RAMBleed:利用Rowhammer漏洞进行内存读取攻击
需积分: 9 95 浏览量
更新于2024-07-17
收藏 1.41MB PDF 举报
"RAMBleed: Reading Bits in Memory Without Accessing Them,这份PDF文档是关于最新的RAMBleed漏洞的研究,它揭示了CPU内存中的一个安全问题,即使不直接访问也能读取内存中的数据。"
在现代计算机系统中,内存(RAM)是存储和处理数据的关键组件。RAMBleed是一种利用DRAM(动态随机存取内存)的Rowhammer漏洞的新攻击技术,该漏洞最初被发现可能导致内存中的比特位翻转,从而影响邻近行的数据。Rowhammer攻击通常被认为是通过重复访问同一行内存来引发相邻行的电荷泄露,进而导致比特翻转,这可能引发跨安全边界的故障攻击,如权限提升。
然而,RAMBleed的研究指出,这个漏洞远不止于此。之前普遍认为,如果攻击者能修改其私有内存,那么在自己的私有内存中触发比特翻转不会带来安全风险。但RAMBleed证明了这一假设是错误的。攻击者可以通过Rowhammer诱导的比特翻转作为读取侧信道,利用这些翻转与附近行数据之间的数据依赖关系,推断出那些原本不应被访问的比特值。
这项研究由来自密歇根大学、格拉茨科技大学和阿德莱德大学及Data61的研究人员进行。他们展示了如何在没有直接读取权限的情况下,通过分析Rowhammer攻击产生的影响,来读取内存中的敏感信息。这种攻击方式不仅限于特权升级,还可能涉及到读取和泄露用户的隐私数据,包括密码、加密密钥或其他敏感信息,这将对系统的安全性构成严重威胁。
为了防范RAMBleed攻击,硬件制造商需要改进DRAM的设计,例如增强内存单元的隔离,以防止电荷泄漏影响到相邻单元。软件层面,开发者也需要考虑引入防御机制,比如更频繁地刷新内存以减少电荷积累,或者采用更安全的内存分配策略,避免数据过于集中可能导致的Rowhammer效应。
RAMBleed揭示了内存安全的新维度,对系统安全提出了新的挑战。对于IT专业人士来说,理解这一漏洞的原理并采取适当的防护措施,已经成为保障系统和用户数据安全的必要步骤。
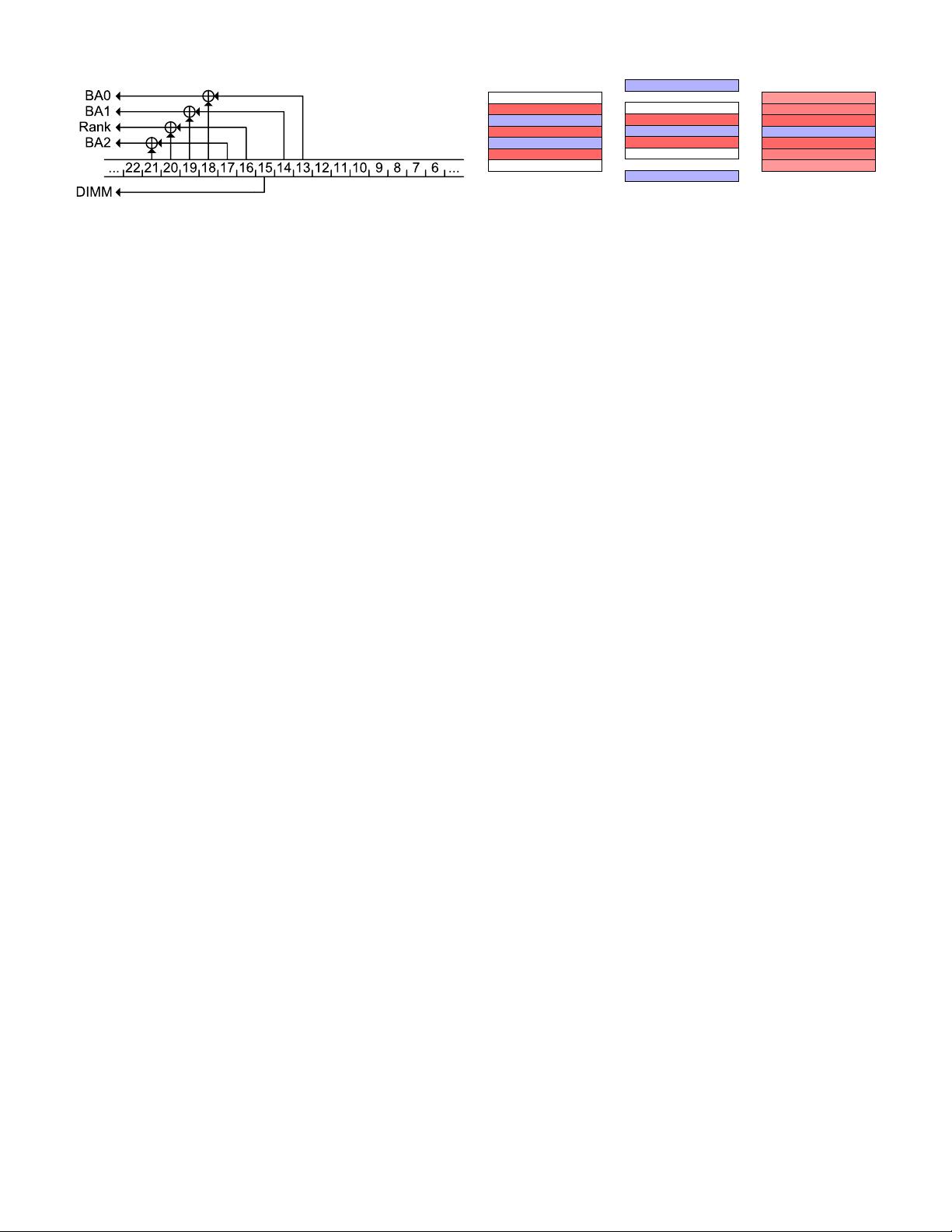
Fig. 1: Reverse engineered DDR3 single channel mapping (2
DIMM per channel) for Ivy Bridge / Haswell (from [49]).
engineered through both software- and hardware-based tech-
niques [49]. For example, Section II-A shows the DRAM
mapping for a typical configuration found in Ivy Bridge and
Haswell systems. As the figure shows, the bank and the rank
are determined based on bits 13–21 of the physical address. We
have verified that the mapping matches the Haswell processor
we use in our experiments.
Row Addressing. As discussed above, DRAM rows have a
fixed size of typically 8 KiB. However, from the implementa-
