缓存面试题精粹:从基础到高级
69 浏览量
更新于2024-08-03
收藏 823KB PDF 举报
"缓存面试题大全 pdf版"
缓存是一种用于存储临时数据的技术,旨在提高系统性能和响应速度。它通过将经常访问的数据存储在快速访问的存储介质中,如内存,来减少对慢速介质(如硬盘)的依赖。缓存的存在是基于局部性原理,即程序运行时,数据访问往往呈现出时间和空间上的局部性,即同一数据可能会连续被访问,或者相似数据会被相继访问。
为什么要使用缓存呢?主要原因在于提升系统的读写性能。例如,当数据库(如MySQL)处理高并发读请求时,可能会成为性能瓶颈。而像Redis这样的内存数据库,其读写速度远超传统数据库,可以作为缓存层存储热点数据,显著提高应用的响应速度。此外,缓存还可以降低后端系统的负载,防止因大量请求导致的系统崩溃。
缓存算法是决定缓存效率的关键。其中,LRU(Least Recently Used)是最常用的算法之一。LRU策略的基本思想是,最近最少使用的数据优先被淘汰。当缓存满时,最近最少使用的数据将首先被移除,以腾出空间给新数据。以下是一个简单的LRU缓存实现的Python代码示例:
```python
from collections import OrderedDict
class LRUCache:
def __init__(self, capacity):
self.cache = OrderedDict()
self.capacity = capacity
def get(self, key):
if key in self.cache:
value = self.cache.pop(key)
self.cache[key] = value
return value
else:
return -1
def put(self, key, value):
if key in self.cache:
del self.cache[key]
elif len(self.cache) == self.capacity:
self.cache.popitem(last=False) # 移除最久未使用的项
self.cache[key] = value
```
除了LRU,还有LFU(Least Frequently Used)和随机淘汰等策略。LFU基于数据访问频率,最少访问的数据会被优先淘汰;随机淘汰则简单地随机选择一个数据进行淘汰。
常见的缓存工具有Redis和Memcached。Redis是一个功能丰富的键值存储系统,支持多种数据结构如字符串、哈希、列表、集合和有序集合,广泛应用于缓存、消息队列等场景。Memcached则是一个更轻量级的分布式内存对象缓存系统,主要用于存储小块的字符串和二进制数据。
使用缓存后,会出现一些常见问题,比如缓存一致性问题,即缓存和数据库数据可能不同步。解决这个问题通常采用缓存更新策略,如“先写数据库,再删除缓存”或“先删除缓存,再写数据库”。还有缓存穿透,当请求的数据既不在缓存中也不在数据库中,可能导致大量无效请求冲击数据库,可以通过布隆过滤器来预防。另外,缓存雪崩是指大量缓存同时过期,导致请求全部落到数据库上,可以通过设置合理的过期时间、使用加锁机制或增加冗余缓存来避免。
当查询缓存报错时,提高可用性的方法包括:使用缓存集群以提高容错性,设置适当的错误重试机制,以及使用缓存预热策略,预先加载常用数据到缓存中。
避免缓存雪崩的问题,可以采取以下策略:设置独立的缓存过期时间,使得缓存过期时间分散;使用互斥锁(如Redis的SETNX命令)在缓存失效时进行更新操作,避免大量并发请求同时访问数据库;以及引入随机性,让缓存不是精确在同一时间过期,而是有一定的偏差。
缓存是优化系统性能的重要手段,但同时也需要处理好与之相关的各种问题,以确保系统的稳定性和高效性。
缓存何时写入?并且写时如何避免并发重复写入?
缓存如何失效?
缓存和 DB 的一致性如何保证?
如何避免缓存穿透的问题?
如何避免缓存击穿的问题?
如果避免缓存雪崩的问题?
:重点可以去“记”加粗的五个词。
下面,我们会对每个问题,逐步解析。
当查询缓存报错,怎么提高可用性?
缓存可以极大的提高查询性能,但是缓存数据丢失和缓存不可用不能影响应用的正常工作。
因此,一般情况下,如果缓存出现异常,需要手动捕获这个异常,并且记录日志,并且从数据库查询数据返回给用
户,而不应该导致业务不可用。
当然,这样做可能会带来缓存雪崩的问题。具体怎么解决,可以看看本文 「如何避免缓存”雪崩”的问题?」 问题。
如果避免缓存”穿透”的问题?
