C4.5决策树在wine数据集上的分类实现与比较
 已收录资源合集
已收录资源合集
需积分: 0 137 浏览量
更新于2024-08-04
收藏 2.51MB DOCX 举报
C4.5决策树分类大作业1深入探讨了C4.5算法在UCI wine数据集上的应用,这是一种用于数据挖掘的常用算法,尤其适用于决策树的构建。文章首先介绍了决策树的基本原理,即通过分析样本特征找出不同类别之间的内在联系,以便对未知样本进行预测。
UCI wine数据集是一个经典的多变量数据集,包含13个特征如酒精度、苹果酸含量等,每个样本被标记为三种类型的葡萄酒之一。通过这个数据集,作者的目标是通过C4.5算法挖掘类别与特征之间的关系,并构建一个能够准确预测新样本的决策树。
C4.5算法的具体实现步骤包括:
1. 数据预处理:从UCI机器学习库获取wine数据集,将其分为训练样本和测试样本,通常采用随机抽样方法进行划分。
2. 决策树构造:C4.5算法的核心流程是计算信息增益率,每次选择具有最高增益率的特征进行分裂,形成决策树的分支。剪枝策略用于防止过拟合,确保模型的泛化能力。
3. 测试评估:使用测试样本对构建好的决策树进行预测,通过对比实际类别和预测类别,计算预测误差,以此验证决策树的有效性和准确性。
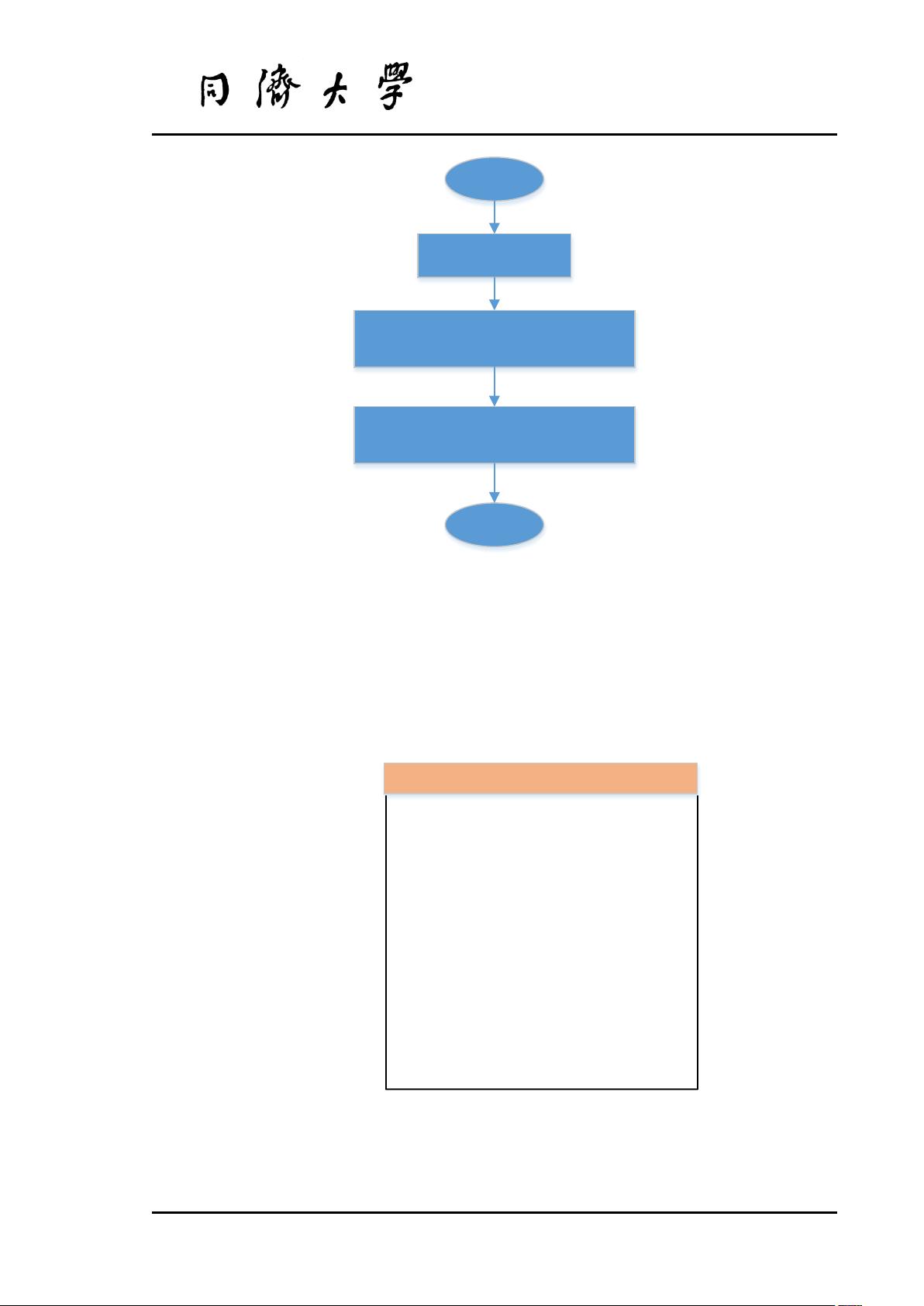
图1展示了C4.5算法的决策树构造流程,包括样本划分、特征选择、分裂以及剪枝等步骤。而图2则展示了预测测试样本类别的流程,通过对预测结果的分析,作者能够评估模型性能,并对决策树的合理性进行检验。
通过本作业,学生不仅掌握了C4.5算法的具体操作,还了解了如何在实际问题中应用决策树进行数据分析和预测。这是一项实用的数据挖掘技术,对于理解数据集特征与类别之间的关联,以及构建有效的预测模型具有重要意义。
第 3 页 共 13 页
┊
┊
┊
┊
┊
┊
┊
┊
┊
┊
┊
┊
┊
装
┊
┊
┊
┊
┊
订
┊
┊
┊
┊
┊
线
┊
┊
┊
┊
┊
┊
┊
┊
┊
┊
┊
┊
┊
开始
提取测试样本
将测试样本输入决策树,预
测所属类别
分析决策树的预测误差
结束
图 2 测试样本类别预测流程图