tion side, it is usually more important to know what amount of
memory has the same row index. This is sometimes referred to
as same-row [19, 55]. If the address goes to the same row and
the same bank, it is called same-row same-bank; if it goes
to different banks but has the same row index, it is called
same-row different-bank [55].
In our experimental setup, we have a total of 32 DRAM
banks, and thus an aligned block of 256 KiB = 2
18
B of
memory has the same row index. In other words, the row
index on our system is directly determined by bits 18 and
above of the physical address. Pessl et al. [49] provide a more
extensive discussion.
B. Row-Buffer Timing Side Channel
Opening a row and loading its contents into the row buffer
results in a measurable latency. Even more so, repeatedly
alternating accesses to two uncached memory locations will
be significantly slower if these two memory locations happen
to be mapped to different rows of the same bank [49]. In
Section V, we use this timing difference to identify virtual
addresses whose contents lie within the same bank, and
also uncover the lower 22 physical addressing bits, thereby
enabling double-sided Rowhammer attacks.
C. Rowhammer
The trend towards increasing DRAM cell density and de-
creasing capacitor size over the past decades has given rise to
a reliability issue known as Rowhammer. Specifically, repeated
accesses to rows in DRAM can lead to bit flips in neighboring
rows (not only the direct neighbors), even if these neighboring
rows are not accessed [34].
