
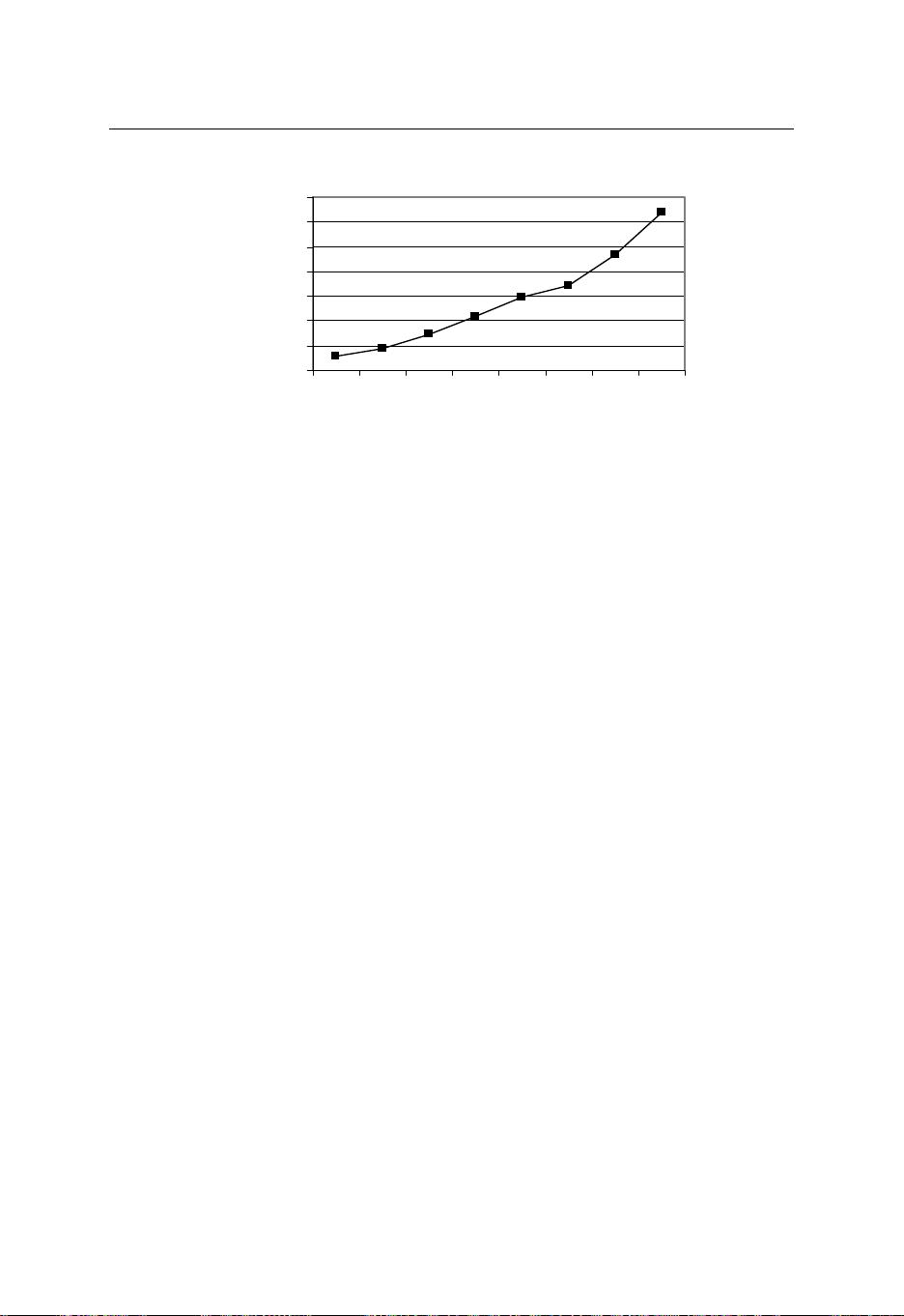
2 1.1. MOTIVATION
0
50
100
150
200
250
300
350
1998 1999 2000 2001 2002 2003 2004 2005
Year
Number of hosts
(millions)
Figure 1.1: Number of hosts on the Internet advertised in domain name servers
• A malicious (or just curious) person/organisation obtains information on
the vulnerability
• An attack tool is developed (requiring a considerable amount of technical
insight)
• The attack tool is released and used by many (requiring little actual knowl-
edge)
• The software vendor obtains information on the vulnerability
• A patch for the software is developed by the software vendor
• The patch is released and applied to a subset of systems removing the vul-
nerability from those systems.
The order of these events is very significant. The listed order is the most
unfortunate since the attack tool is released before the patch is applied to end user
systems resulting in a potentially very large number of compromised systems.
Unfortunately the time from public discovery of a new vulnerability to the release
of an attack tool is decreasing and is currently in the order of days. This means that
the time window for developing and applying patches is becoming very short. One
example is the Zotob-A worm [47] and its variants. On Tuesday 9th August 2005
Microsoft released a patch and less than three days [39] later exploit code was
publicly available on the Internet. In four days (Saturday 13th) worms exploiting
the vulnerability were spreading.




剩余166页未读,继续阅读

zztq
- 粉丝: 7
- 资源: 53
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


