Ubuntu 16.04上Hadoop 3.0.0安装全攻略
下载需积分: 9 | PDF格式 | 966KB |
更新于2024-09-08
| 73 浏览量 | 举报
"Hadoop在Linux环境下的创建详细步骤"
在Hadoop的世界中,初学者往往需要面对的第一个挑战就是如何在Linux系统上搭建Hadoop环境。本文将详细介绍在Ubuntu 16.04 Server上安装Hadoop 3.0.0-alpha4的全过程,帮助你快速入门。
首先,确保你的系统已经安装了Java环境,这里推荐的是OpenJDK 1.8.0_131。Java是Hadoop运行的基础,因此在开始Hadoop的安装前,请先安装Java并设置好JAVA_HOME环境变量:
```bash
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64/jre
```
接下来,通过以下命令下载Hadoop 3.0.0-alpha4的tarball文件:
```bash
wget http://mirror.metrocast.net/apache/hadoop/common/hadoop-3.0.0-alpha4/hadoop-3.0.0-alpha4.tar.gz
```
然后解压下载的文件,并将其添加到系统路径中:
```bash
tar xvf hadoop-3.0.0-alpha4.tar.gz
export PATH=$PATH:/path/to/your/hadoop-installation/bin
```
为了在本地模式下运行Hadoop,你需要配置Hadoop的环境变量。打开`etc/hadoop/hadoop-env.sh`文件,并更新`HADOOP_OPTS`,添加Java路径:
```bash
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native $HADOOP_OPTS"
```
接下来,你需要创建一个输入目录并复制配置文件到其中,这是运行示例任务的必要步骤:
```bash
mkdir input
cp etc/hadoop/*.xml input
```
现在你可以运行Hadoop自带的WordCount示例程序来检查环境是否配置正确:
```bash
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0-alpha4.jar wordcount input output
```
运行完成后,查看`output`目录中的结果,确认WordCount程序是否成功执行:
```bash
cat output/*
```
当本地模式运行无误后,可以进一步配置Hadoop的伪分布式模式。你需要编辑`core-site.xml`和`hdfs-site.xml`文件,设置相关配置。例如,在`core-site.xml`中添加安全配置,而在`hdfs-site.xml`中配置数据块复制数等参数。
此外,为了在伪分布式模式下运行Hadoop,你需要启用SSH无密码登录。使用`ssh-keygen`生成密钥对,然后将公钥复制到所有节点(对于伪分布式模式,节点即为本机):
```bash
ssh-keygen
ssh-copy-id localhost
```
至此,你已成功完成了在Ubuntu 16.04 Server上搭建Hadoop 3.0.0-alpha4的基本步骤。接下来,你可以继续学习如何启动Hadoop服务,提交更多MapReduce任务,以及如何管理和监控集群状态,逐步深入Hadoop的世界。记住,实践是检验真理的唯一标准,多动手操作,才能更好地理解和掌握Hadoop。
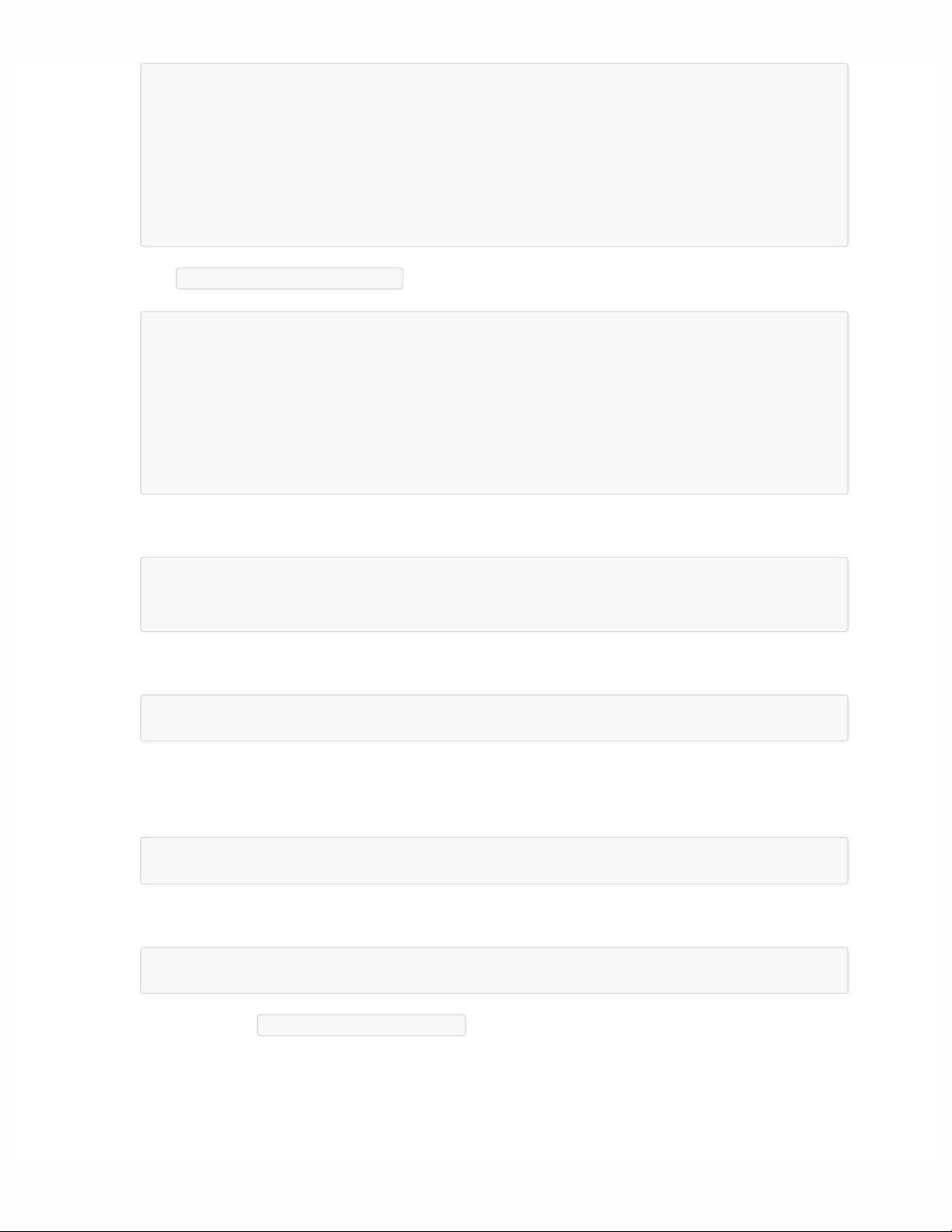
2. ᯈᗝ etc/hadoop/hdfs-site.xml ғ
3. ᯈᗝ ssh عᎱጭ୯ғ
4. ၥᦶ ssh عᎱጭ୯ғ
ᝑဌํᐏᬌفᎱ҅ڞᯈᗝ౮ۑ
5. ໒ୗ۸ namenodeғ
6. ސۖ namenode datanodeғ
౮ۑݸݢզ᭗ᬦ http://localhost:9870/ ᦢᳯ namenode ጱ web ኴᶎ
7. ڠୌ hdfs Ӿጱፓ୯ᕮғ
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
ssh-keygen
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
ssh localhost
bin/hdfs namenode -format
sbin/start-dfs.sh
剩余11页未读,继续阅读
相关推荐




wfs1874
- 粉丝: 180
- 资源: 20
 我的内容管理
展开
我的内容管理
展开







