CentOS上Hadoop HDFS与HBase部署教程
需积分: 0 62 浏览量
更新于2024-08-05
收藏 1.19MB PDF 举报
本篇文章主要介绍了如何在CentOS系统上部署Hadoop HDFS和HBase,作者基于之前在Ubuntu环境下的部署经验进行了调整。首先,我们来看一下Hadoop的部署:
1. **Hadoop 3.1.3 安装**:
在CentOS服务器上,作者首先从Hadoop官网下载了3.1.3版本的Linux安装包,然后通过SCP协议将包传输至服务器,并将其解压到`/usr/local`目录下。接着,通过`chown`命令设置文件权限,确保Hadoop用户拥有相应的访问权限,最后通过运行`hadoop version`检查安装是否成功。
2. **Hadoop 单机配置 (非分布式)**:
Hadoop默认是非分布式模式,适合于本地调试。用户需要创建一个`input`目录并将配置文件复制到其中,并利用Hadoop的MapReduce框架执行简单的grep操作,统计包含特定正则表达式的文本文件中单词的出现次数。
接下来是HBase的安装和使用:
3. **HBase 安装**:
HBase在完成Hadoop的安装后进行,同样是从源码或官方发布版下载,然后按照步骤进行安装。
4. **HBase 操作**:
- **创建表**: 用户可以使用HBase的命令行工具创建新的表,定义其列族和列等属性。
- **数据添加与删除**: 通过HBase的API或者shell命令插入和删除数据。
- **数据查看**: 使用命令行工具查询已存储的数据。
5. **HDFS 实践**:
- **Shell命令交互**: 学习如何通过HDFS的Shell命令进行文件操作,如上传、下载、删除等。
- **Web界面管理**: 了解如何通过Hadoop的Web UI来监控和管理HDFS,直观地查看文件系统状态。
本文提供了一个实用的学习路径,适用于对Hadoop HDFS和HBase有兴趣的大学生,特别是那些想要在CentOS环境下进行实践和部署的学生。通过这个步骤,他们能够理解Hadoop的核心组件以及如何在实际环境中进行配置和操作。对于那些希望深入了解大数据处理和分布式计算的读者来说,这是一个很好的起点。
2