The Root Cause of Rowhammer. Due to the proximity of
word lines in DRAMs, when a word line is activated, crosstalk
effects on neighboring rows result in partial activation, which
leads to increased charge leakage from cells in neighboring
rows. Consequently, when a row is repeatedly opened, some
· · ·
· · ·
expect flip
hammer
expect flip
hammer
expect flip
(a) Double-sided
· · ·
· · ·
hammer
hammer
expect flip
hammer
expect flip
(b) Single-sided
· · ·
· · ·
expect flip
expect flip
expect flip
hammer
expect flip
expect flip
expect flip
(c) One-location
Fig. 2: Different hammering techniques as presented by [21].
cells lose enough charge before being refreshed to drop to an
uncharged state, resulting in bit flips in memory.
Performing Uncached Memory Accesses. A central re-
quirement for triggering Rowhammer bit flips is the capability
to make the memory controller open and close DRAM rows
rapidly. For this, the adversary needs to generate a sequence
of memory accesses to alternating DRAM rows that bypass
the CPU cache. Several approaches have been suggested for
bypassing the cache.
• Manually Flush Cache Lines. The x86 instruction
set provides the CLFLUSH instruction, which flushes the
cache line containing its destination address from all of
the levels of the cache hierarchy. Crucially, CLFLUSH only
requires read access to the flushed address, facilitating
Rowhammer attacks from unprivileged user-level code. On
ARM platforms, prior to ARMv8, the equivalent cache line
flush instruction could only be executed in kernel mode;
ARMv8 does, however, offers operating systems the option
to enable an unprivileged cache line flush operation.
• Cache Eviction. In cases where the CLFLUSH instruction
is not available (e.g. in the browser), an attacker can force
contention on cache sets to cause cache eviction [2, 19].
• Uncached DMA Memory. Van Der Veen et al. [61] report
that the cache eviction method above is not fast enough to
cause bit flips on contemporary ARM-based smartphones.
Instead, they used the Android ION feature to allocate
uncacheable memory to unprivileged userspace applications.
• Non-temporal instructions. Non-temporal load and store
instructions direct the CPU not to cache their results. Avoid-
ing caching means that subsequent accesses to the same
address bypass the cache and are served from memory [50].
Another important distinction between Rowhammer attacks is
the strategy in which DRAM rows are activated, i.e., how
aggressor rows are selected. See Figure 2.
Double-sided Rowhammer. The highest amount of
Rowhammer-induced bit flips occur when the attacker ham-
mers, that is repeatedly opens and closes, the two rows
adjacent to a target row. This approach maximizes the number
of neighboring row activations, and consequently the charge
leakage from the target row (Figure 2a). However, for double-
sided hammering, the attacker needs to locate addresses in the
two adjacent rows, which may be difficult without knowledge
of the physical addresses and their mapping to rows. Previous
attacks exploited the Linux pagemap interface, which maps
virtual to physical addresses. However, to mitigate the Seaborn
In Proceedings of the 41st Annual IEEE Symposium on Security & Privacy, May 2020 Page 4
剩余16页未读,继续阅读
2024-09-07 上传
2024-09-07 上传
2024-09-07 上传
2024-09-07 上传

u010159726
- 粉丝: 0
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建Cadence PSpice仿真模型库教程
- VMware 10.0安装指南:步骤详解与网络、文件共享解决方案
- 中国互联网20周年必读:影响行业的100本经典书籍
- SQL Server 2000 Analysis Services的经典MDX查询示例
- VC6.0 MFC操作Excel教程:亲测Win7下的应用与保存技巧
- 使用Python NetworkX处理网络图
- 科技驱动:计算机控制技术的革新与应用
- MF-1型机器人硬件与robobasic编程详解
- ADC性能指标解析:超越位数、SNR和谐波
- 通用示波器改造为逻辑分析仪:0-1字符显示与电路设计
- C++实现TCP控制台客户端
- SOA架构下ESB在卷烟厂的信息整合与决策支持
- 三维人脸识别:技术进展与应用解析
- 单张人脸图像的眼镜边框自动去除方法
- C语言绘制图形:余弦曲线与正弦函数示例
- Matlab 文件操作入门:fopen、fclose、fprintf、fscanf 等函数使用详解
