SparkStreaming实时流处理详解
130 浏览量
更新于2024-08-28
收藏 239KB PDF 举报
"SparkStreaming编程讲解"
SparkStreaming是Apache Spark项目的一个组件,专门设计用于处理实时数据流。它是建立在Spark核心API之上的,利用Spark的低延迟执行引擎,能够以毫秒级延迟处理实时数据。SparkStreaming的核心概念是将持续不断的数据流分解成一系列短暂的、离散的数据块,这些数据块被称为Discretized Streams(Dstreams)。这种时间切片的方式允许SparkStreaming以类似批处理的模式来处理实时数据,从而结合了实时计算和批量处理的优势。
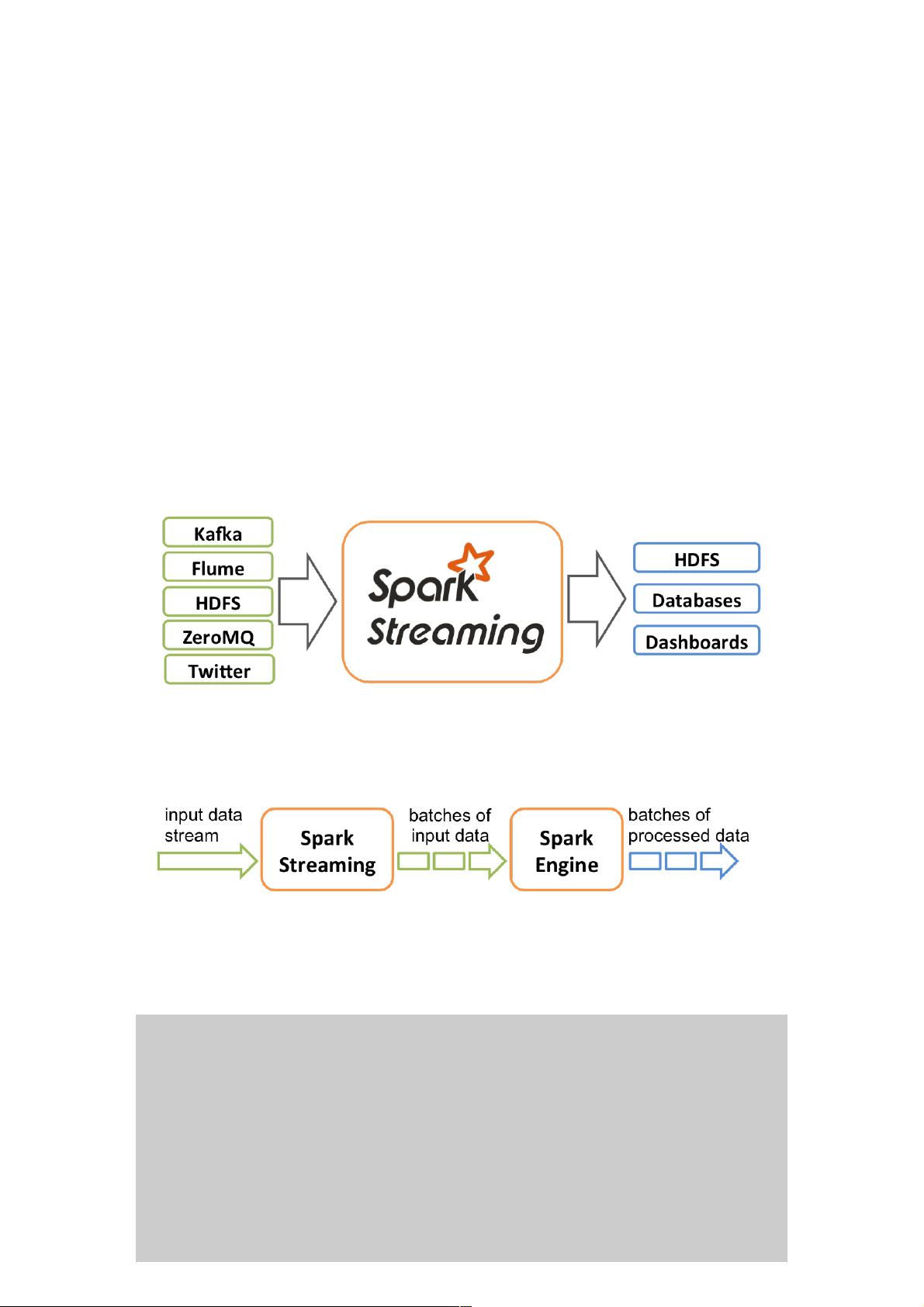
在SparkStreaming中,Dstream是处理数据流的基本单元,它实际上是一系列连续的Resilient Distributed Datasets (RDDs)的序列。RDD是Spark的基础数据结构,具有容错能力。Dstream可以通过多种方式从各种数据源接收数据,例如Kafka、Flume、Twitter、ZeroMQ以及TCP套接字。用户可以对Dstream进行多种操作,如map、reduce、join和window等,以实现数据转换和聚合。
SparkStreaming的一个关键特性是其容错能力。由于它基于RDD,可以利用Spark的检查点和血统追踪机制,当有数据丢失或节点故障时,系统能自动恢复。此外,通过使用小批量处理,SparkStreaming能够在处理实时数据的同时,无缝地处理历史数据,这使得它特别适合需要历史和实时数据融合的应用场景。
SparkStreaming的工作流程可以概括为:数据源接收到实时数据后,这些数据被划分为一系列小批次(例如,每秒一个批次),然后这些批次数据被送入Spark Engine进行处理,最终生成每个批次的处理结果。这个过程确保了系统的高吞吐量和低延迟。
以下是一个简单的SparkStreaming示例代码:
```scala
// 创建StreamingContext,设置批次时间为1秒
val ssc = new StreamingContext(sparkConf, Seconds(1))
// 从指定服务器IP和端口创建一个Dstream
val lines = ssc.socketTextStream(serverIP, serverPort)
// 对每行数据进行分割操作
val words = lines.flatMap(_.split(""))
// 统计单词数量
val pairs = words.map(word => (word, 1))
val wordCounts = pairs.reduceByKey(_ + _)
// 开始执行计算
