Ubuntu单机部署Hadoop教程:从入门到运行
需积分: 10 162 浏览量
更新于2024-07-28
收藏 1.38MB PDF 举报
本篇文章主要介绍了如何在单机环境下部署和配置Hadoop。作者Michael G. Noll于2007年8月首次发布并持续更新到2010年11月,旨在帮助读者建立一个用于学习和测试的单节点Hadoop集群。以下是文章详细步骤:
1. **目标**:教程首先明确了目标,即设置一个单节点Hadoop集群,以便用户可以在本地环境中体验Hadoop的分布式计算框架。
2. **前提条件**:文章强调了几个关键的前提,包括安装Sun Java 6,因为Hadoop需要一个稳定的Java环境。此外,还需要为Hadoop创建一个专用的系统用户,这有助于确保系统的安全性。
3. **SSH配置**:为了方便集群内部的通信,文章指导用户配置SSH,确保Hadoop节点之间的通信可以无缝进行。
4. **禁用IPv6**:有时出于安全或性能考虑,教程建议禁用IPv6,这可能影响到网络配置。
5. **Hadoop安装**:介绍了一个替代安装方法,可能针对特定的Ubuntu Linux版本或者不同版本的Hadoop,确保用户可以根据实际情况选择合适的安装路径。
6. **Hadoop分布式文件系统(HDFS)**:作者深入探讨了Hadoop的核心组件之一——HDFS,包括其配置文件(如`hadoop-env.sh`和`conf/*-site.xml`)以及名称节点(NameNode)的格式化过程。
7. **启动和停止集群**:教程提供了详细的步骤来启动单节点Hadoop集群,并指导如何在完成任务后安全地关闭它。
8. **MapReduce示例**:为了展示Hadoop的实际应用,文章提供了一个完整的流程,包括下载样例输入数据、将数据复制到HDFS、运行MapReduce作业,以及获取作业结果。
9. **Web接口**:文章还介绍了Hadoop的两个主要Web界面,MapReduce JobTracker和TaskTracker Web Interface,这些接口允许用户监控和管理任务的执行情况,以及HDFS的文件系统。
通过这篇教程,读者能够掌握在单机上搭建和管理Hadoop的基本流程,这对于理解分布式计算和Hadoop的架构至关重要。无论是作为初学者入门还是作为开发者进行本地测试,这个教程都是一个宝贵的资源。

Hadoop package to a location of your choice. I picked /usr/local/hadoop. Make sure to change
the owner of all the files to the hadoop user and group, for example:
(just to give you the idea, YMMV – personally, I create a symlink from hadoop-0.20.2 to hadoop)
Alternative
Update March 2010: I have been notified by some readers that they’ve run into
problems using the Cloudera package for setting up multi-node Hadoop clusters
according to my tutorials. Falling back to installing from source solved their problems.
Update June 2009: The folks over at Cloudera notified me that they have bundled up
Hadoop as an open source Deb package. If you add their repository to APT, you can use
apt-get to install the needed packages for Hadoop and related subprojects like Pig or
Hive. According to Jeff Hammerbacher from Cloudera, they are actually working with
the Canonical team to get these packages added to the vanilla distribution of Ubuntu.
