Spark核心技术解析:分布式编程与YARN整合
162 浏览量
更新于2024-08-27
收藏 431KB PDF 举报
"Spark知识体系完整解读,涵盖了Spark的基础概念、Spark在YARN上的运行机制以及相关过程分析。"
Spark是大数据处理领域的重要框架,它以其高效、易用的特性深受开发者喜爱。作为BDAS(Big Data Analytics Stack)的核心组件,Spark提供了比MapReduce更丰富的计算模型,包括filter、join、groupByKey等操作,使得数据处理更为灵活。Spark引入了一种名为弹性分布式数据集(RDD)的数据抽象,RDD具有容错性和并行性,能够高效地在集群中进行计算。
Spark的设计目标是速度和通用性,它在内存计算中实现了显著的性能提升,通过缓存数据在内存中,避免了频繁的磁盘读写。同时,Spark提供了多种编程接口,包括Java、Python、R以及其原生的Scala API,这些API借鉴了Scala的函数式编程思想,使得开发过程更为简洁和高效。
Spark运行在YARN(Hadoop的资源管理器)上时,作业提交过程如下:
1. 客户端首先初始化yarnClient,然后根据YARN配置提交作业,检查集群资源是否满足需求。
2. 设置作业资源和环境,包括Application的Staging目录、本地资源上传、环境变量以及Container启动上下文。
3. 提交Application到YARN,包括设置应用名称、队列、AM(ApplicationMaster)资源需求,并指定作业类型为Spark。
4. YARN接收到作业后,启动ApplicationMaster,设置环境变量,并通过amClient与ResourceManager通信。
5. ApplicationMaster负责任务调度,启动Driver线程执行用户代码,同时SparkUI在适当的时候启动,用于监控和展示作业状态。
在整个过程中,一旦作业提交,客户端的角色就完成了,作业的实际运行完全依赖于YARN集群,结果通常会保存到HDFS或者通过日志系统记录,确保了作业的持续性和可追溯性。
Spark不仅仅是一个计算框架,它还支持多个组件,如Spark SQL用于结构化数据处理,Spark Streaming用于实时流处理,MLlib提供了机器学习算法,GraphX则处理图计算。这些组件共同构建了Spark强大的数据分析生态系统,使得Spark成为处理大规模数据的首选工具之一。通过深入理解Spark的运行机制和API,开发者可以更好地优化作业性能,充分利用集群资源,解决复杂的数据处理问题。
Spark知识体系完整解读知识体系完整解读
Spark简介
Spark是整个BDAS的核心组件,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map 函数和reduce函数及计算
模型,还提供更为丰富的算子,如filter、join、groupByKey等。是一个用来实现快速而同用的集群计算的平台。 Spark将分布
式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供
API。其底层采用Scala这种函数式语言书写而成,并且所提供的API深度借鉴Scala函数式的编程思想,提供与Scala类似的编
程接口
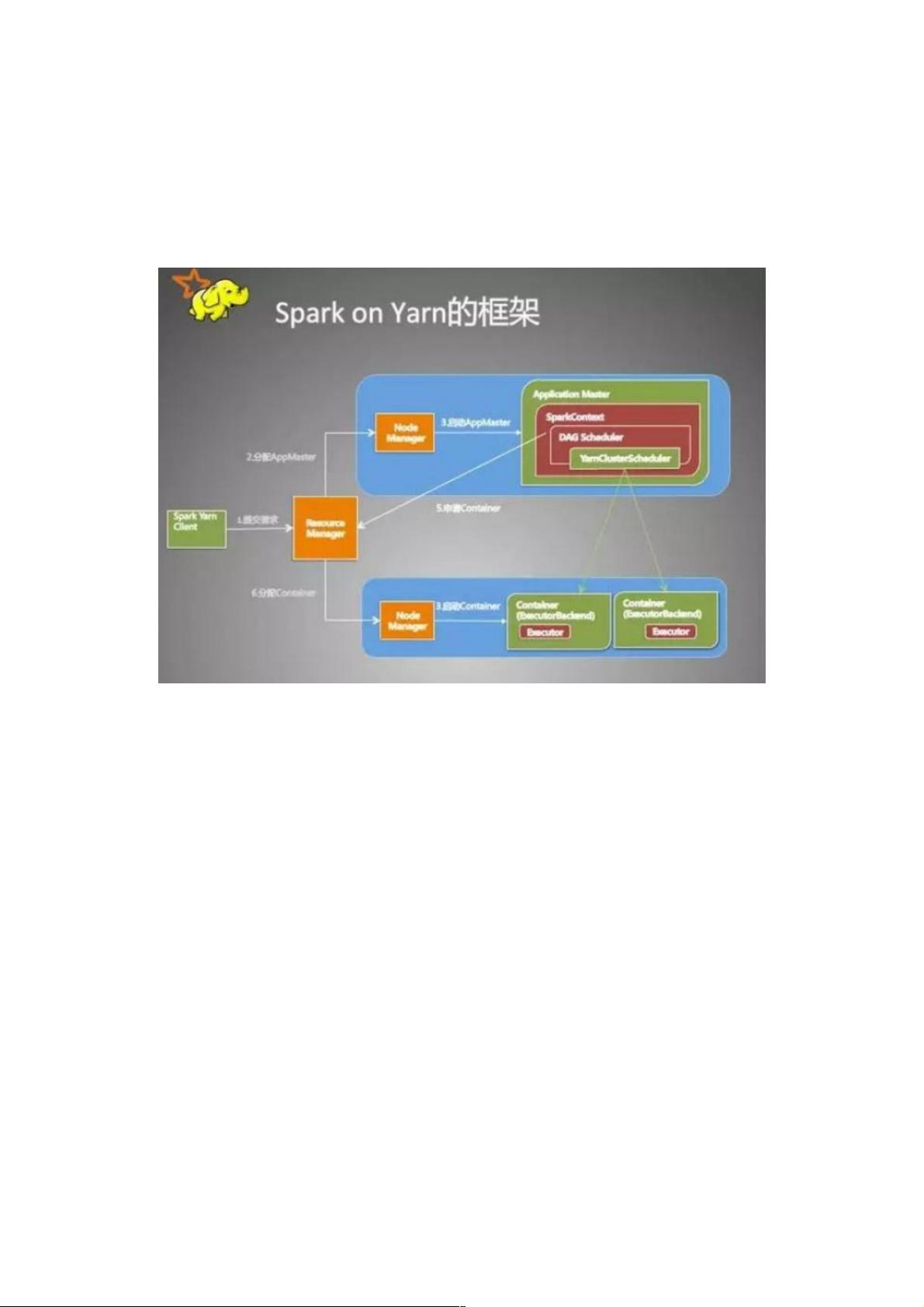
Sparkon Yarn
