支持向量机与感知机:机器学习中的分类方法
版权申诉
94 浏览量
更新于2024-08-04
收藏 304KB PDF 举报
"该资源是关于支持向量机(Support Vector Machines, SVM)的教程,源自MATH1900机器学习课程。它探讨了如何找到最大化两类数据集分离的超平面,以及与逻辑回归的区别,并介绍了感知机问题。"
在机器学习领域,支持向量机是一种强大的监督学习算法,特别适用于分类和回归任务。它主要的目标是在给定的数据集中找到一个最优的超平面,这个超平面能够最大程度地将不同类别的样本分开。超平面由线性方程定义,即 \( y = w_0 + \sum_{j=1}^{n} w_j x_i^j \),其中 \( y \) 表示目标值,\( w \) 是权重向量,\( w_0 \) 是偏置项,\( x_i \) 是特征向量。
描述中提到的“一般超平面分离问题”是指寻找一组权重系数 \( w \),使得超平面能正确分类数据点。对于二分类问题,如果数据集是线性可分的,那么存在至少一个超平面可以将两类数据完全分隔开。在逻辑回归中,我们通过最小化损失函数(如对数似然损失函数)来找到最佳分类边界。然而,支持向量机采用了一种不同的方法来构建超平面。
接下来,文档提到了感知机(Perceptron)问题。感知机是一种早期的线性分类模型,它同样寻找一个超平面来分割数据,但它的学习策略是迭代的,每次更新权重 \( w \) 使得误分类的数据点被正确分类。如果数据集是线性可分的,感知机会在有限的步骤内收敛。对于非线性可分数据,感知机可能无法找到一个合适的解,而SVM则通过引入核函数解决了这个问题。
支持向量机的关键创新在于其优化目标。不同于感知机,SVM试图找到最大边距的超平面,即最大化两类样本到超平面的距离。这个距离被称为间隔(Margin)。支持向量是离超平面最近的那些样本点,它们决定了超平面的位置。通过最大化间隔,SVM可以得到较好的泛化能力,因为它倾向于找到更“宽松”的分类边界,不依赖于单个样本点的位置。
在处理非线性数据时,SVM利用核技巧(如高斯核、多项式核等)将数据映射到高维空间,在这个空间中原本不可分的数据可能变得线性可分。这样,我们可以在原始低维空间中使用线性模型,但实际上执行的是高维空间中的非线性分类。
总结来说,SVM是一种高效且强大的分类工具,尤其擅长处理小样本和高维数据。它通过最大化间隔来构建决策边界,同时通过核函数处理非线性问题。与感知机相比,SVM具有更好的泛化性能,这使其在许多实际应用中表现出色,包括图像识别、自然语言处理和生物信息学等领域。
Support Vector Machines
MATH1900: Machine Learning
Location: http://people.sc.fsu.edu/∼jburkardt/classes/ml 2019/support vector machines/support vector machines.pdf
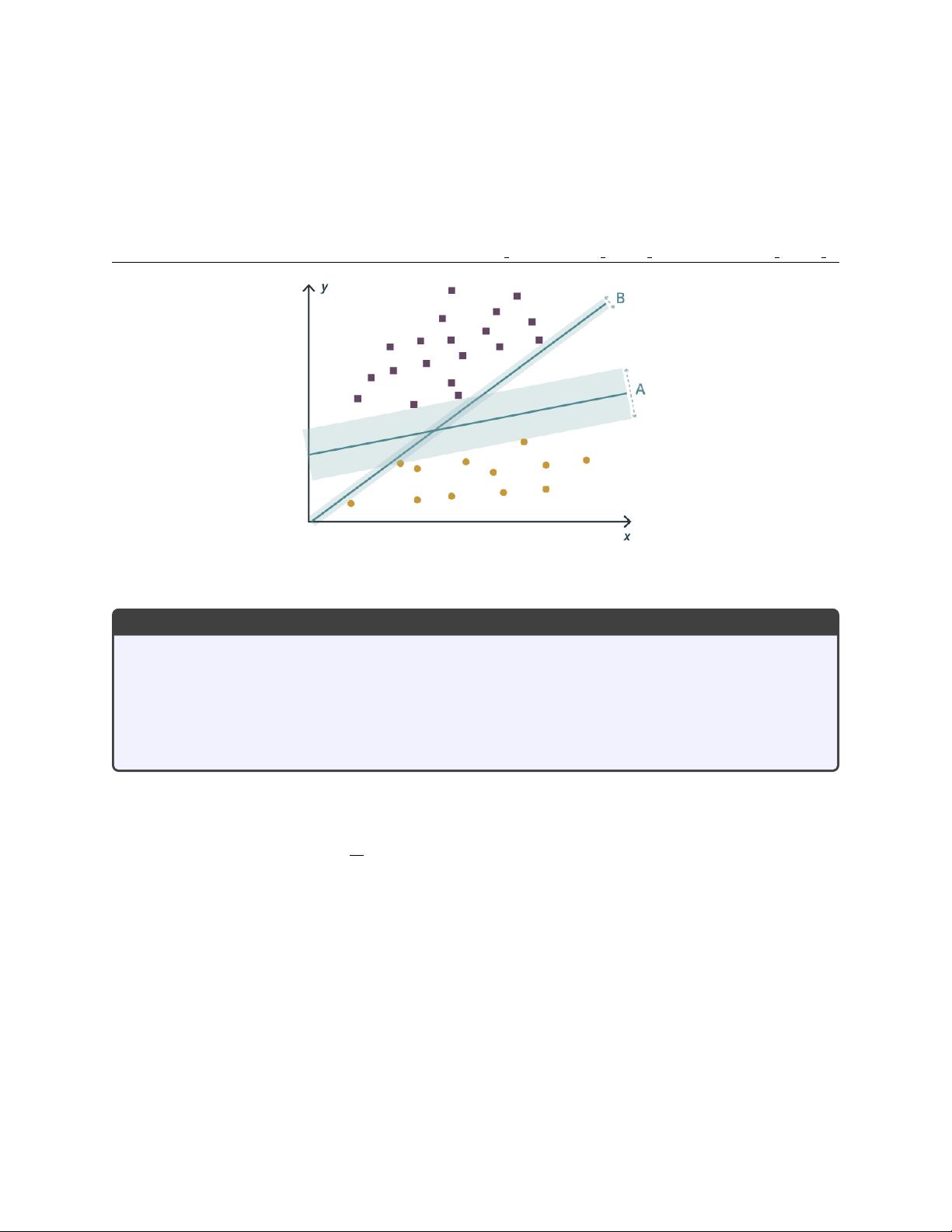
What line maximizes the separation between two sets of data?