Link: http://www.cloudera.com/hadoop-deb
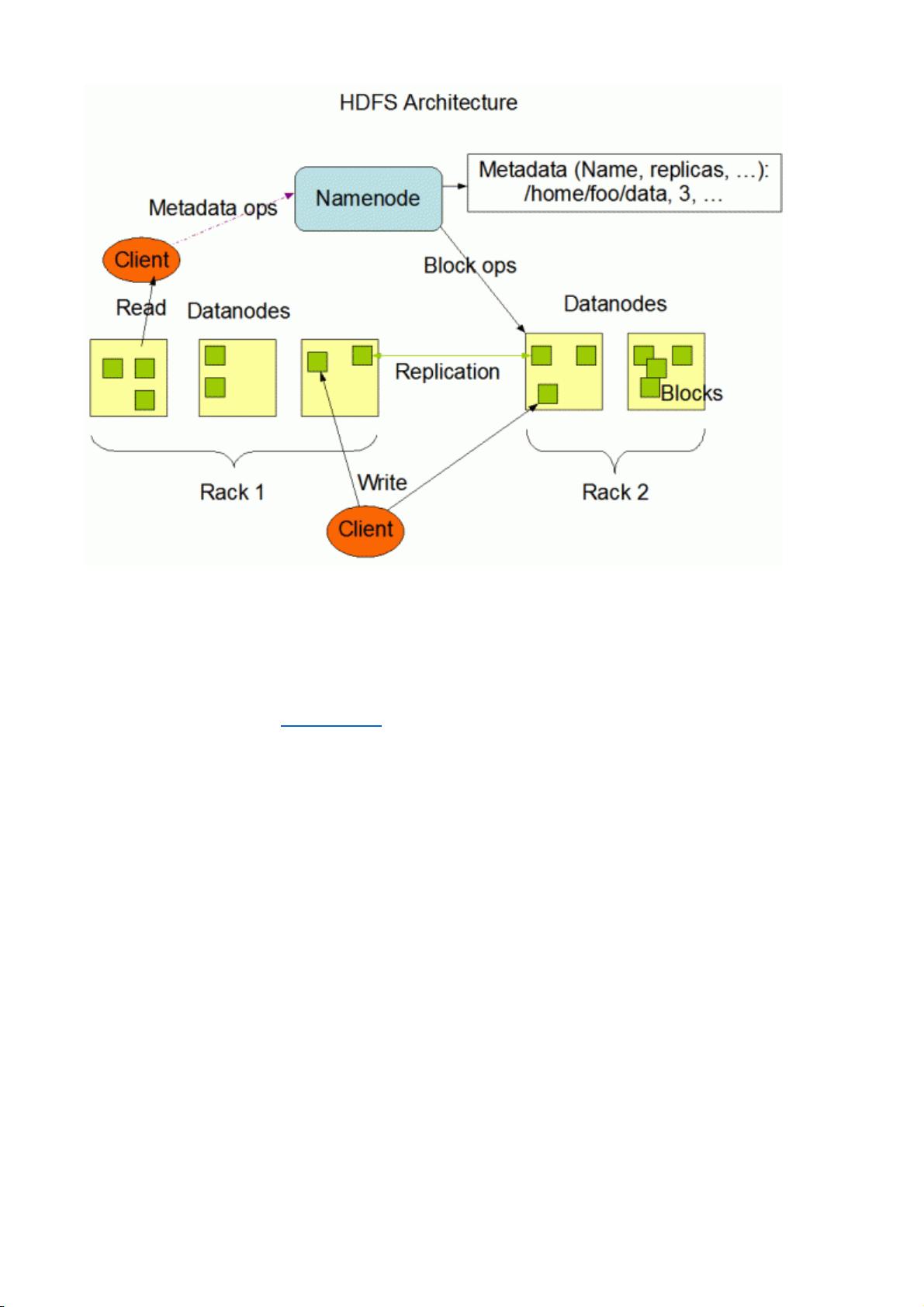
Excursus: Hadoop Distributed File System (HDFS)
From The Hadoop Distributed File System: Architecture and Design:
The Hadoop Distributed File System (HDFS) is a distributed file system designed to run
on commodity hardware. It has many similarities with existing distributed file systems.
However, the differences from other distributed file systems are significant. HDFS is
highly fault-tolerant and is designed to be deployed on low-cost hardware. HDFS
provides high throughput access to application data and is suitable for applications that
have large data sets. HDFS relaxes a few POSIX requirements to enable streaming
access to file system data. HDFS was originally built as infrastructure for the Apache
Nutch web search engine project. HDFS is part of the Apache Hadoop project, which is
part of the Apache Lucene project.
The following picture gives an overview of the most important HDFS components.
1
$
cd
/usr/
local
2
$
sudo
tar
xzf hadoop
-
0.20.2.
tar
.gz
3
$
sudo
mv
hadoop
-
0.20.2 hadoop
4
$
sudo
chown
-
R
hadoop:hadoop hadoop
页码,6/33(W)
剩余32页未读,继续阅读
2021-09-19 上传
2014-02-10 上传
2020-09-05 上传
2013-06-19 上传
2013-02-25 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情

风吹过的时光
- 粉丝: 418
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
