推荐系统训练与部署标准化:Writeonce,runanywhere策略
版权申诉
113 浏览量
更新于2024-07-05
收藏 3.78MB PDF 举报
推荐系统是现代互联网服务中的关键组成部分,它通过分析用户的偏好和行为数据,为用户提供个性化的内容推荐。本篇文档《推荐系统中模型训练及使用流程的标准化(22页).pdf》详细探讨了推荐系统中的核心问题及其解决方案。
在模型训练过程中,主要痛点包括:
1. **特征管理和时效性**:如何快速搜集、处理和整合在线特征(如用户ID、点击记录、地理位置等),确保特征的一致性和实时更新。例如,天天快报的推荐系统依赖于热点要闻、个性化推荐和高清视频等不同模块的特征,但如何在短时间内集成新特征并保持性能稳定是一个挑战。
2. **离线与在线效果不匹配**:模型在离线验证阶段表现良好,但在实际线上应用时效果下滑。这可能涉及到特征选择、特征工程、模型调优以及异常用户处理等问题。解决办法可能包括采用Writeonce,runanywhere的策略,确保模型能在各种环境和网络条件下运行,同时关注模型的泛化能力和对异常情况的鲁棒性。
3. **模型迭代与部署效率**:如何迅速将新的研究论文模型转化为可执行的训练并上线,需要一个通用的模型输入格式和标准化的训练流程,包括特征配置、处理、样本筛选和模型训练。此外,对于新模型的效果监控和性能调整也是关键。
4. **刷量用户的影响**:应对刷量行为对模型的影响,需要建立有效的样本过滤机制,防止恶意数据对模型学习造成干扰。
文档中还提及了技术细节,如TensorFlow的计算图示例,展示了如何通过代码定义变量和运算。Writeonce,runanywhere的解决方案可能涉及使用统一的框架和数据格式,使得模型能在不同的硬件和环境(如不同的服务器、边缘设备)上无缝部署。
另外,特征配置及处理系统、特征监控和排序系统的流程图展示了推荐系统中的各个环节是如何协同工作的,包括特征数据的获取、预处理、模型构建以及结果的排序和呈现。
总结来说,这份文档提供了推荐系统模型训练和使用的标准化方法,涵盖了从数据采集、特征工程、模型训练到上线优化的全过程,帮助读者理解和解决在实际工作中遇到的各种问题。
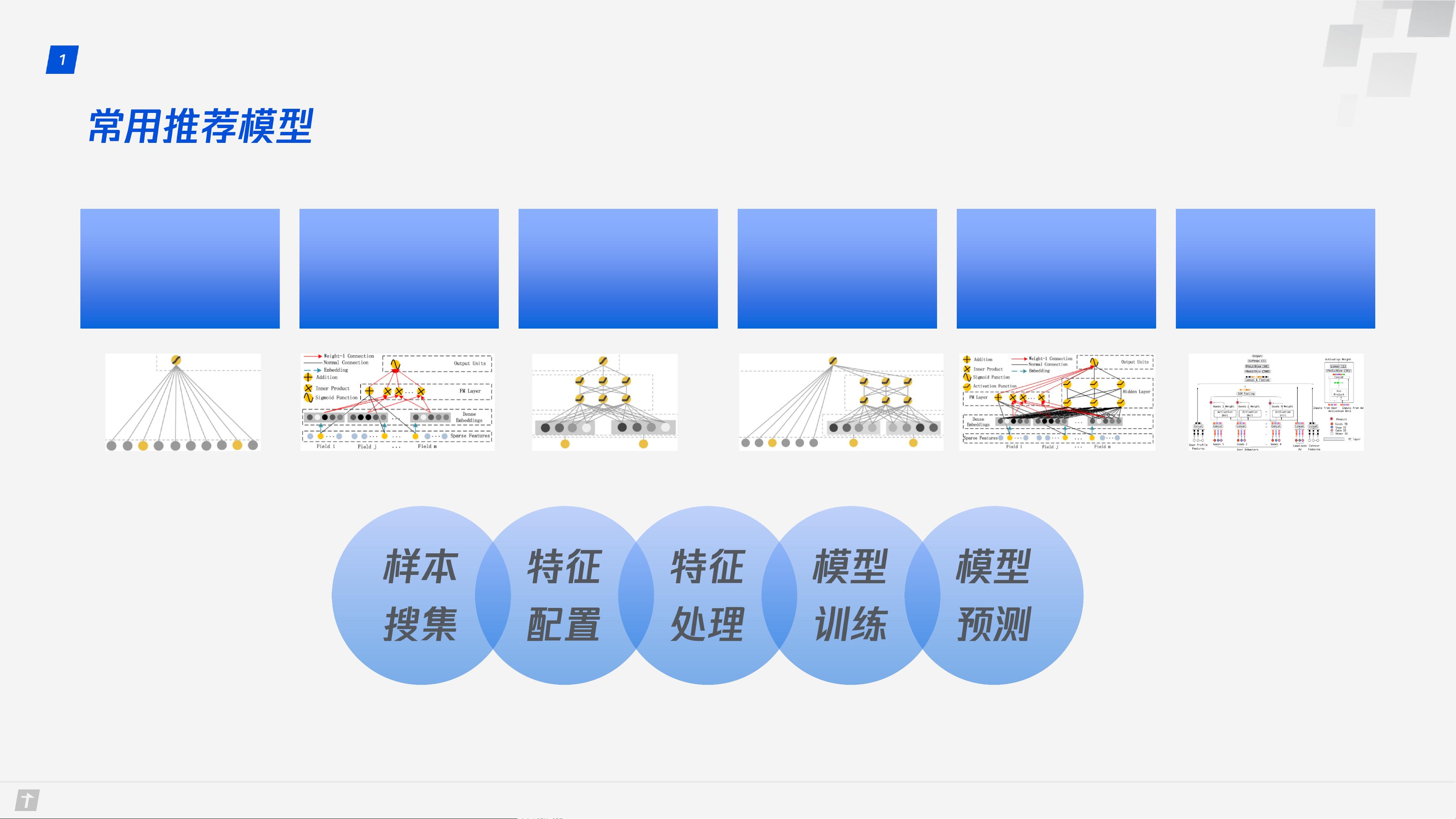
LR FM DNN W&D DeepFM DIN
推荐系统
剩余21页未读,继续阅读
2022-11-25 上传
2022-11-19 上传
2023-09-01 上传
2023-12-26 上传
2023-04-01 上传
2023-05-30 上传
2023-09-12 上传
2023-05-27 上传
2023-06-03 上传

行业报告
- 粉丝: 4
- 资源: 6234
 我的内容管理
展开
我的内容管理
展开







最新资源
- 解决Eclipse配置与导入Java工程常见问题
- 真空发生器:工作原理与抽吸性能分析
- 爱立信RBS6201开站流程详解
- 电脑开机声音解析:故障诊断指南
- JAVA实现贪吃蛇游戏
- 模糊神经网络实现与自学习能力探索
- PID型模糊神经网络控制器设计与学习算法
- 模糊神经网络在自适应PID控制器中的应用
- C++实现的学生成绩管理系统设计
- 802.1D STP 实现与优化:二层交换机中的生成树协议
- 解决Windows无法完成SD卡格式化的九种方法
- 软件测试方法:Beta与Alpha测试详解
- 软件测试周期详解:从需求分析到维护测试
- CMMI模型详解:软件企业能力提升的关键
- 移动Web开发框架选择:jQueryMobile、jQTouch、SenchaTouch对比
- Java程序设计试题与复习指南
