Spark:大数据分布式编程框架详解与YARN集成
102 浏览量
更新于2024-08-28
收藏 431KB PDF 举报
Spark知识体系完整解读
Spark是Apache软件基金会的开源项目,是基于内存计算的大数据处理框架,它在Big Data As-a-Service (BDAS)生态系统中扮演着核心角色。相比于传统的MapReduce模型,Spark提供了更快的数据处理速度,通过使用弹性分布式数据集(RDDs,Resilient Distributed Datasets)作为数据处理的基本单元,它支持更高级别的抽象操作,如filter、join、groupByKey等,这使得开发人员能够编写更为简洁且高效的代码。
Spark底层技术选用了Scala语言,得益于其函数式编程特性,Spark的API设计深受Scala编程思想的影响。Scala的高阶函数和闭包使得在Spark中编写并行和分布式计算任务更加直观和高效。同时,Spark的API提供了与Scala相似的接口,使得熟悉Scala的开发者能快速上手。
在Spark on YARN部署模式下,用户提交作业的流程涉及以下几个关键步骤:
1. 客户端操作:
- 用户首先通过YARN客户端(yarnClient)初始化,检查集群资源是否满足申请的Executor和ApplicationMaster(AM)所需的资源。
- 创建并配置Application,设置资源(如内存)、环境变量(如Staging目录、本地资源、日志配置等),并指定作业类型为Spark。
- 通过yarnClient提交Application,提交后客户端无需保持连接,作业将在YARN上独立运行。
2. YARN集群操作:
- ApplicationMaster启动时,会执行run方法,设置必要的环境变量。
- 创建一个amClient,并启动与ResourceManager的通信。
- 在SparkUI启动前,设置特定的AmIpFilter,确保安全访问。
- 通过Driver线程启动用户提供的用户类,这是作业实际执行的地方。
整个过程中,Spark与YARN协同工作,将用户的任务切分成可以在集群节点上并行执行的任务,利用内存加速数据处理,并通过YARN的资源管理和调度功能确保任务的顺利执行。Spark的可扩展性和高性能使得它成为现代大数据处理不可或缺的一部分,尤其是在实时流处理和机器学习等领域。
Spark知识体系完整解读知识体系完整解读
Spark简介
