Lucene工作原理与全文搜索引擎
需积分: 9 103 浏览量
更新于2024-09-18
收藏 28KB DOCX 举报
"Lucene工作原理及其重要算法细节解析"
Lucene是一个强大的全文搜索引擎库,源自Apache软件基金会,被广泛应用于各种全文检索应用的开发。它采用先进的倒排索引技术,提供高效的搜索性能。下面我们将深入探讨Lucene的工作原理、算法细节以及其核心组件。
一、Lucene的概述
Lucene最初是一个Java实现的全文检索库,后来发展成为Apache顶级项目,具有高度可扩展性和灵活性。它不仅支持文本搜索,还提供了文档分析、索引构建、搜索查询和结果排序等功能。Lucene被广泛应用在网站、企业内部系统以及大数据分析等领域,为开发者提供了构建高效搜索引擎的基础框架。
二、Lucene的算法原理
1. 全文分析
全文分析是Lucene处理文档的第一步,主要涉及分词、停用词过滤、词形还原和标点符号去除等步骤。这通常由Analyzer类完成。例如,Analyzer会将英文文档中的单词分离,过滤掉如"the"、"in"这样的常见词,同时对关键词进行大小写统一和词形还原处理。对于中文文档,还需要使用专门的分词器,如IK Analyzer或jieba分词,来处理中文的连续文本。
2. 倒排索引
倒排索引是Lucene的核心数据结构。在创建索引过程中,每个文档会被拆分成一系列关键词,然后为每个关键词建立一个列表,记录包含该词的所有文档编号。例如,关键词"live"的倒排索引项会指向文档1和2。此外,为了提高搜索效率,每个关键词还会存储词频(TF,Term Frequency)和位置信息,用于短语匹配和相关性计算。
3. 索引过程
索引过程中,Document对象用于封装文档内容,Field对象用于定义字段类型(如文本、数值或日期),Term对象代表单个关键词。IndexWriter负责创建和更新索引,它可以控制索引的合并策略、段存储和优化等。
4. 查询处理
查询时,用户输入的查询字符串经过Analyzer处理,转换成一系列关键词,然后这些关键词在倒排索引中查找,找到匹配的文档。查询执行引擎根据匹配度、词频和位置信息计算每个文档的相关性,返回排序后的搜索结果。
三、Lucene的其他特性
除了基本的搜索功能,Lucene还包括高级特性如布尔查询、短语查询、模糊查询、范围查询、评分机制等。它还支持多字段搜索、自定义排序规则以及通过Filter和QueryWrapper实现的复杂查询逻辑。
四、优化与性能
为了提升性能,Lucene采用了段(Segment)的概念,每个段是一个独立的索引单元,多个段可以合并成更大的索引。段合并可以减少索引碎片,提高查询速度。同时,Lucene支持近实时搜索,即在新文档添加到索引后,几乎立即可以被搜索到。
