数据挖掘复习:ID3算法、Apriori与朴素贝叶斯实例详解
需积分: 0 85 浏览量
更新于2024-08-04
收藏 1.2MB DOCX 举报
数据挖掘复习中的计算题1主要涵盖了几个重要的概念和技术,包括ID3算法、信息增益、Apriori算法、FP树以及朴素贝叶斯方法。让我们逐一解析这些知识点。
1. **ID3算法** (P130): ID3算法是一种基于信息增益的决策树算法。信息增益是用于评估一个属性对分类效果的指标,它衡量的是在给定属性的条件下,通过划分数据减少不确定性的程度。在例1中,计算每个属性的信息增益,即在已知属性值后,区分不同类别的信息量减少,选择信息增益最大的属性作为当前节点的划分依据。
2. **Apriori算法** (P152): Apriori算法主要用于发现数据库中的频繁模式,例如在购物篮分析中寻找经常一起购买的商品组合。该算法首先找出频繁1项集,然后递归地扩展到频繁模式集。挖掘过程涉及到频繁模式的生成和条件模式基的构建。
3. **FP树** (P158): FP树是Apriori算法的一种优化版本,它通过构建树状结构来存储频繁模式和它们的关联规则。构建过程中,首先扫描数据库以发现频繁项集,然后按频率降序排列并构造FP树。挖掘过程包括生成条件模式基和递归构建子数据库,直到没有更多的频繁模式。
4. **朴素贝叶斯分类**: 朴素贝叶斯方法假设各个特征之间相互独立,利用贝叶斯定理进行预测。在例2中,通过计算给定特征组合下属于不同类别的后验概率,如样本X被分类为P(晴天)或N(非晴天)的概率,来决定最可能的类别。通过比较两个后验概率,确定最合适的分类。
5. **贝叶斯信念网络** (Bayesian Belief Network, BBN): BBN是一种概率图模型,用于表示变量之间的依赖关系。在这个场景中,通过计算各种条件下的概率,如高血压(BP)与心脏病(HD)的关系,来预测疾病的发生概率。计算先验概率、条件概率等帮助我们理解变量间的因果关系和不确定性。
总结来说,数据挖掘计算题1涉及了决策树算法(ID3),频繁模式挖掘(Apriori, FP树),以及基于概率的分类方法(朴素贝叶斯)。通过解决这些问题,学生将能理解和掌握这些基础的数据挖掘技术及其在实际问题中的应用。
1. ID3 算法 P130
例 1
S 中有 s
i
个元组,对应类标签 C
i
(i={1,…,m})
基于训练对象和已知类标号创建决策树,以信息增益为度量来为属性排序。
每个元组所需信息度量
s
s
s
s
,...,s,ss
i
m
i
i
m21 2
1
log)I(
