Hadoop伪分布式配置实战指南
需积分: 0 110 浏览量
更新于2024-08-04
1
收藏 2.44MB DOC 举报
"Hadoop安装部署实验材料"
在本次实验中,我们将学习如何在Linux环境下安装和配置Hadoop,包括理解不同安装模式、使用Vim编辑器以及处理Windows与Linux之间的文件复制粘贴。以下是详细的知识点说明:
1. **Hadoop安装方式**
- **单机模式**:这是Hadoop的默认模式,无需额外配置,所有服务都在同一个Java进程中运行,主要用于本地调试。
- **伪分布式模式**:在一个节点上模拟分布式环境,NameNode和DataNode在同一台机器上运行,以Java进程分开,适合学习和测试。
- **分布式模式**:在多节点集群上运行,提供真正的分布式存储和计算能力。
2. **Vim编辑器使用**
- **正常模式**:用于浏览文本,初始打开Vim即处于此模式,按`Esc`键可返回正常模式。
- **插入模式**:在正常模式下输入`i`进入,可以向文本中添加内容。
- **退出Vim**:在正常模式下,输入`:wq`保存并退出Vim。如果未修改,可以直接输入`:q`退出。
3. **Windows与Linux之间复制粘贴**
- 通过特定命令设置,允许在Windows主机和Linux虚拟机之间进行复制粘贴。
4. **实验平台要求**
- **操作系统**:推荐使用Ubuntu 16.04或18.04。
- **Hadoop版本**:实验使用的是3.1.3。
- **JDK版本**:要求为1.8。
5. **实验内容**
- **安装Vmware虚拟机**:提供运行Ubuntu系统的环境。
- **安装Ubuntu16.04**:作为实验的操作系统。
- **创建hadoop用户**:为Hadoop操作创建专门的用户。
- **更新apt**:安装Vim等必备软件包。
- **安装SSH**:用于远程访问和管理。
- **配置SSH无密码登陆**:简化登录流程,提高效率。
- **安装Java环境**:Hadoop运行需要Java支持。
- **安装Hadoop3.1.3**:下载并安装Hadoop。
- **Hadoop伪分布式配置**:设置环境变量,配置Hadoop的配置文件如`core-site.xml`、`hdfs-site.xml`、`mapred-site.xml`和`yarn-site.xml`,确保所有服务能够正确启动。
6. **实验步骤**
- 按照指导安装VMwareWorkstation,并创建新的虚拟机,选择Ubuntu 16.04镜像文件。
- 在虚拟机中进行必要的系统配置,如网络设置,以确保能访问外网下载软件包。
- 使用`sudo apt-get update`更新软件源,然后使用`sudo apt-get install vim`安装Vim。
- 安装SSH,配置SSH无密码登陆,这通常涉及生成SSH密钥对并将其添加到`authorized_keys`文件中。