总结,Lucene通过其独特的全文分析和倒排索引机制,实现了高效、精确的全文搜索功能。开发者可以根据具体需求,结合Analyzer、Document、Field和Query等组件,灵活定制自己的搜索引擎应用。随着版本的迭代,Lucene不断引入新的特性和优化,保持在全文检索领域的领先地位。
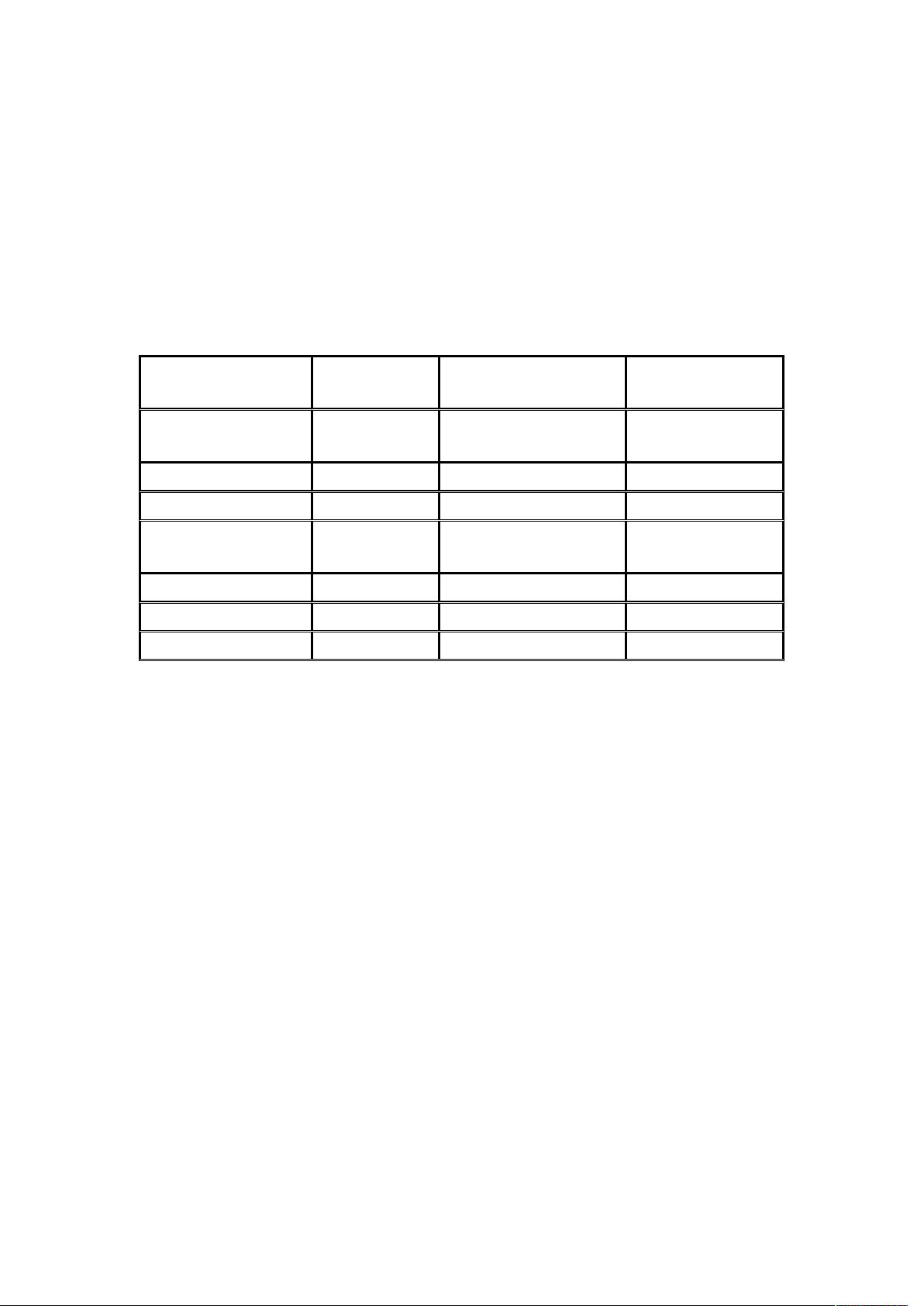
是文章中第几个关键词(优点是节约索引空间、词组()查 询快),
中记录的就是这种位置。
加上“出现频率”和“出现位置”信息后,我们的索引结构变为:
+
+关键词 +文章号 +出现频率 +出现位置
+ + +
+,,-
+ + + +
+ + + +.
+ + +
+,/
+ + + +
+ + + +,
+ + + +
以 这行为例我们说明一下该结构: 在文章 中出现了 次,文章
中出现了一次,它的出现位置为“/&这表示什么呢?我们需要结合文章号
和出现 频率来分析,文章 中出现了 次,那么“/&就表示 在文章 中
出现的两个位置,文章 中出现了一次,剩下的“&就表示 是文章 中第
个关键字。
以上就是 索引结构中最核心的部分。我们注意到关键字是按字符
顺序排列的( 没有使用 0 树结构),因此 可以用二元搜索算法
快速定位关键词。
实现时 将上面三列分别作为词典文件(*1 *))、频
率文件2*3、位置文件 保存。其中词典文件不仅保存有
剩余13页未读,继续阅读
2019-11-13 上传
154 浏览量
2012-05-24 上传
2021-08-27 上传
2023-09-22 上传
2019-11-26 上传
2019-09-22 上传
2021-12-13 上传

loveluoxin
- 粉丝: 0
- 资源: 12
 我的内容管理
展开
我的内容管理
展开







最新资源
- Fisher Iris Setosa数据的主成分分析及可视化- Matlab实现
- 深入理解JavaScript类与面向对象编程
- Argspect-0.0.1版本Python包发布与使用说明
- OpenNetAdmin v09.07.15 PHP项目源码下载
- 掌握Node.js: 构建高性能Web服务器与应用程序
- Matlab矢量绘图工具:polarG函数使用详解
- 实现Vue.js中PDF文件的签名显示功能
- 开源项目PSPSolver:资源约束调度问题求解器库
- 探索vwru系统:大众的虚拟现实招聘平台
- 深入理解cJSON:案例与源文件解析
- 多边形扩展算法在MATLAB中的应用与实现
- 用React类组件创建迷你待办事项列表指南
- Python库setuptools-58.5.3助力高效开发
- fmfiles工具:在MATLAB中查找丢失文件并列出错误
- 老枪二级域名系统PHP源码简易版发布
- 探索DOSGUI开源库:C/C++图形界面开发新篇章