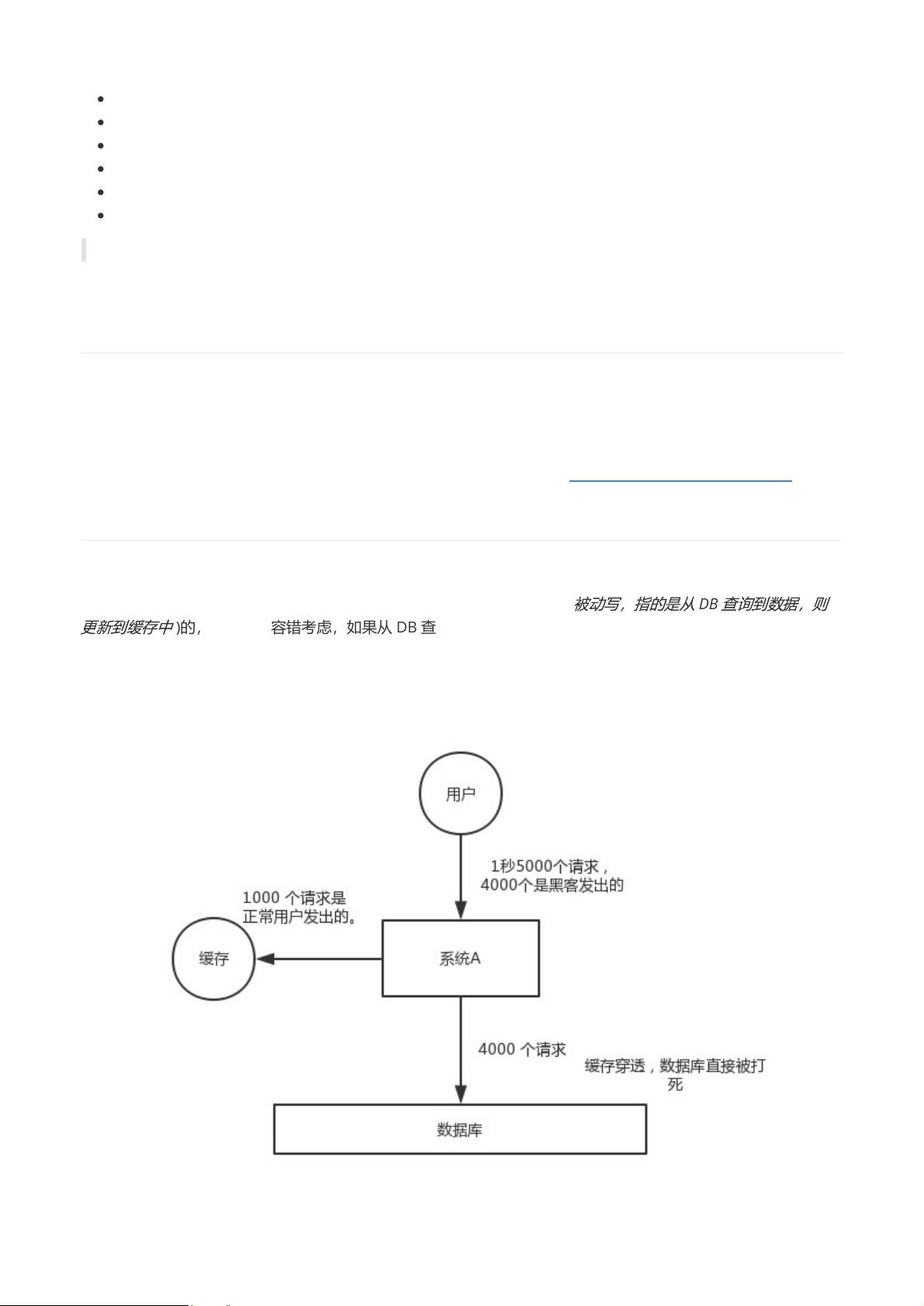
🦅 缓存穿透
缓存穿透,是指查询一个一定不存在的数据,由于缓存是不命中时被动写(
被
动
写
,
指
的
是
从
DB
查
询
到
数据
,
则
更新
到
缓
存
中
)的,并且处于容错考虑,如果从 DB 查不到数据则不写入缓存,这将导致这个不存在的数据每次请
求都要到 DB 去查询,失去了缓存的意义。
在流量大时,可能 DB 就挂掉了,要是有人利用不存在的 key 频繁攻击我们的应用,这就是漏洞。如下图:
剩余11页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-11-18 上传
2022-06-12 上传
2020-05-12 上传
2021-08-05 上传
2021-09-30 上传
2022-01-12 上传

bug搬运工
- 粉丝: 196
- 资源: 52
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
