SparkCore Scala单词计数实验:李志毅
需积分: 0 176 浏览量
更新于2024-08-05
收藏 941KB PDF 举报
"该资源是关于2021年4月17日李志毅同学进行的一次SparkCore Scala单词计数实验,主要涉及Hadoop集群的部署、Scala程序的编写与运行、以及Spark任务的提交。实验中,李志毅同学在华为云上配置了三台云主机作为Hadoop集群的节点,并实现了节点间的互信。在本地使用Maven构建Scala项目,完成后将程序打包成jar文件,通过spark-submit命令在集群上执行,实现了单词计数的功能。在实验过程中遇到了节点互信配置问题,但最终得到了解决。"
在本次实验中,李志毅同学首先在华为云上购买并配置了三台云服务器,分别作为Hadoop集群的master、slave01和slave02节点。每台服务器都配置了Java环境,且进行了三节点之间的互信设置。在Hadoop集群部署成功后,通过Jps命令验证了各个节点上的Java进程状态,确保了Hadoop服务的正常运行。
接着,李志毅在本地Windows环境中安装了JDK 1.8和Scala 2.13.5,创建了一个Maven项目。他修改了pom.xml文件,编写了用于单词计数的Scala程序。这个程序会以空格为分隔符,统计文本中每个单词出现的次数。完成后,他将程序打包成jar文件,准备在云端执行。
为了运行Scala程序,李志毅在云服务器的master节点上使用了spark-submit命令。这个命令将Scala程序提交到已搭建好的Spark on Yarn环境中执行,从而实现了Spark的任务调度和计算。实验结果显示,Spark程序成功完成了单词计数任务。
在实验过程中,李志毅遇到了一个主要问题——节点互信配置不成功。当尝试通过ssh无密码登录其他节点时,系统提示需要输入密码。经过错误分析,他发现各节点间的身份验证存在问题。为了解决这个问题,他可能需要重新配置SSH密钥对,确保每个节点都能无密码登录其他节点。通常这包括在每个节点上生成SSH密钥对,然后将公钥分发到其他节点的authorized_keys文件中。
这次实验涵盖了Hadoop集群的部署、Scala编程、Spark任务提交等关键知识点,同时锻炼了问题排查和解决能力。对于学习分布式计算和大数据处理的学生来说,这样的实践是非常有价值的。
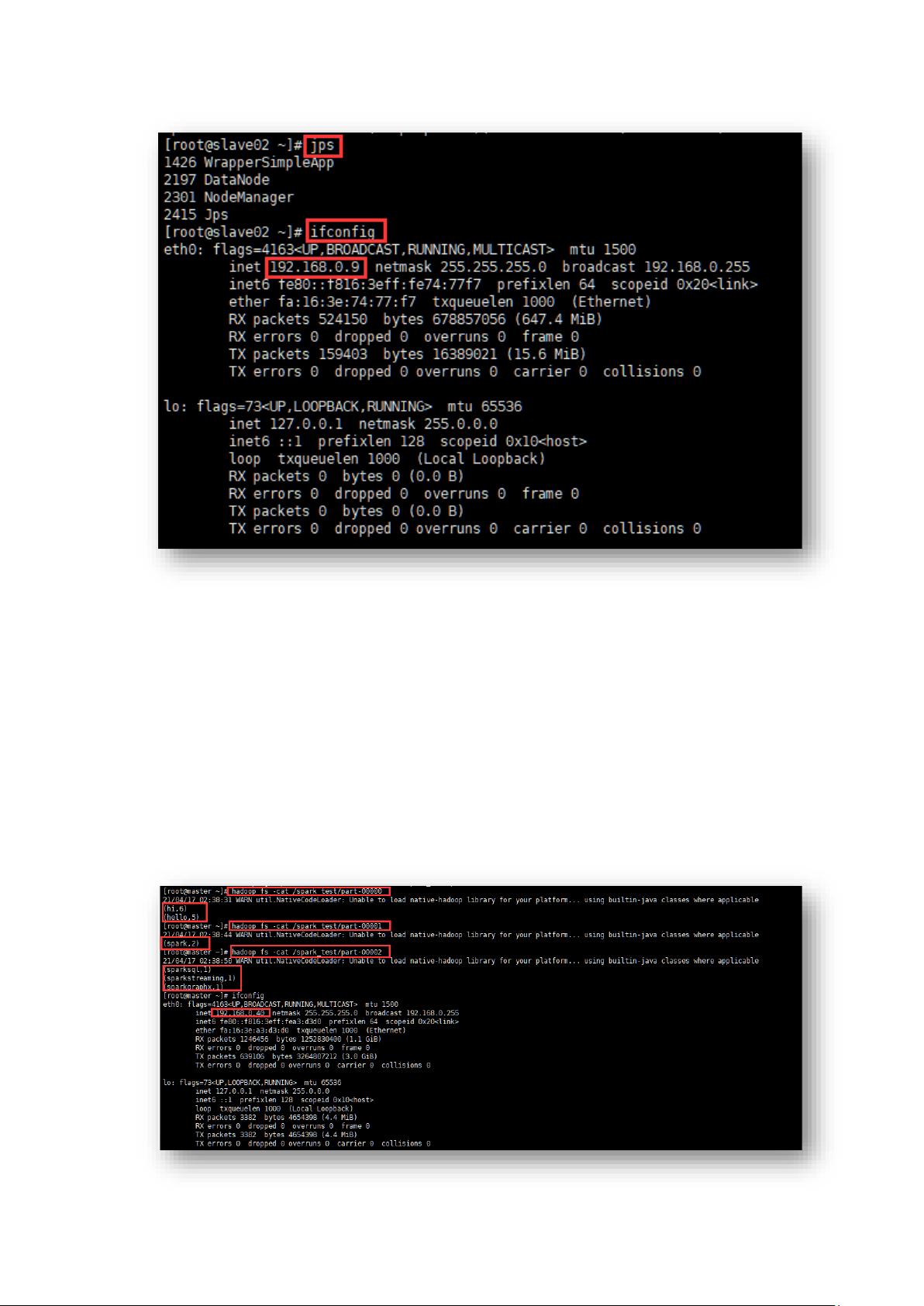
图 31 slave02 节点执行 jps 效果
可以看到,Hadoop 集群部署完成并启动成功
本地编写 scala 程序并导出 jar 包,在主节点使用 spark-submit 命
令运行后可以得到如下的截图 73:
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-08-08 上传
2022-08-08 上传
2022-08-08 上传
2022-08-03 上传
2022-08-08 上传
2022-08-08 上传

柏傅美
- 粉丝: 32
- 资源: 325
 我的内容管理
展开
我的内容管理
展开







最新资源
- laravel-postgres-broadcast-driver:Laravel的Postgresql广播事件驱动程序
- 蓝色背景的商务剪影下载PPT模板
- LGames:好看又让人上瘾的开源游戏-开源
- Switchboard 4 Cyber-Abundance-crx插件
- Geofence_test
- webpack-4:基于webpack-4
- karkinos-patient
- New tab tasks-crx插件
- springboot034基于Springboot在线商城系统设计与开发毕业源码案例设计
- 情感检测系统:人脸图像情感检测系统-matlab开发
- Python库 | requirementslib-1.1.0-py2.py3-none-any.whl
- 作品集
- 精美中国风下载PPT模板
- association_validations
- 我们可以! 开源DaST与MVC和WebForms竞争
- 塔蒂尼美尼基尼