- 安装Java开发工具包(JDK),设置`JAVA_HOME`环境变量。
- 下载Hadoop安装包,解压后配置Hadoop环境变量,如`HADOOP_HOME`,并修改配置文件以适应伪分布式设置。
- 启动Hadoop服务,包括NameNode、DataNode、YARN等,验证Hadoop是否成功运行。
通过这个实验,你将深入理解Hadoop的基础架构和操作,为后续的大数据处理和分析奠定基础。
(4)更新 apt(安装 vim)
(5)安装 SSH、配置 SSH 无密码登陆
(6) 安装 Java 环境
(7) 安装 Hadoop3.1.3
(8) Hadoop 伪分布式配置
5.实验步骤
1、安装 VMware Workstation(自行安装)
2、安装 Ubuntu16.04 作为系统环境(典型安装)
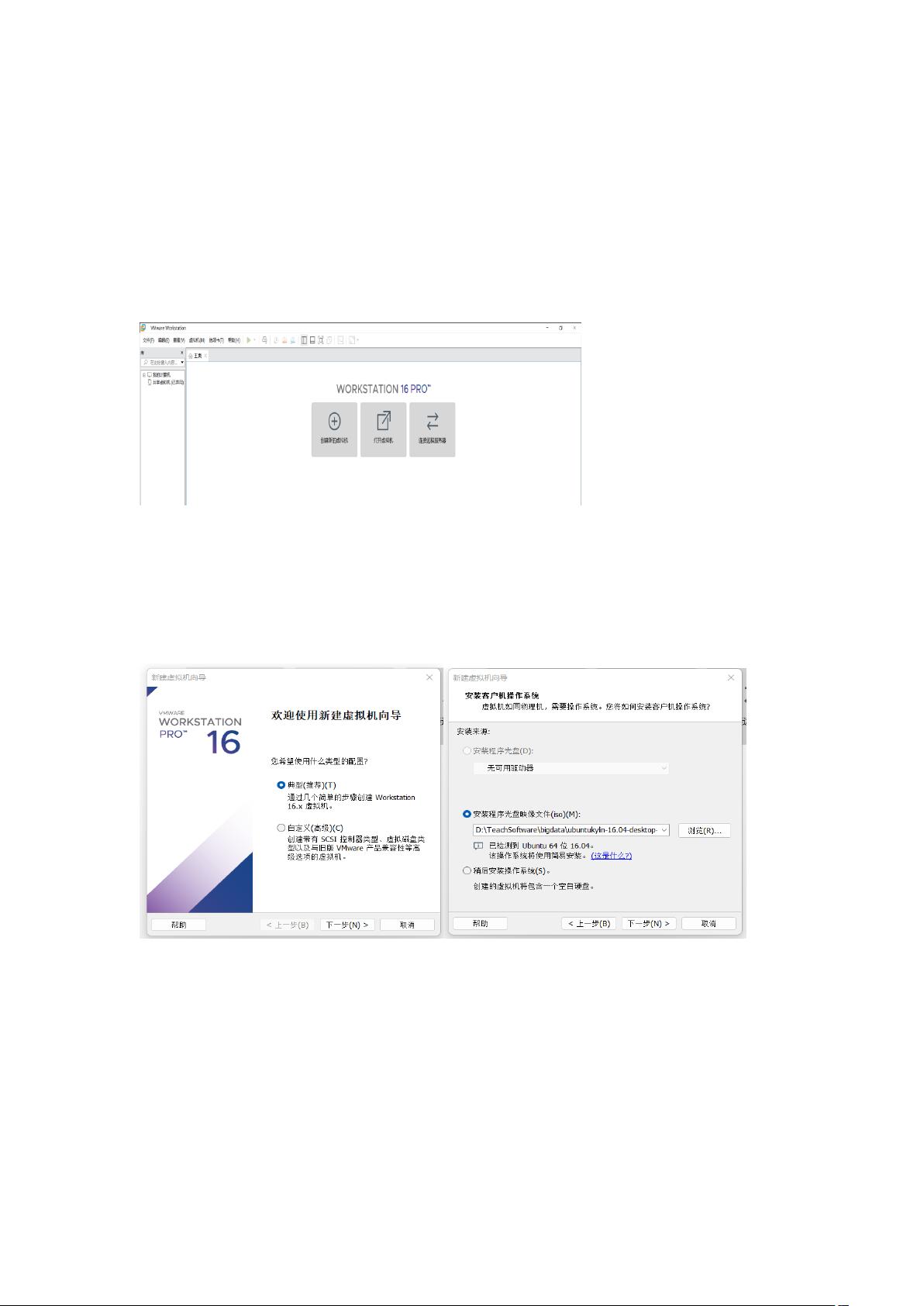
(1)打开文件,新建虚拟机,选择典型,之后下一步。(图 1)
(2)选择映像文件 ubuntukylin-16.04-desktop-amd64.iso,进行下一步。(图 2)
(3)进行个性化设置,进行下一步。(图 3)
用户名:hadoop
密码:hadoop
确认密码:hadoop
(4)命名虚拟机,进行下一步。(图 4)
剩余10页未读,继续阅读
2024-06-21 上传
2022-07-06 上传
2018-09-12 上传
2018-06-20 上传
2022-03-20 上传
2018-03-18 上传
2018-09-05 上传
点击了解资源详情
点击了解资源详情

心态v
- 粉丝: 30
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- algorithm-study:算法研究
- Projeto_TST_API:API架构
- WordPress主题:Instive v1.1.9保险主题2022年最新版.zip
- JAVA_JDK_API_1_6_zh_CN.rar
- Jasper-report-maven-plugin:快速的Jasper Report Maven插件
- sagehand:SageHand 是一种网络和移动工具,可帮助音乐节舞台工作人员进行舞台安排。 它会变得更多 - 所以请继续关注!
- 酷宝贝钢琴-项目开发
- rethinking_dsc:项目针对高度不平衡的数据集测试一些有关DSC损失的玩具示例
- 压缩识别
- 行业数据-20年7月份快手短视频用户月份收入分布.rar
- 西门子PLC工程实例源码第522期:用314cPWM调制功能驱动伺服的程序.rar
- master-page-php:PHP 中的母版页模板
- RousseauYlan_2_01042021
- fileswim-home
- Ozark-Guides:Øzark的两个有用指南
- DIY继电器模块-项目开发