从用户提交作业到作业运行结束整个运行期间的过程分析。
一、客户端进行操作
1.根据yarnConf来初始化yarnClient,并启动yarnClient
2.创建客户端Application,并获取Application的ID,进一步判断集群中的资源是否满足executor和ApplicationMaster申请的资
源,如果不满足则抛出IllegalArgumentException;
3. 设置资源、环境变量:其中包括了设置Application的Staging目录、准备本地资源(jar文件、log4j.properties)、设置
Application其中的环境变量、创建Container启动的Context等;
4. 设置Application提交的Context,包括设置应用的名字、队列、AM的申请的Container、标记该作业的类型为Spark;
5. 申请Memory,并最终通过yarnClient.submitApplication向ResourceManager提交该Application。
当作业提交到YARN上之后,客户端就没事了,甚至在终端关掉那个进程也没事,因为整个作业运行在YARN集群上进行,运
行的结果将会保存到HDFS或者日志中。
二、提交到YARN集群,YARN操作
1.运行ApplicationMaster的run方法;
2.设置好相关的环境变量。
3.创建amClient,并启动;
4.在Spark UI启动之前设置Spark UI的AmIpFilter;
5.在startUserClass函数专门启动了一个线程(名称为Driver的线程)来启动用户提交的Application,也就是启动了Driver。在
Driver中将会初始化SparkContext;
6.等待SparkContext初始化完成,最多等待spark.yarn.applicationMaster.waitTries次数(默认为10),如果等待了的次数超
过了配置的,程序将会退出;否则用SparkContext初始化yarnAllocator;
下载后可阅读完整内容,剩余5页未读,立即下载
2020-07-26 上传
2018-11-19 上传
2023-03-16 上传
2017-12-18 上传
2021-02-04 上传
2018-12-28 上传
2017-11-20 上传
点击了解资源详情

weixin_38519387
- 粉丝: 3
- 资源: 931
 我的内容管理
展开
我的内容管理
展开







最新资源
- pacific
- holbertonschool访谈
- 易语言DOS命令net的使用源码-易语言
- weather-app:使用Flask和OpenWeather API的Weather App
- ehchao88.github.io
- IT202-Spring2021-project2
- WWTBAM
- 易语言代码管理系统源码-易语言
- 行动中的春天:我在“行动中的春天”(第5版)中的练习中定义的“ Taco Cloud”应用程序的实现,Craig Walls,曼宁出版社
- Reach.io:亲密,故意和真实联系的应用程序
- 行业文档-设计装置-一种既有生土建筑土墙体木柱木梁加固装置.zip
- abesamma.github.io:您需要了解的所有关于我的信息
- magang-iris:IRIS源代码和实习进度的文档
- Recep_field_analysis
- 少儿涂色-易语言
- seriesflix
