Kafka:LinkedIn的日志处理利器与分布式消息队列架构详解
需积分: 16 146 浏览量
更新于2024-09-12
1
收藏 398KB DOC 举报
Kafka是一个由LinkedIn开发并开源的分布式消息系统,专为处理大量日志数据而设计,尤其适用于那些对实时性要求不高,但希望具有可扩展性和容错性的场景。它最初是为了处理LinkedIn内部的数据流,如用户行为日志和系统运行日志,这些数据量巨大且不需要立即消费。
Kafka的核心特性包括:
1. **分布式架构**:
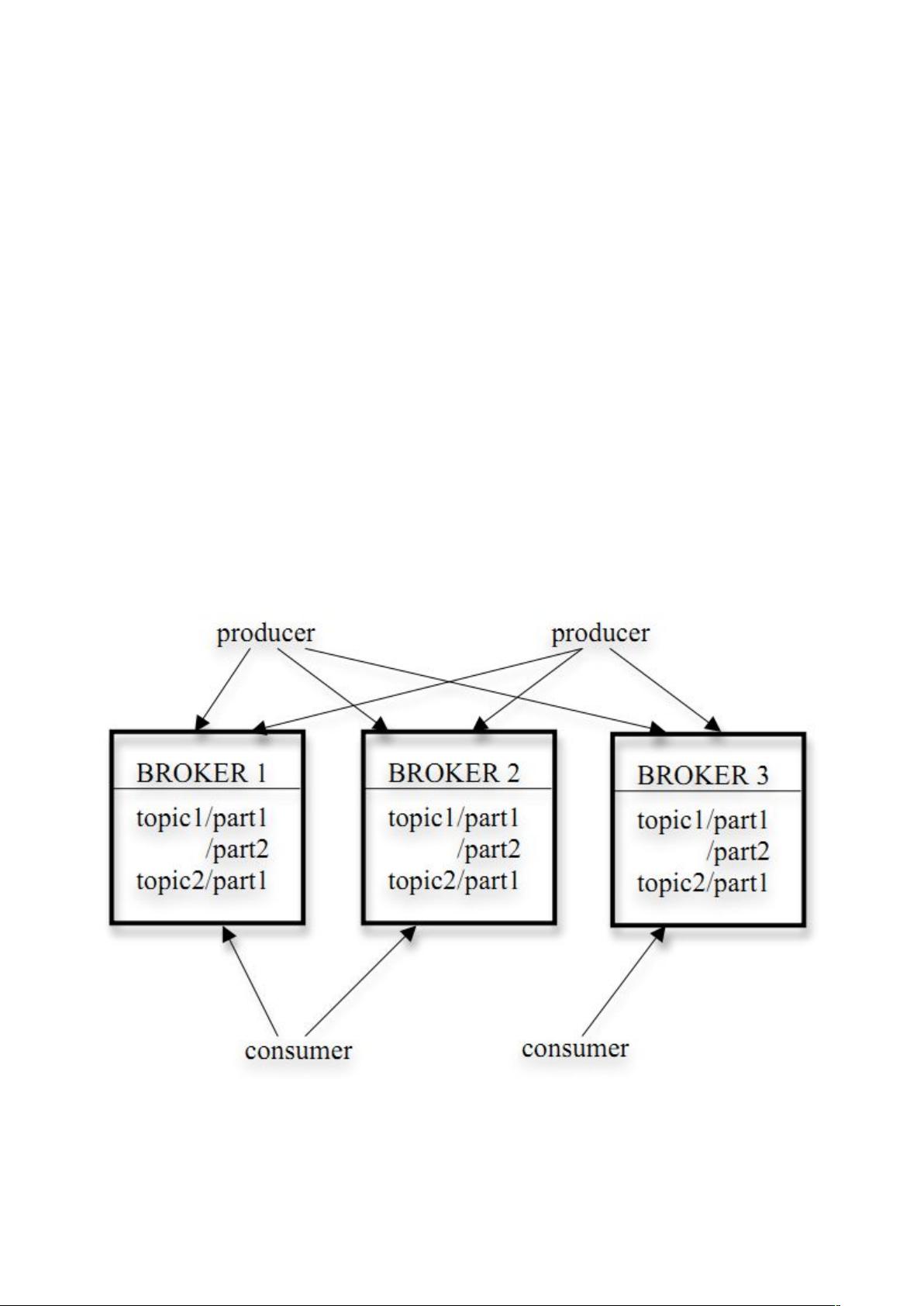
Kafka基于分区(partition)和主题(topic)的设计。每个主题可以有多个分区,每个分区是一个独立的、有序的消息序列,确保了数据的一致性和顺序。发布者(Producer)将消息发送到特定的主题,消息会被自动均衡地分布在各个分区中,从而实现水平扩展。
2. **消息持久化**:
Kafka通过在内存中维护索引(index)跟踪每个分区的最新消息位置,然后定期将数据(segment)刷写到磁盘,保证数据的持久性。当消息达到预设的阈值或者过期后,才会被确认为已发布。这样,即使某个分区发生故障,仍然可以通过其他副本恢复。
3. **发布与订阅模型**:
发布者使用Kafka客户端将消息批量发送到主题,消息集(message set)中可以包含多条消息。订阅者(Subscriber,消费者)则指定他们感兴趣的主题和分区,以便接收消息。Kafka的这种模型支持实时消费和离线处理,因为它允许消息在网络中暂存,直到消费者准备好接收。
4. **可扩展性**:
Kafka通过增加分区和增加broker(节点)来应对增长的数据量。当分区满时,新的消息会被分配到新的分区,而旧的分区会被拆分成新的分区以保持数据吞吐量。
5. **可靠性**:
Kafka虽然支持高可用性,但可以根据业务需求调整可靠性级别,通过牺牲部分可靠性来换取更高的性能。这对于LinkedIn这类对数据实时性要求不严格的公司非常合适。
总结来说,Kafka作为一款分布式消息系统,凭借其高效的消息处理能力、强大的分区管理和可扩展性,成为大数据和云计算环境中处理大规模实时和离线日志的理想选择。其核心概念和设计模式对于理解现代分布式系统如何处理数据流至关重要。
