"eBPF技术在容器安全设计中的应用及内核审计"
需积分: 9 7 浏览量
更新于2024-01-15
收藏 773KB PDF 举报
Container容器安全设计方案是一个关键的主题,在云计算领域中得到了广泛的关注和使用。为了确保容器的安全性,需要采取一系列有效的安全设计方案,从而有效地减少容器面临的风险和威胁。
首先,一个重要的安全设计方案是使用eBPF(扩展的Berkeley分组过滤器)对Container容器进行安全分析。eBPF是一个高效的可编程内核扩展,它允许用户在内核空间中编写和执行安全策略,从而实现对容器的细粒度安全控制。通过使用eBPF,可以在容器级别设置规则,以检测和阻止潜在的恶意行为,从而提高容器的安全性。
其次,为了进一步加强容器的安全性,可以采用Secure Namespaced Kernel Audit for Containers的安全设计方案。这个方案利用了容器的命名空间机制,通过创建独立的内核审计日志来追踪和监控容器中所发生的安全事件。这样一来,即使容器被攻击或者受到威胁,也能够及时发现并采取相应的措施,从而保护容器中的数据和敏感信息。
此外,还可以结合使用容器安全策略和网络安全策略,创建一个综合性的容器安全设计方案。容器安全策略可以包括限制容器的权限和资源使用、实施强制访问控制等措施,从而防止潜在的恶意行为。而网络安全策略则可以包括连接到容器的网络连接的安全控制和监控,以及检测和阻止来自外部网络的恶意流量。
为了进一步提高容器的安全性,还可以采用持续监控和自动化应急响应的安全设计方案。通过实时监控和分析容器的日志和指标数据,可以及时发现和应对容器中的异常行为和安全事件。并且可以使用自动化工具和技术来快速响应安全事件,从而减少潜在的损失和影响。
最后,容器安全设计方案还应考虑到容器的生命周期管理。这包括容器的创建、部署、更新和销毁等过程中的安全注意事项和措施。通过采用合适的安全策略和工具,可以确保容器在不同阶段都能够保持良好的安全性,并且避免容器生命周期管理过程中的安全漏洞和风险。
综上所述,Container容器安全设计方案是确保容器安全的关键措施。通过使用eBPF进行安全分析、采用Secure Namespaced Kernel Audit for Containers方案、结合容器安全策略和网络安全策略、持续监控和自动化应急响应、以及考虑容器的生命周期管理等方面的安全设计,可以有效地提高容器的安全性,并保护容器中的数据和敏感信息。这些安全设计方案的应用和实施,对于云计算领域的发展和应用至关重要。
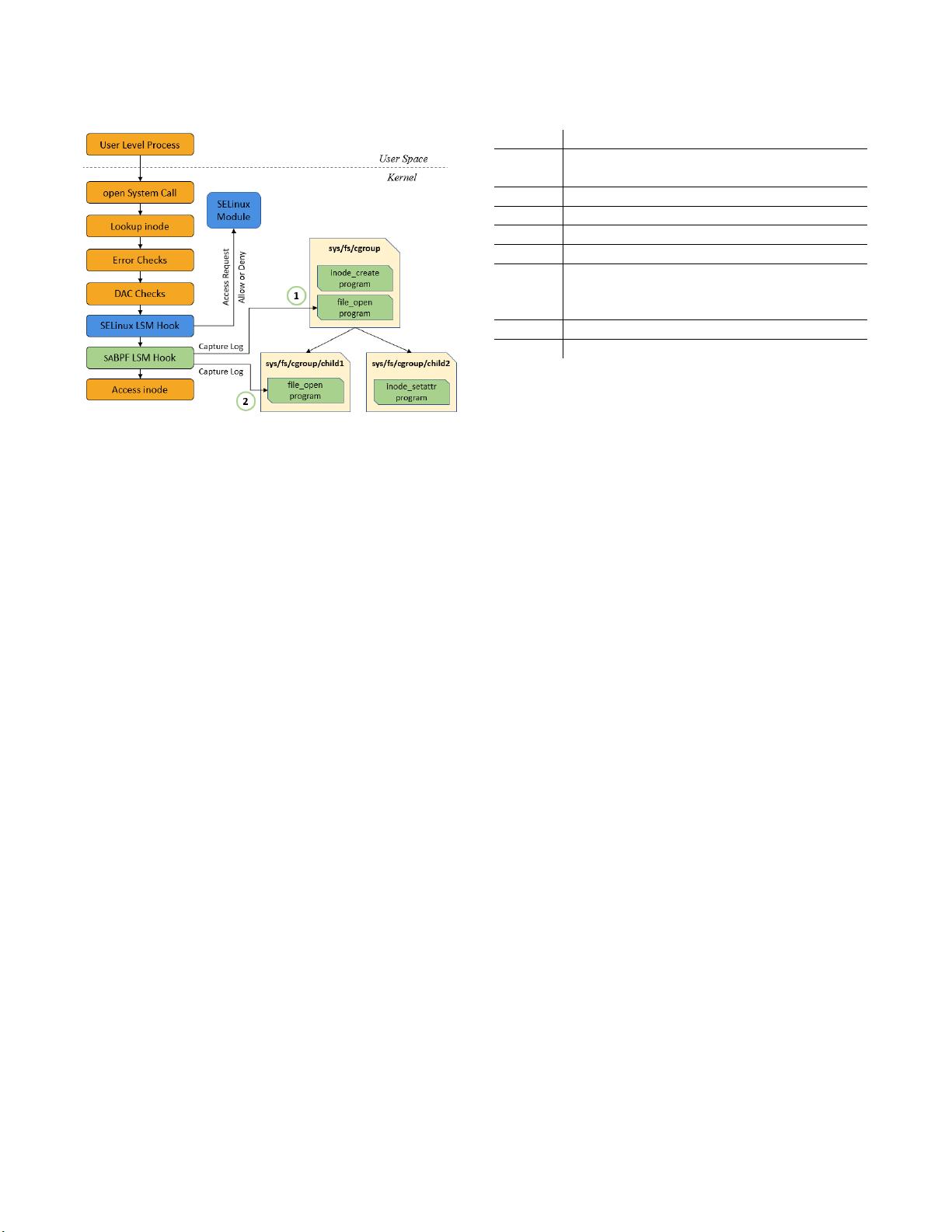
Secure Namespaced Kernel Audit for Containers SoCC ’21, November 1–4, 2021, Seale, WA, USA
Figure 2: LSM hook architecture [
46
]. The green blocks
are sp ecic to saBPF, which is describ ed in § 3.
