SparkStreaming:实时流处理框架详解与实战
80 浏览量
更新于2024-08-30
收藏 239KB PDF 举报
SparkStreaming编程讲解
Spark Streaming 是Apache Spark核心API之一,专为实时流数据处理设计,它构建在Spark之上,利用其强大的批处理能力扩展到了流数据处理场景。Spark Streaming的基本思想是将连续的流数据切分为小的时间窗口(通常几秒钟),这些窗口内的数据被以批处理的方式进行处理,确保了实时性和容错性。
1. **Spark Streaming定义**:
Spark Streaming是Spark平台的一个组件,它允许开发者以批处理模型处理实时数据流。它通过将无限数据流划分为一系列短时间窗口(如每秒或每毫秒),将实时数据转换成一系列批处理任务,这样既能利用Spark的高效执行引擎(延迟在100毫秒级别),又能保持实时计算的能力。
2. **数据源支持**:
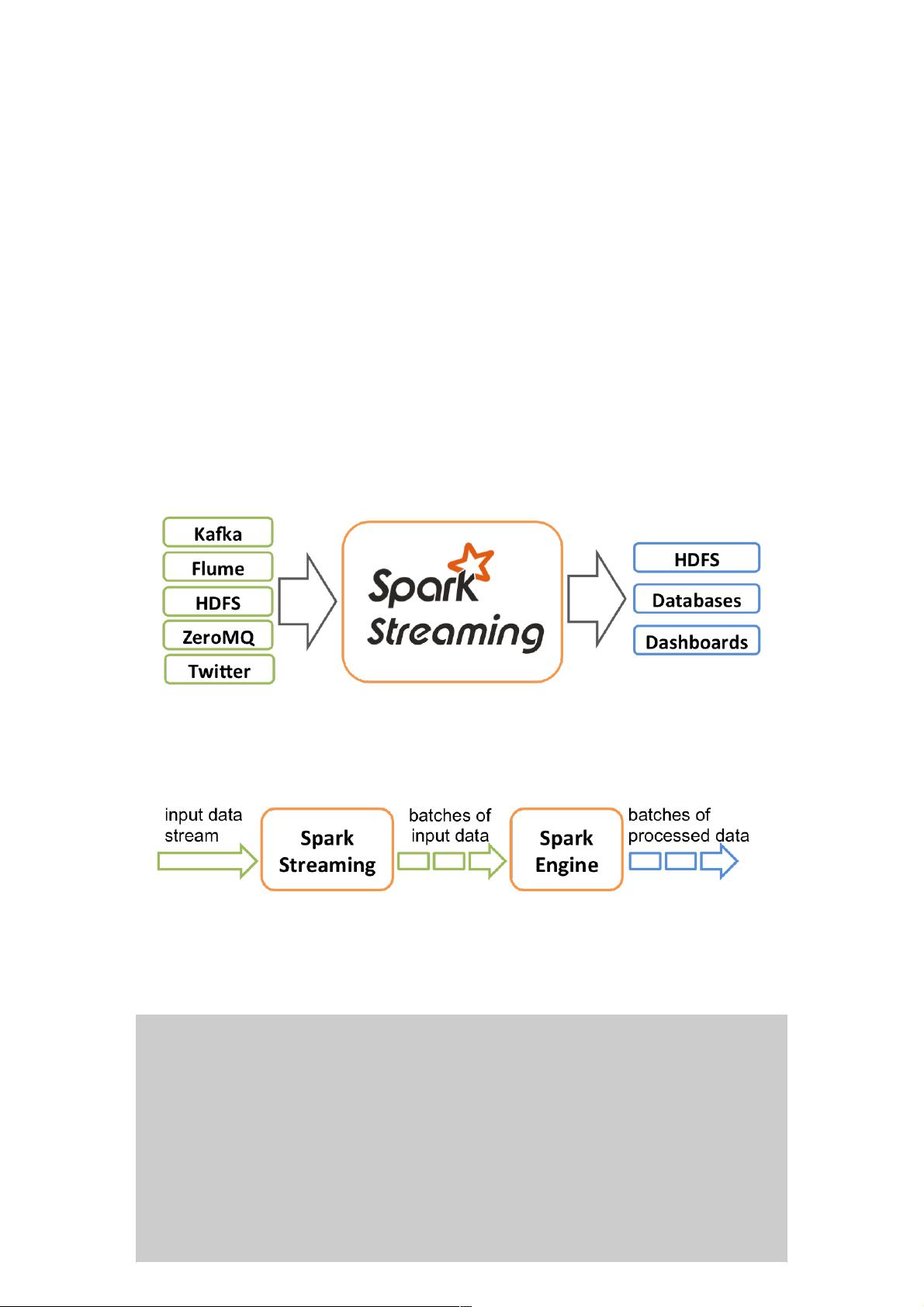
Spark Streaming能够处理多种类型的数据源,包括:
- Kafka: 作为分布式消息队列,提供了一种可靠的消息传输方式。
- Flume: 一个分布式、可靠、可扩展的海量日志收集系统。
- Twitter: 支持实时获取Twitter上的推文数据。
- ZeroMQ: 高性能的实时通信库,适用于数据交换和消息传递。
- TCPSocket: 直接接收来自网络的TCP数据流。
它提供了丰富的API接口,如map、reduce、join、window等,以及Spark的机器学习和图形处理库,使得数据处理更为灵活。
3. **DStream操作**:
DStream(Distributed Stream)是Spark Streaming中的核心概念,它是连续的RDD序列,代表数据流中的每个时间窗口。开发者可以对DStream进行以下两种主要操作:
- **Transformation操作**:如map、flatMap、filter等,这些操作会生成新的DStream,但不改变原始数据。
- **Action操作**:如count、reduceByKey、saveAsTextFile等,这些操作会触发实际的数据处理,返回结果并可能持久化到存储系统。
4. **工作流程**:
Spark Streaming的工作流程包含以下几个步骤:
- 数据接收:从指定的数据源读取实时数据,并按照设定的时间间隔(例如每秒)形成数据批次。
- 批次处理:将接收到的数据分批发送给Spark Engine进行计算。
- 结果生成:Spark Engine处理完数据后,生成相应批次的结果。
5. **示例代码**:
通过`StreamingContext`实例,我们可以创建和操作DStream。例如,创建一个每秒一个批次的`StreamingContext`,从socket接收文本数据,然后对数据进行分割、统计单词出现次数等操作。
Spark Streaming是一个强大的工具,它结合了Spark的批处理能力和实时数据处理的优势,广泛应用于日志分析、社交网络监控、金融交易处理等各种需要实时响应的场景。通过灵活的API和容错机制,Spark Streaming简化了实时流数据的处理流程,极大地提高了数据处理的效率和可靠性。
SparkStreaming编程讲解编程讲解
