Kafka原理详解:版本差异、安装与基本操作
需积分: 11 45 浏览量
更新于2024-09-07
收藏 321KB DOCX 举报
Kafka是一种分布式流处理平台,主要用于构建实时数据管道和构建高度可扩展的事件驱动系统。本文档将深入探讨Kafka的核心原理和关键概念。
1. **Kafka版本差异**:
Kafka的版本更新主要涉及API、性能优化、新特性以及兼容性改进。了解不同版本之间的变化有助于选择合适的版本,并确保应用程序能够平滑地升级或迁移。版本差异可能会影响生产者和消费者的交互方式,例如消息序列化/反序列化格式、配置参数的调整等。
2. **安装Kafka**:
安装Kafka通常涉及到下载源代码包(如.tar.gz文件),解压后进入`config`目录,编辑`server.properties`文件,设置核心参数,如`broker.id`(标识节点)和`zookeeper.connect`(连接Zookeeper服务器)。然后可以通过`kafka-server-start.sh`命令启动服务,并能使用`kafka-server-stop.sh`停止服务。
3. **Zookeeper的角色**:
Zookeeper在Kafka中扮演着分布式配置维护和协调的角色。它负责维护集群状态信息,如`controller`(集群控制器)、`brokers`列表、主题(`topic`)分区(`partition`)信息、消费者和生产者的状态等。Zookeeper通过心跳机制确保节点的健康并同步数据。
4. **Topic与Partition**:
Topic是Kafka的核心概念,用于组织消息。每个topic可以划分为多个分区,分区的数量可以预先设定,消息根据key的哈希值被路由到特定分区,从而保证了基于key的消息顺序。每个分区都有一个唯一的offset,用于记录消息的顺序。Kafka保证同一分区内的消息有序,但不同分区间的消息无序。
5. **消息模型**:
Kafka的消息由键值对组成,key和value都是字节数组。key用于路由消息至正确的分区,可以是null。生产者支持批量发送消息,并在发送前进行压缩,以提高网络效率。
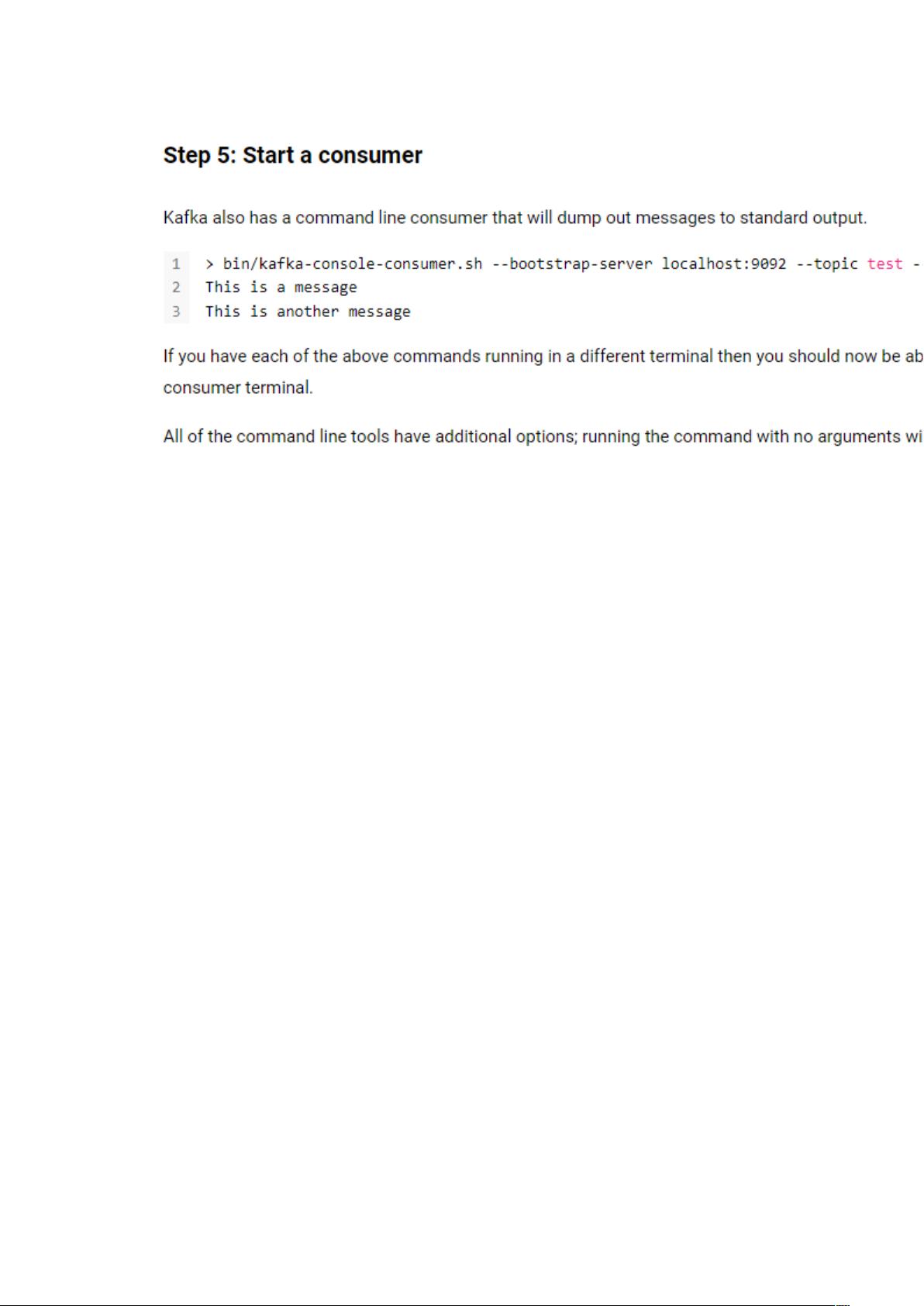
6. **基本操作**:
Kafka提供了快速入门指南,包括如何创建主题、设置消费者和生产者配置,以及监控和管理集群。这些操作是开发和运维Kafka系统的基础。
7. **实现细节**:
Kafka使用文件系统存储分区数据,分区文件在`kafka-log`目录下,每个分区的名称包含主题名和分区号。Kafka使用日志模式来持久化消息,提供高吞吐量和可靠性,同时支持多副本以增强容错性。
总结来说,理解Kafka的核心原理包括其架构、消息模型、分区机制以及与Zookeeper的集成。掌握这些知识对于开发和运维高效、可靠的实时数据处理系统至关重要。通过学习和实践,开发者可以更好地利用Kafka构建实时数据管道,满足现代应用的需求。
+#$$+$-,$
34-
kafka 的实现细节
消息
消息是 中最基本的数据单元。消息由一串字节构成,
其中主要由 5 和 - 构成,5 和 - 也都是 5
数组。5 的主要作用是根据一定的策略,将消息路由到指
定的分区中,这样就可以保证包含同一 5 的消息全部写入
到同一个分区中,5 可以是 -。为了提高网络的存储和
利用率,生产者会批量发送消息到 ,并在发送之前对
剩余13页未读,继续阅读
2043 浏览量
127 浏览量
139 浏览量
130 浏览量
108 浏览量
545 浏览量
120 浏览量
134 浏览量

IT小能手
- 粉丝: 0
- 资源: 10
 我的内容管理
展开
我的内容管理
展开







最新资源
- Test Director使用手册
- 献给热爱嵌入式系统的初学者们
- nagios安装资料
- sql-server-2008-transact-sql-recipes-a-problem-solution-approach-recipes-a-problem-solution-approach
- C语言常见问题集 pdf
- 一个软件测试的理论书籍:软件测试方法论
- 小而精&幽默的软件工程思想
- proftpd + mysql + quota配置完全指南
- Essential.ActionScript.3.0.pdf
- 令人感叹的10个非主流操作系统
- surfer8初学者中文参考手册
- nagios安装参考
- C、C++算法实例包含各种算法
- B2C技能训练详细讲解
- Windows+CE下操作GPIO的方法(以ARM+S3C2410为例)
- 关于usb和u盘开发资料
