
4/23/23, 1:14 PM
拆解追溯 GPT-3.5 各项能力的起源
https://yaofu.notion.site/GPT-3-5-360081d91ec245f29029d37b54573756
10/57
Zhi Jiang Dec 16
https://help.openai.com/en/articles/6779149
-how-do-text-davinci-002-and-text-davinci-
003-differ
It is rather challenging to
determine whether the initial
GPT-3 (
davinci
in OpenAI API)
is “strong” or “weak.” On the
one hand, it responds to certain
queries reasonably and
achieves OK-ish performance
on many benchmarks; on the
other, it underperforms small
models like T5 on many tasks
(see its original paper). It is also
very hard to say the initial GPT-
3 is “smart” in today's (= Dec
2022) ChatGPT standard. The
sharp comparison of initial
GPT-3’s ability v.s. today’s
standard is replayed by Meta’s
OPT model, which is viewed as
“just bad” by many who have
tested OPT (compared to
text-
davinci-002
). Nevertheless,
OPT might be a good enough
open-source approximation to
the initial GPT-3 (according to
the OPT paper and Stanford’s
HELM evaluation).
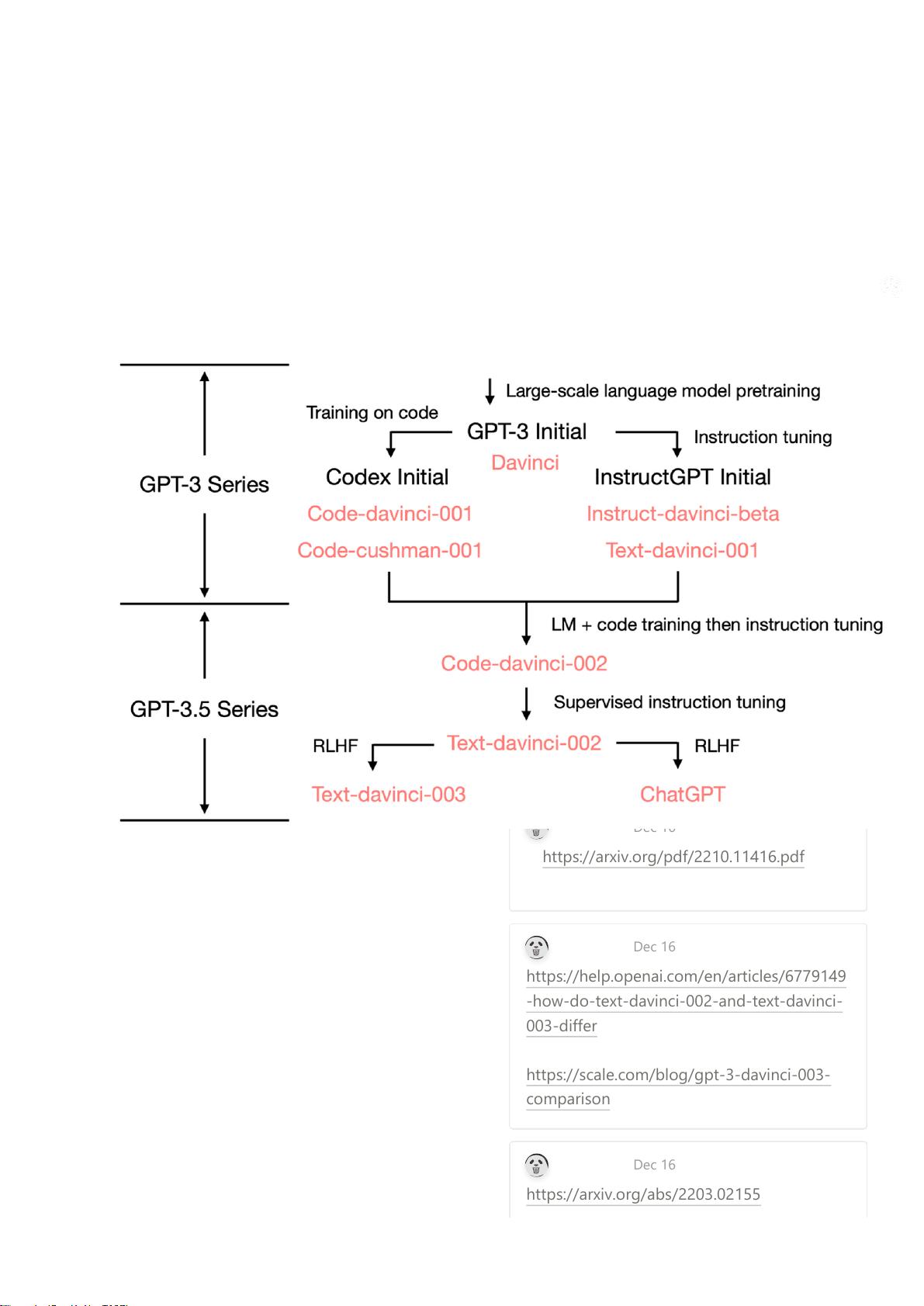
Although the initial GPT-3
might be superficially weak, it
turns out later that these
abilities serve as very important
foundations of all the emergent
abilities unlocked later by
training on code, instruction
tuning, and reinforcement
learning with human feedback
(RLHF).
剩余56页未读,继续阅读