�
�
��
根据属性 A 分裂后,区分所需信息量为
),...,(
...
E(A) 1
1
1
mjj
v
j
mjj
ssI
s
ss
�
�
��
�
信息增益
E(A))s,...,s,I(sGain(A) m21 ��
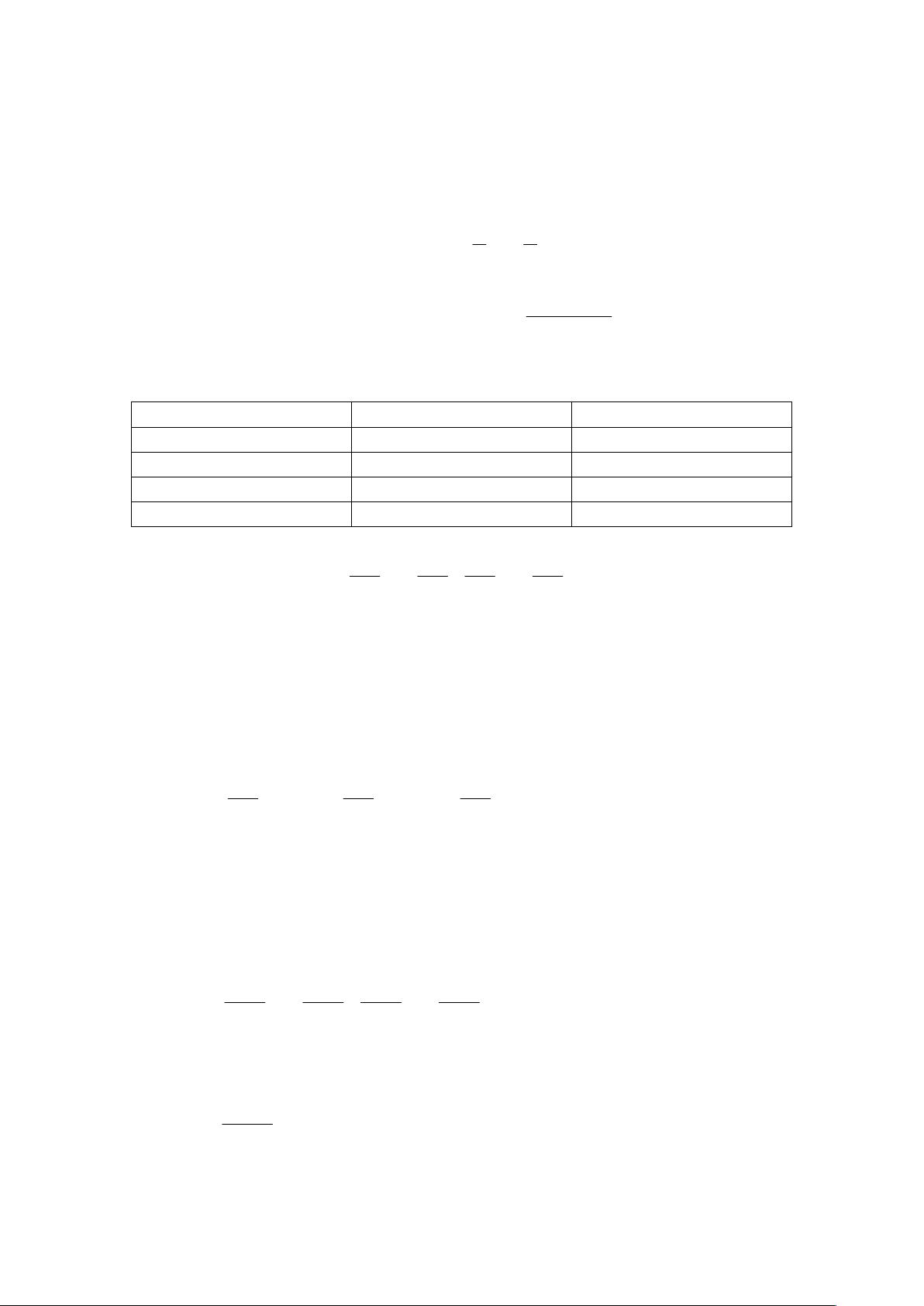
本科生
研究生
理科
42
84
工科
46
36
商科
42
0
汇总
130
120
1. 计算区分任一元组所需的期望信息量
9988.0
250
130
log
250
130
250
120
log
250
120
)130,120I()s,I(s 2221 �����
2. 为每个属性,比如说 major,计算熵
For major=”Science”:
s11=84
s21=42
I(s11,s21)=0.9183
For major=”Engineering”:
s12=36
s22=46
I(s12,s22)=0.9892
For major=”Business”:
s13=0
s23=42
I(s13,s23)=0
3. 即已知 major 信息后,区分元组所需的信息量
7873.0),(
250
42
),(
250
82
),(
250
126
E(major) 231322122111 ���� ssIssIssI
4. 计算每个属性的信息增益
2115.0E(major))s,I(s)Gain(major 21 ���
例 2:
两个类标记:P(假设有 p 个元素) 和 N(假设有 n 个元素)
用来判断任一元素属于 P 还是 N 的信息量为:
np
n
np
n
np
p
np
p
npI
��
�
��
��
22
loglog),(
根据属性 A,集合 S 被划分为{S
1
, S
2
, …, S
v
}
在每个 Si 中,属于类 P 的元素为 P
i
,属于 N 的元素为 n
i
,用来区分的信息量(熵)为
�
�
�
�
�
�
1
),()(
i
ii
ii
npI
np
np
AE
下载后可阅读完整内容,剩余5页未读,立即下载
2021-04-21 上传
2021-06-08 上传
2021-03-07 上传
2023-05-20 上传
2023-06-01 上传
2023-12-23 上传
2023-07-30 上传
2023-12-29 上传
2023-05-30 上传

老光私享
- 粉丝: 631
- 资源: 255
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
