Pandas数据替换:replace函数详细教程
194 浏览量
更新于2024-08-31
1
收藏 237KB PDF 举报
本文详细介绍了Pandas库中的replace()函数,用于高效地批量替换数据。replace()函数可以帮助我们快速地更新DataFrame中的特定值,无论是单个值还是多个值,甚至可以结合正则表达式进行复杂替换。
1. **全部或部分替换**
- `df.replace(to_replace, value)` 是replace函数的基本用法,`to_replace`参数是要替换的值,`value`是替换后的新值。例如,将DataFrame中所有出现的"南岸"替换为"城区"。
- 如果希望直接修改原数据,需设置`inplace=True`。例如,`df.replace('南岸', '城区', inplace=True)`将直接在原始DataFrame上进行替换。
2. **替换指定列的值**
- 可以通过字典形式指定要替换的多个值,如`df.replace({'列名': {原值1: 新值1, 原值2: 新值2}})`。
- 也可以使用列表形式替换多个值,如`df.replace([原值1, 原值2], [新值1, 新值2])`。
- 若要仅替换单个列的某些值,结合使用字典和列名即可。
3. **正则表达式替换**
- 通过正则表达式,可以替换符合特定模式的所有值。例如,使用`df.replace(to_replace='[A-Z]', value='', regex=True)`,将替换掉所有大写字母。
- 注意,使用正则表达式时,必须设置`regex=True`,否则Pandas会按精确匹配处理。
- 要将替换应用于特定列,可指定列名,如`df['列名'].replace(..., regex=True, inplace=True)`。
4. **处理缺失值**
- 对于缺失值的替换,可以使用`fillna()`函数,它提供了更多的填充策略,如使用平均值、中位数等。
5. **提取部分数据**
- 当需要保留数据的一部分时,可以结合字符串方法进行操作,如`df['列名'] = df['列名'].str.extract('部分模式')`,这将提取字符串列中符合模式的部分。
在实际应用中,replace()函数非常灵活,可以根据具体需求组合使用各种选项,实现对数据的精确控制。它在数据分析过程中起到了关键的作用,特别是在数据清洗和预处理阶段,极大地提高了工作效率。通过熟练掌握replace()函数,可以更有效地处理和操纵大量数据。
Pandas替换及部分替换(替换及部分替换(replace)实现流程详解)实现流程详解
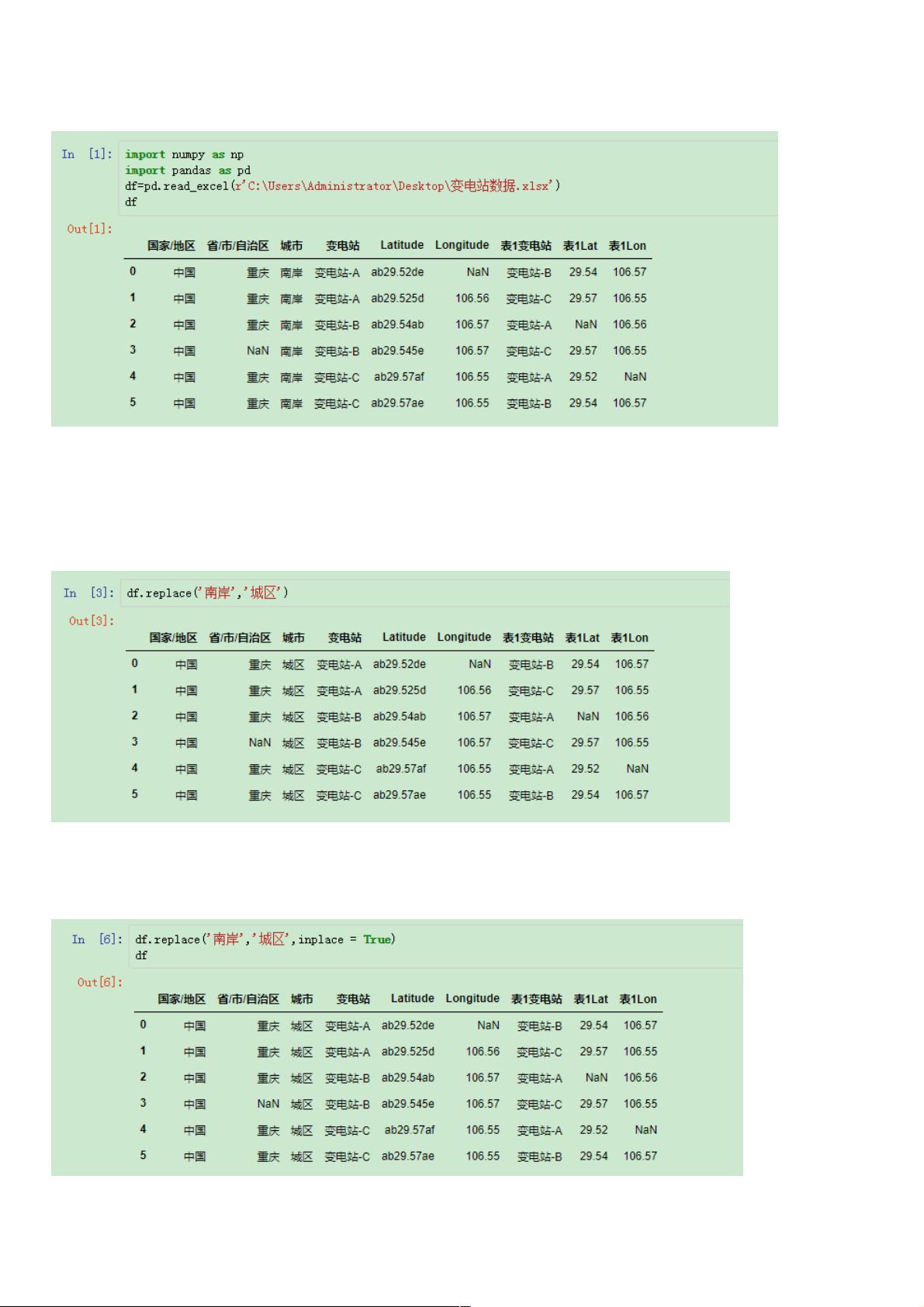
在处理数据的时候,很多时候会遇到批量替换的情况,如果一个一个去修改效率过低,也容易出错。replace()是很好的方法。
源数据
1、替换全部或者某一行
replace的基本结构是:df.replace(to_replace, value) 前面是需要替换的值,后面是替换后的值。
例如我们要将南岸改为城区:
将南岸改为城区
这样Python就会搜索整个DataFrame并将文档中所有的南岸替换成了城区(要注意这样的操作并没有改变文档的源数据,要
改变源数据需要使用inplace = True)。
使用inplace = True更改源数据
由于南岸只有城市一列具有相同值,使用起来比较方便。
下载后可阅读完整内容,剩余4页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-09-16 上传
2020-09-20 上传
2021-03-18 上传
2021-03-16 上传
2016-03-30 上传
2018-07-09 上传

weixin_38570459
- 粉丝: 3
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