grep ./input ./output 'dfs[a-z.]+'
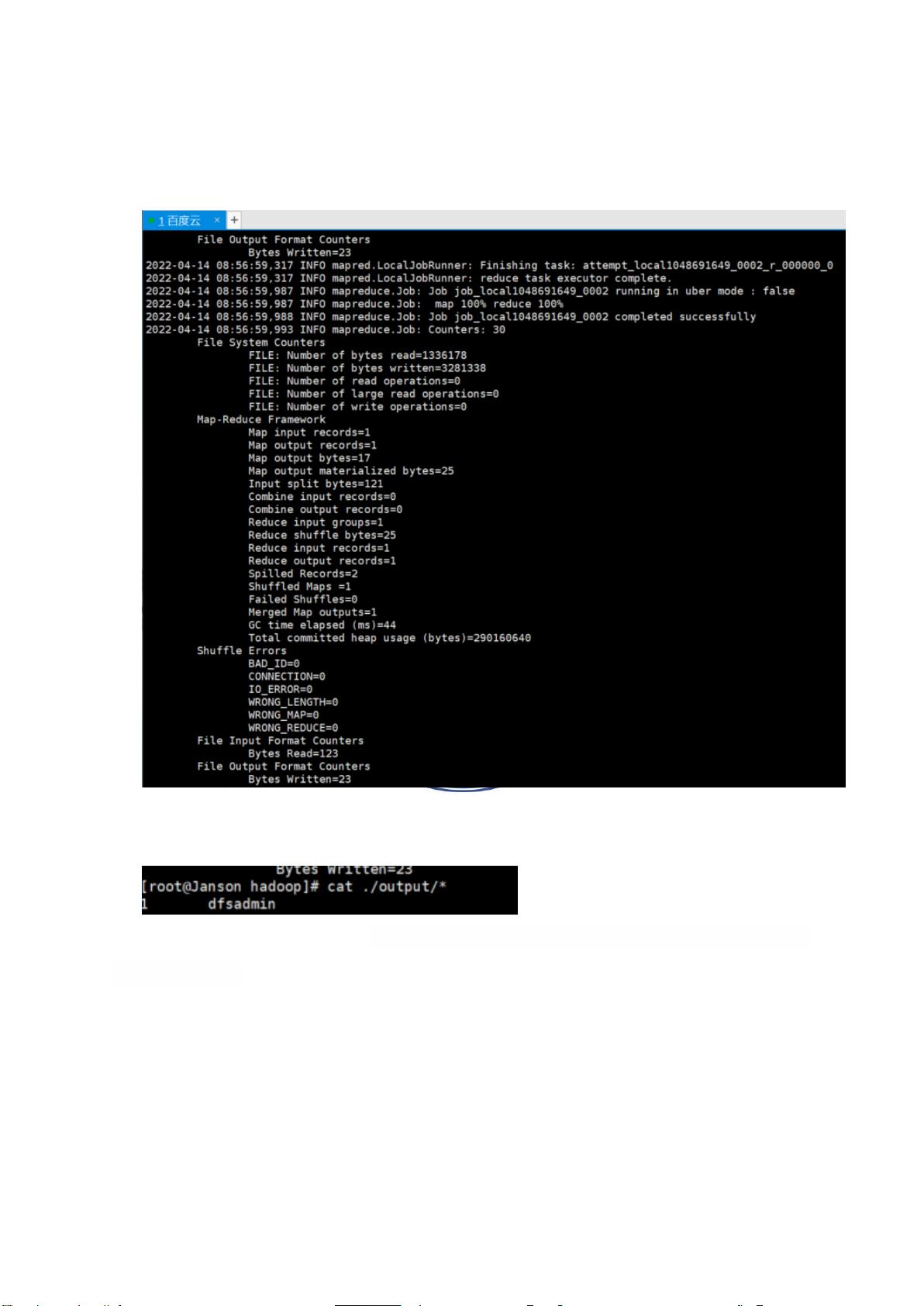
执行成功结果如下:
查看执行后生成的 output 文件下的所有内容,结果如下:
cat ./output/*
最后需要删除./output 文件,Hadoop 默认不会覆盖结果文件,因此再次运行上面实
例会提示出错。
rm -r ./output
3. Hadoop 伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程
来运行,节点既作为 NameNode 也作为 DataNode,同时,读取的是 HDFS 中的文件。
Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改 2 个配
剩余12页未读,继续阅读
2020-10-20 上传
2014-01-09 上传
2018-03-27 上传
2021-10-03 上传
2021-09-28 上传
2021-10-03 上传
点击了解资源详情
点击了解资源详情
2022-06-14 上传

Janson666
- 粉丝: 1w+
- 资源: 2
 我的内容管理
展开
我的内容管理
展开







最新资源
- 探索数据转换实验平台在设备装置中的应用
- 使用git-log-to-tikz.py将Git日志转换为TIKZ图形
- 小栗子源码2.9.3版本发布
- 使用Tinder-Hack-Client实现Tinder API交互
- Android Studio新模板:个性化Material Design导航抽屉
- React API分页模块:数据获取与页面管理
- C语言实现顺序表的动态分配方法
- 光催化分解水产氢固溶体催化剂制备技术揭秘
- VS2013环境下tinyxml库的32位与64位编译指南
- 网易云歌词情感分析系统实现与架构
- React应用展示GitHub用户详细信息及项目分析
- LayUI2.1.6帮助文档API功能详解
- 全栈开发实现的chatgpt应用可打包小程序/H5/App
- C++实现顺序表的动态内存分配技术
- Java制作水果格斗游戏:策略与随机性的结合
- 基于若依框架的后台管理系统开发实例解析