C4.5 算法构造决策树后,需要对决策树的合理性做评估。图 2 展示了利用所构造的决策树预
测测试样本类别流程。通过对决策树的预测误差作分析,来判别所构造的决策树是否可行。下面
将介绍具体的决策树构造过程。
2.2 C4.5 算法构造决策树
2.2.1 树节点设计
node
+feature_tosplit:分割特征
+location:分割界限
+value:属于该节点的特征取值
+child:子节点
图 3 决策树节点设计
在决策树的构造过程中,信息增益率的计算显得至关重要。各个特征的信息增益率的大小决
定了当前节点的分割特征。因此,在决策树的节点设计上考虑了这一点。图 3 显示了决策树节点
剩余12页未读,继续阅读
2021-12-05 上传
108 浏览量
2024-04-25 上传
2022-08-08 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

养生的控制人
- 粉丝: 23
- 资源: 333
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM Java项目:StudentInfo 数据管理与可视化分析
- pyedgar:Python库简化EDGAR数据交互与文档下载
- Node.js环境下wfdb文件解码与实时数据处理
- phpcms v2.2企业级网站管理系统发布
- 美团饿了么优惠券推广工具-uniapp源码
- 基于红外传感器的会议室实时占用率测量系统
- DenseNet-201预训练模型:图像分类的深度学习工具箱
- Java实现和弦移调工具:Transposer-java
- phpMyFAQ 2.5.1 Beta多国语言版:技术项目源码共享平台
- Python自动化源码实现便捷自动下单功能
- Android天气预报应用:查看多城市详细天气信息
- PHPTML类:简化HTML页面创建的PHP开源工具
- Biovec在蛋白质分析中的应用:预测、结构和可视化
- EfficientNet-b0深度学习工具箱模型在MATLAB中的应用
- 2024年河北省技能大赛数字化设计开发样题解析
- 笔记本USB加湿器:便携式设计解决方案