The general hyperplane separation problem
Given m items of n-dimensional data x, some of which belong to set P , find the coefficients w of a
hyperplane
y(x
i
) = w
0
+
n
X
j=1
w
j
x
i,j
so that y(x
i
) indicates whether x
i
belongs in set P .
In the logistic regression problem, we have seen a similar attempt to compute a separator for two sets of
data. In that problem, the solution is determined by finding weights w that minimize the cost:
J(w) =
1
m
m
X
i=1
−y
i
log(y(x
i
)) + (1 − y
i
) log(1 − y(x
i
))
Now we are going to look at two other classification methods which construct a hyperplane by different
procedures.
1
下载后可阅读完整内容,剩余7页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-05-05 上传
2021-09-30 上传
2021-08-11 上传
2011-10-15 上传
2019-12-31 上传
2020-02-13 上传

卷积神经网络
- 粉丝: 371
- 资源: 8448
 我的内容管理
展开
我的内容管理
展开







最新资源
- RichardRNStudio
- wnl.rar_Java编程_Java_
- word2vec:Google的Python接口word2vec
- :rocket:可定制的圆形/线性进度条软件包,支持动画文本,使用SwiftUI构建-Swift开发
- The Flow Of Time-crx插件
- 可运营的SSL证书在线生成系统源码,附带图文搭建教程
- grb:通过HTTP进行争夺从未如此简单
- vgg19-tensorflowjs-model::memo:Tensorflow.js VGG-19的预训练模型
- vault-kustomization
- composify:将WordPress插件zip文件转换为git存储库,以便composer版本约束正常运行
- 基于C#实现的普通图像读取及遥感图像处理
- student.rar_教育系统应用_Visual_C++_
- matlab哈士奇代码-Husky:沙哑
- PSI In-application Extension-crx插件
- 猫鼬简介:Ejemplo de un ORMbásicocreado con mongosse para mongo
- qtff-2001.zip_文件格式_Visual_C++_