wordCounts.print()
```
在这个例子中,`socketTextStream`函数创建了一个从指定TCP服务器接收文本数据的Dstream。然后,`flatMap`和`split`操作将每一行数据拆分成单独的单词,`map`函数为每个单词分配一个计数值1,`reduceByKey`则将相同单词的计数值相加,实现单词计数。最后,`print`操作将结果输出。
通过这种方式,SparkStreaming提供了一种简单而强大的方法来处理实时数据流,同时利用Spark的强大功能进行复杂的数据处理和分析。它的灵活性和易用性使其成为实时数据分析领域的一个重要工具。
SparkStreaming编程讲解编程讲解
问题导读:
1.什么是Spark Streaming?
2.Spark Streaming可以接受那些数据源?
3.Dstream,我们可以进行哪两种操作?
在看spark Streaming,我们需要首先知道什么是Spark streaming?
Spark streaming: 构建在Spark上处理Stream数据的框架,基本的原理是将Stream数据分成小的时间片断(几秒),以类似
batch批量处理的方式来处理这小部分数据。Spark Streaming构建在Spark上,一方面是因为Spark的低延迟执行引擎
(100ms+)可以用于实时计算,另一方面相比基于Record的其它处理框架(如Storm),RDD数据集更容易做高效的容错处
理。此外小批量处理的方式使得它可以同时兼容批量和实时数据处理的逻辑和算法。方便了一些需要历史数据和实时数据联合
分析的特定应用场合。
Overview
Spark Streaming属于Spark的核心api,它支持高吞吐量、支持容错的实时流数据处理。
它可以接受来自Kafka, Flume, Twitter, ZeroMQ和TCP Socket的数据源,使用简单的api函数比如 map, reduce, join, window
等操作,还可以直接使用内置的机器学习算法、图算法包来处理数据。
它的工作流程像下面的图所示一样,接受到实时数据后,给数据分批次,然后传给Spark Engine处理最后生成该批次的结果。
它支持的数据流叫Dstream,直接支持Kafka、Flume的数据源。Dstream是一种连续的RDDs,下面是一个例子帮助大家理解
Dstream。
A Quick Example
下载后可阅读完整内容,剩余6页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
2021-01-07 上传
2019-01-21 上传
点击了解资源详情
2019-01-23 上传
2015-11-09 上传
2020-07-02 上传

weixin_38700409
- 粉丝: 5
- 资源: 953
 我的内容管理
展开
我的内容管理
展开







