HBase入门:海量数据的列式存储解析
需积分: 3 114 浏览量
更新于2024-06-13
收藏 2.95MB PDF 举报
"拉勾的HBase课件涵盖了HBase的基础知识、特点以及应用,适合学习者深入了解这个分布式列式数据库系统。"
HBase是基于Google BigTable设计思想开发的一个开源的分布式非关系型数据库,主要适用于处理和存储海量数据。其核心特性包括列式存储、海量存储、极易扩展、高并发读写、数据的多版本以及稀疏性。
1. 列式存储:与传统的关系型数据库不同,HBase采用列式存储方式,这意味着数据按列族组织,每个列族可以包含多个列。这种存储方式对于那些需要频繁读取特定列的情况非常有利,因为它可以减少不必要的磁盘I/O,尤其是在数据稀疏或只需要访问部分列的情况下,能显著减少存储空间占用。
2. 海量存储:HBase利用Hadoop的HDFS作为底层存储,可以处理PB级别的数据,非常适合大数据应用场景。
3. 极易扩展:当存储需求增大时,只需增加DataNode节点即可扩展HBase集群,保持系统的高可用性和稳定性。
4. 高并发:HBase设计用于处理高并发的读写操作,支持大量并发用户同时访问。
5. 稀疏性:HBase允许表中存在大量的空值,这些空值不会占用存储空间,增强了数据存储的灵活性。
6. 数据多版本:每个记录可以有多个版本,版本通常由时间戳标识,这使得数据的历史版本查询成为可能。
7. 数据类型单一:所有数据在HBase中以字节数组形式存储,不支持复杂的数据类型,但可以通过编码技术实现对多种数据类型的存储。
HBase的应用广泛,包括但不限于:
- 交通领域:用于存储船舶GPS信息,处理大量实时定位数据。
- 金融行业:存储消费记录、贷款信息和信用卡还款数据,便于数据分析和风险控制。
- 电商行业:处理交易信息、物流数据和用户浏览行为,提供个性化推荐和服务。
- 电信业务:存储通话记录,支持计费和分析。
HBase的数据模型包括行(Row)、列族(Column Family)、列(Column)、版本(Version),并且其逻辑架构包括HMaster和HRegionServer等关键组件。HMaster负责Region的分配、集群负载均衡和元数据管理,而HRegionServer则实际处理数据的读写操作。Zookeeper在其中起到关键作用,提供高可用性保障,保存元数据信息,并监控HMaster和HRegionServer的状态。
HBase是一种适合于处理大规模、高并发、需要快速查询的场景的数据库系统,尤其适用于需要对海量明细数据进行实时分析的业务。
修改 hbase-site.xml
修改regionservers文件
hbase的conf目录下创建文件backup-masters (Standby Master)
(6)配置hbase的环境变量
(7)分发hbase目录和环境变量到其他节点
(8)让所有节点的hbase环境变量生效
在所有节点执行 source /etc/profile
HBase集群的启动和停止
前提条件:先启动hadoop和zk集群
启动HBase:start-hbase.sh
停止HBase:stop-hbase.sh
#添加java环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_231
#指定使用外部的zk集群
export HBASE_MANAGES_ZK=FALSE
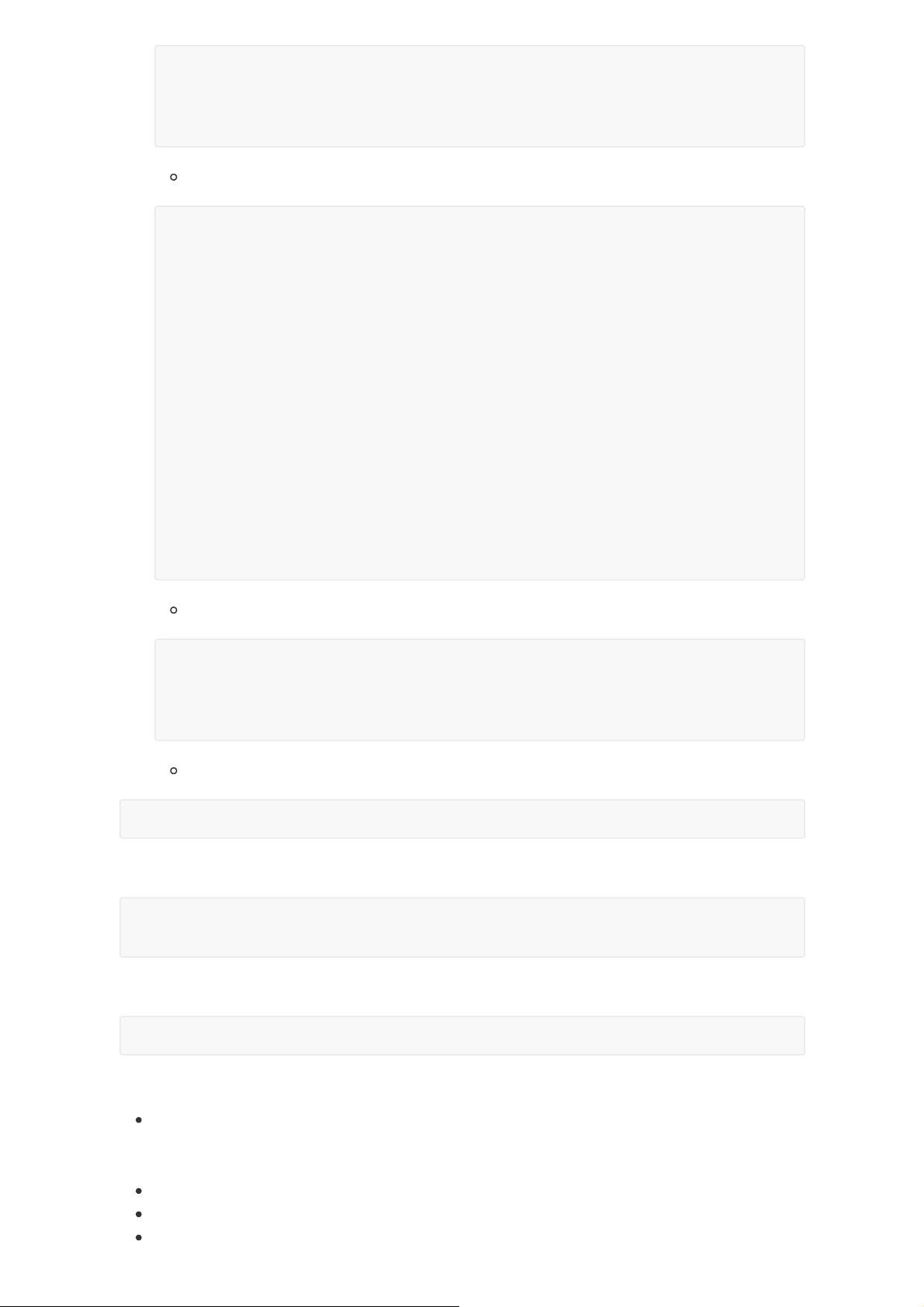
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://linux121:9000/hbase</value>
</property>
<!-- 指定hbase是分布式的 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zk的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>linux121:2181,linux122:2181,linux123:2181</value>
</property>
</configuration>
#指定regionserver节点
linux121
linux122
linux123
linux122
export HBASE_HOME=/opt/lagou/servers/hbase-1.3.1
export PATH=$PATH:$HBASE_HOME/bin
rsync-script hbase-1.3.1
剩余28页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2020-02-19 上传
2022-05-02 上传
2022-06-14 上传
2018-10-12 上传
2019-04-05 上传