Kafka[1]是 linkedin 用于日志处理的分布式消息队列,linkedin 的日志数据
容量大,但对可靠性要求不高,其日志数据主要包括用户行为(登录、浏览、
点击、分享、喜欢)以及系统运行日志(CPU、内存、磁盘、网络、系统及进
程状态)。
当前很多的消息队列服务提供可靠交付保证,并默认是即时消费(不适合离
线)。高可靠交付对 linkedin 的日志不是必须的,故可通过降低可靠性来提高
性能,同时通过构建分布式的集群,允许消息在系统中累积,使得 kafka 同时
支持离线和在线日志处理。
注:本文中发布者(publisher)与生产者(producer)可以互换,订阅者
(subscriber)与消费者(consumer)可以互换。
Kafka 的架构如下图所示:
Kafka 存储策略
下载后可阅读完整内容,剩余5页未读,立即下载
2015-03-12 上传
2015-02-05 上传
2018-02-02 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

nicee
- 粉丝: 1
- 资源: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- ExtJS 2.0 入门教程与开发指南
- 基于TMS320F2812的能量回馈调速系统设计
- SIP协议详解:RFC3261与即时消息RFC3428
- DM642与CMOS图像传感器接口设计与实现
- Windows Embedded CE6.0安装与开发环境搭建指南
- Eclipse插件开发入门与实践指南
- IEEE 802.16-2004标准详解:固定无线宽带WiMax技术
- AIX平台上的数据库性能优化实战
- ESXi 4.1全面配置教程:从网络到安全与实用工具详解
- VMware ESXi Installable与vCenter Server 4.1 安装步骤详解
- TI MSP430超低功耗单片机选型与应用指南
- DOS环境下的DEBUG调试工具详细指南
- VMware vCenter Converter 4.2 安装与管理实战指南
- HP QTP与QC结合构建业务组件自动化测试框架
- JsEclipse安装配置全攻略
- Daubechies小波构造及MATLAB实现