问题导读:
1.什么是Spark Streaming?
2.Spark Streaming可以接受那些数据源?
3.Dstream,我们可以进行哪两种操作?
在看spark Streaming,我们需要首先知道什么是Spark streaming?
Spark streaming: 构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以类似
batch批量处理的方式来处理这小部分数据。Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎
(100ms+)可以用于实时计算,另一方面相比基于Record的其它处理框架(如Storm),RDD数据集更容易做高效的容错处
理。此外小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法。方便了一些需要历史数据和实时数据联合
分析的特定应用场合。
Overview
Spark Streaming属于Spark的核心api,它支持高吞吐量、支持容错的实时流数据处理。
它可以接受来自Kafka, Flume, Twitter, ZeroMQ和TCP Socket的数据源,使用简单的api函数比如 map, reduce, join, window
等操作,还可以直接使用内置的机器学习算法、图算法包来处理数据。
它的工作流程像下面的图所示一样,接受到实时数据后,给数据分批次,然后传给Spark Engine处理最后生成该批次的结果。
它支持的数据流叫Dstream,直接支持Kafka、Flume的数据源。Dstream是一种连续的RDDs,下面是一个例子帮助大家理解
Dstream。
A Quick Example
下载后可阅读完整内容,剩余6页未读,立即下载
2021-01-07 上传
2022-07-15 上传
2021-01-07 上传
2019-01-21 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-01-23 上传

weixin_38547035
- 粉丝: 3
- 资源: 920
 我的内容管理
展开
我的内容管理
展开







最新资源
- SSM动力电池数据管理系统源码及数据库详解
- R语言桑基图绘制与SCI图输入文件代码分析
- Linux下Sakagari Hurricane翻译工作:cpktools的使用教程
- prettybench: 让 Go 基准测试结果更易读
- Python官方文档查询库,提升开发效率与时间节约
- 基于Django的Python就业系统毕设源码
- 高并发下的SpringBoot与Nginx+Redis会话共享解决方案
- 构建问答游戏:Node.js与Express.js实战教程
- MATLAB在旅行商问题中的应用与优化方法研究
- OMAPL138 DSP平台UPP接口编程实践
- 杰克逊维尔非营利地基工程的VMS项目介绍
- 宠物猫企业网站模板PHP源码下载
- 52简易计算器源码解析与下载指南
- 探索Node.js v6.2.1 - 事件驱动的高性能Web服务器环境
- 找回WinSCP密码的神器:winscppasswd工具介绍
- xctools:解析Xcode命令行工具输出的Ruby库