1
○
shows
programs attached to the root cgroup;
2
○
shows two
programs attached to the
child1
and
child2
cgroup
respectively.
of mandatory access control scheme [
56
]. As a reference mon-
itor, LSM has also been adapted to perform secure kernel log-
ging, which provides stronger completeness and faithfulness
guarantees than traditional audit systems [
17
,
51
,
54
]. For
example, prior research has veried that LSM hooks capture
all meaningful interactions between kernel objects [
22
,
36
]
and that information ow within the kernel can be observed
by at least one LSM hook [
27
], which is necessary to achieve
completeness.
The LSM framework does not use system call interposi-
tion as older systems did. Syscall interposition is susceptible
to concurrency vulnerabilities, which in turn lead to time-
of-check-to-time-of-use (TOCTTOU) attacks that result in
discrepancies between the events as seen by the security
mechanism and the system call logic [
66
,
67
]. This is why
solutions such as kprobe-BPF, while useful for performance
analysis, are not appropriate to build security tools. Instead,
LSM’s reference-monitor design ensures that the relevant
kernel states and objects are immutable when a hook is
triggered, which is necessary to achieve faithfulness. LSM-
BPF [
57
] is a recent extension to the eBPF framework that
provides a more secure mechanism to implement security
functionalities on LSM hooks.
2.3 Namespaces in Linux
A namespace in the Linux kernel is an abstract environment
in which processes within the namespace appear to own an
independent instance of system resources. Changes to those
Name Description
cgroup
Allocate system resource (e.g., CPU, memory,
and networking)
ipc Isolate inter-process communications
network Virtualize the network stack
mount Control mount points
process Provide independent process IDs
user
Provide independent user IDs and group IDs,
and give privileges (or capabilities) associated
with those IDs within other namespaces
UTS Change host and domain names
Time See dierent system times
Table 1: Summary of Linux namespaces.
resources are not visible to processes outside the namespace.
We summarize available namespaces in Linux in Table 1.
One prominent use of namespaces is to create contain-
ers. For example, an application in a Docker container runs
within its own set of namespaces. Kubernetes “pods” contain
one or more containers so that they share namespaces (and
therefore system resources). Kubernetes makes it appear to
applications within a pod that they own a machine of their
own (Fig. 3).
saBPF modies the kernel to enable per-container audit-
ing, selectively invoking eBPF programs on LSM hooks based
on
cgroup
membership (§ 3.1).
cgroup
isolates processes’
resource usage in a hierarchical fashion, with a child group
having additional restrictions to those of its parent. Since
cgroup
v2 [
35
], this hierarchy is system-wide, and all pro-
cesses initially belong to the root
cgroup
. In a Kubernetes
pod, for example, containers can be organized in a hierarchi-
cal structure and assigned various
cgroup
namespaces to set
up further restrictions. Certain types of eBPF programs, such
as the ones that are socket-related, can already be attached
to
cgroup
s (e.g.,
BPF_PROG_TYPE_CGROUP_SKB
). This allows,
for example, a packet ltering program to apply network
lters to sockets of all processes within a particular con-
tainer. saBPF makes it possible to attach eBPF programs at
the intersection of
cgroup
s and LSM hooks (§ 3.1) for audit
purpose and beyond (§ 4).
3 SABPF: EXTENDING THE EBPF
FRAMEWORK
saBPF extends the eBPF framework to support secure ker-
nel auditing in a containerized environment. Our design
is minimally invasive, reusing existing components in the
framework as much as possible and extending only what
we deemed to be necessary. This is a conscious decision
made to achieve two objectives: 1) by adhering closely to the
剩余14页未读,继续阅读
2022-05-21 上传
2011-08-05 上传
157 浏览量
191 浏览量
2024-11-27 上传
2024-11-26 上传
156 浏览量
115 浏览量
187 浏览量

芯光未来
- 粉丝: 2223
- 资源: 19
 我的内容管理
展开
我的内容管理
展开







最新资源
- neo4j-community-4.x-unix.tar.gz and neo4j-community-4.x-windows.zip
- django-user-test
- functoria-lua:用很多函子来构建Lua解释器
- Umpyre
- 阿登脚印
- 高斯白噪声matlab代码-DIPCA-EIV:此回购包含了动态迭代PCA的实现,该PCA提议用于识别输入和输出测量值被高斯白噪声破坏的系统
- SpringBoot+Dubbo+MyBatis代码生成器
- fqerpcur.zip_MATLAB聚类GUI
- pg_partman:PostgreSQL分区管理扩展
- 下一店
- Umbles
- 图像处理:用于D2L图像处理的基于聚合物的Web组件
- queryoptions-mongo:Go软件包,可帮助构建基于queryoptions的MongoDB驱动程序查询和选项
- Redis-MQ:基于Redis的快速,简洁,轻量级的注解式mq,可以与任何IOC框架无缝衔接
- 答题卡检测程序/霍夫变换
- FANUC二次开发文档
