异常数据处理:从预处理到统计分析的影响
版权申诉
45 浏览量
更新于2024-07-08
收藏 701KB PDF 举报
"统计数据的预处理.pdf"
在统计分析中,数据预处理是一个至关重要的步骤,它直接影响到后续分析的准确性和可靠性。本资源主要探讨了数据预处理中的两个关键环节:异常数据处理和缺失数据处理。异常数据,也称为可疑值、离群值等,是指在数据集中显著偏离其他数据点的观测值。异常值可能是由测量错误、记录失误或者真实存在的极端情况引起的。在数据分析中,如果不加以处理,异常数据可能导致统计推断出现误导性的结论。
例如,文档中提到的一个糖尿病患者案例,研究者在分析药物对胰岛素和血糖影响时,发现一对异常数据(编号6的患者,胰岛素数值显著高于其他患者)。在剔除这个异常值之前,计算得到的Pearson相关系数为0.314,表明两者之间关联不明显。然而,当剔除异常值后,相关系数变为-0.936,揭示出胰岛素与血糖之间存在显著的负相关关系。这说明异常数据的存在确实可能掩盖实际的统计关联。
处理异常数据通常涉及几种方法,包括物理判别法和统计判别法。物理判别法依赖于领域知识,通过观察和理解数据产生的过程来识别异常。例如,如果某个测量值明显超出预期的物理界限,可以判定为异常。而统计判别法则更为量化,通常会设定一个置信水平,如95%或99%,并计算相应的置信限。超出这些限值的数据点被视为异常,可能需要被删除或修正。
缺失数据则是另一种常见的数据质量问题。在实际数据收集过程中,由于各种原因(如调查响应不全、设备故障等),数据集可能出现部分数据缺失的情况。处理缺失数据的方法包括删除含有缺失值的观测(完全删除或条件删除)、插补缺失值(均值插补、回归插补、多重插补等)以及使用特殊算法如EM算法(期望最大化算法)来估计缺失值。
总结来说,数据预处理是统计分析前的重要步骤,其目的是确保数据质量,消除可能影响分析结果的因素。对于异常数据,我们需要根据领域知识和统计学方法进行识别和处理;而对于缺失数据,则需要选择合适的策略来填补空白,以便于后续的分析能反映数据的真实情况。有效的数据预处理能够提高统计模型的稳定性和预测能力,从而得出更可靠的研究结论。

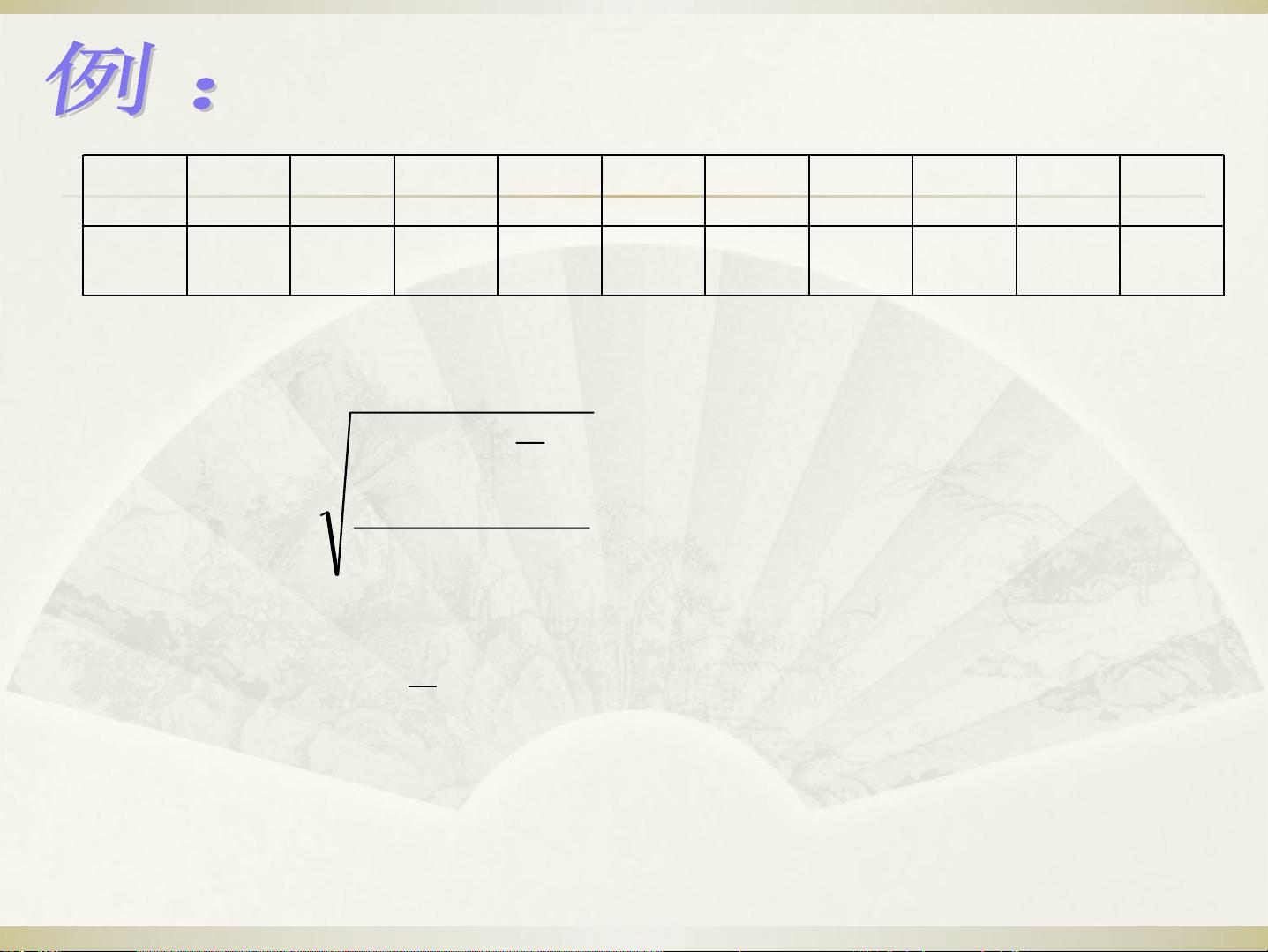
统计判别法之一:拉依达准则
003.0)3( ≤>−
σ
uxp
• 如果实验数据的总体x是服从正态分布的,
则
• 根据上式对于大于μ+3σ或小于μ-3σ的
实验数据作为异常数据,予以剔除。
• 剔除后,对余下的各测量值重新计算偏差
和标准偏差,并继续审查,直到各个偏差
均小于3σ为止。
• 无需查表,使用简便
剩余53页未读,继续阅读
2022-07-02 上传
2021-09-20 上传
2021-07-16 上传
2023-05-03 上传
2021-11-17 上传
2021-07-14 上传
2021-02-04 上传
2021-09-14 上传
2022-12-23 上传

挖洞的杰瑞
- 粉丝: 818
- 资源: 385
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
