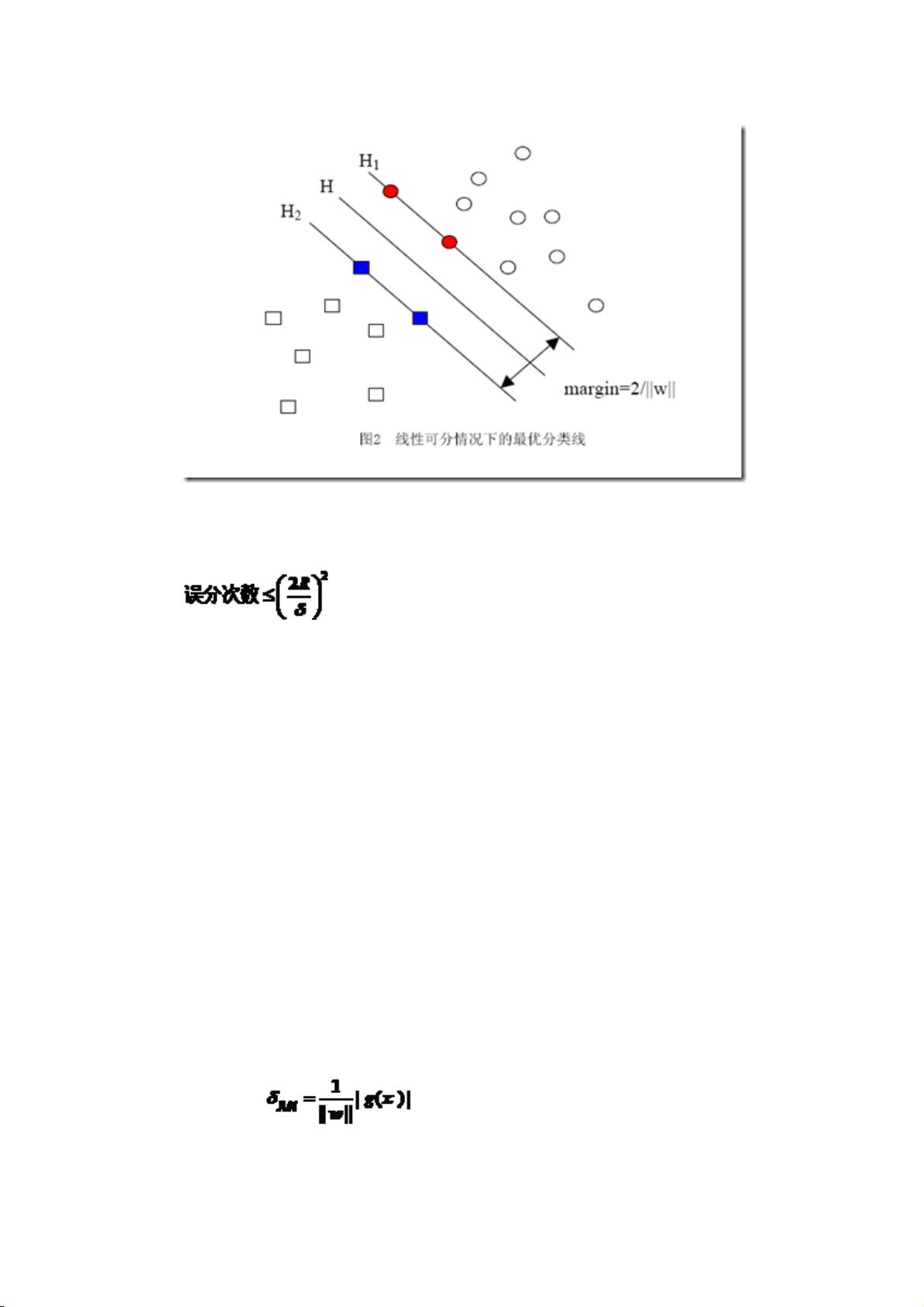
H 是分类面,而 H1 和 H2 是平行于 H,且过离 H 最近的两类样本的直线,H1 与 H,
H2 与 H 之间的距离就是几何间隔。
之所以如此关心几何间隔这个东西,是因为几何间隔与样本的误分次数间存在关系:
其中的 δ 是样本集合到分类面的间隔,R=max ||xi|| i=1,...,n,即 R 是所有样本
中(xi 是以向量表示的第 i 个样本)向量长度最长的值(也就是说代表样本的分布有多么
广)。先不必追究误分次数的具体定义和推导过程,只要记得这个误分次数一定程度上代
表分类器的误差。而从上式可以看出,误分次数的上界由几何间隔决定!(当然,是样本
已知的时候)
至此我们就明白为何要选择几何间隔来作为评价一个解优劣的指标了,原来几何间隔
越大的解,它的误差上界越小。因此最大化几何间隔成了我们训练阶段的目标,而且,与
二把刀作者所写的不同,最大化分类间隔并不是 SVM 的专利,而是早在线性分类时期就
已有的思想.
线性分类器的求解——问题的描述 Part1
上节说到我们有了一个线性分类函数,也有了判断解优劣的标准——即有了优化的目标,
这个目标就是最大化几何间隔,但是看过一些关于 SVM 的论文的人一定记得什么优化的
目标是要最小化||w||这样的说法,这是怎么回事呢?回头再看看我们对间隔和几何间
隔的定义:
间隔:δ=y(wx+b)=|g(x)|
几何间隔:
可以看出 δ=||w||δ 几何。注意到几何间隔与||w||是成反比的,因此最大化几
剩余20页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2012-07-02 上传
2015-07-15 上传
2011-04-20 上传
2010-12-15 上传
2010-06-06 上传

ztjht
- 粉丝: 1
- 资源: 1
 我的内容管理
展开
我的内容管理
展开







最新资源
- app:詹金斯的应用程序
- react-hot-export-loader:一个Webpack加载器,自动插入react-hot-loader代码,灵感来自react-hot-loader-loader
- DIY制作属于自己的CP2102 USB-UART桥接器(原理图+PCB源文件)-电路方案
- 雅典:开源网络思想。 内部封闭测试正在进行中! 通过https:forms.gle9L1D1T7R3G7pvh1e7加入候补名单。 赞助我们以更快获得测试版!
- uni-app之flex布局教程 uniapp在线教程 uni app视频教程
- jamesSampica.github.io:自己的博客
- Android动画效果源代码
- 教师招聘学习软件支持幼儿教师招聘,小学中学教师招聘,小学中学教育学心理学等等
- LoveAndShare:基于Python django建造的知识分享与视频播放网站
- fp-gitlab-example:用于转换API请求以使用fp-ts的示例代码
- 彻底搞懂Spring+SpringMVC+MyBatis 框架整合(IDEA版,含源码)
- EmployeeWageComputation
- my-first-webpage
- getting_cleaning_data:回购获取和清洁数据; JHU课程; 数据科学专业
- MPLAB ICD2仿真器原理图+PCB+HEX文件-电路方案
- 灰白经典婚纱照网站模板