Spark是整个BDAS的核心组件,是一个大数据分布式编程框架,不仅实现了MapReduce的算子map 函数和reduce函数及计算
模型,还提供更为丰富的算子,如filter、join、groupByKey等。是一个用来实现快速而同用的集群计算的平台。 Spark将分布
式数据抽象为弹性分布式数据集(RDD),实现了应用任务调度、RPC、序列化和压缩,并为运行在其上的上层组件提供
API。其底层采用Scala这种函数式语言书写而成,并且所提供的API深度借鉴Scala函数式的编程思想,提供与Scala类似的编
程接口
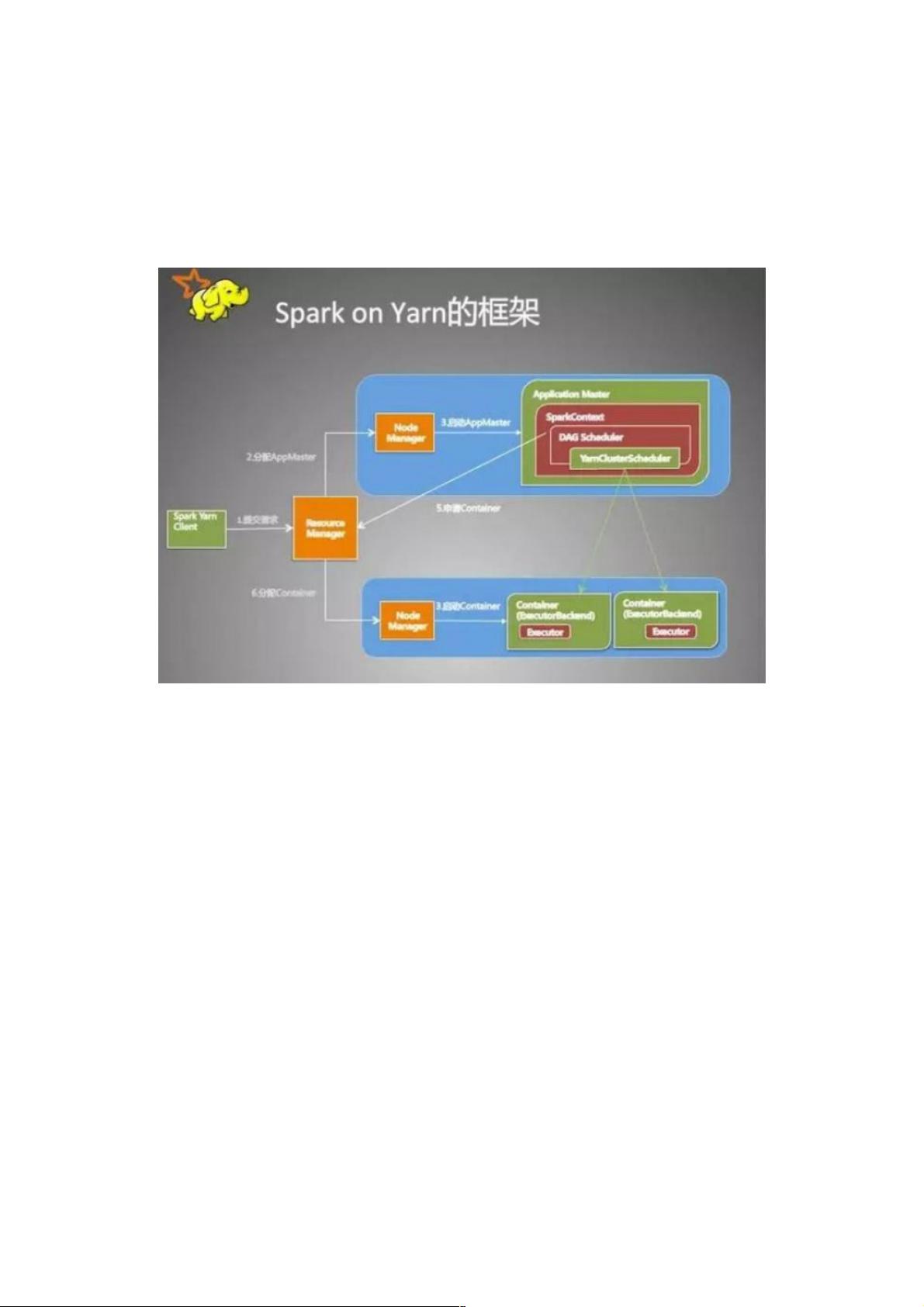
Sparkon Yarn
从用户提交作业到作业运行结束整个运行期间的过程分析。
一、客户端进行操作
1.根据yarnConf来初始化yarnClient,并启动yarnClient
2.创建客户端Application,并获取Application的ID,进一步判断集群中的资源是否满足executor和ApplicationMaster申请的资
源,如果不满足则抛出IllegalArgumentException;
3. 设置资源、环境变量:其中包括了设置Application的Staging目录、准备本地资源(jar文件、log4j.properties)、设置
Application其中的环境变量、创建Container启动的Context等;
4. 设置Application提交的Context,包括设置应用的名字、队列、AM的申请的Container、标记该作业的类型为Spark;
5. 申请Memory,并最终通过yarnClient.submitApplication向ResourceManager提交该Application。
当作业提交到YARN上之后,客户端就没事了,甚至在终端关掉那个进程也没事,因为整个作业运行在YARN集群上进行,运
行的结果将会保存到HDFS或者日志中。
二、提交到YARN集群,YARN操作
1.运行ApplicationMaster的run方法;
2.设置好相关的环境变量。
3.创建amClient,并启动;
4.在Spark UI启动之前设置Spark UI的AmIpFilter;
5.在startUserClass函数专门启动了一个线程(名称为Driver的线程)来启动用户提交的Application,也就是启动了Driver。在
Driver中将会初始化SparkContext;
6.等待SparkContext初始化完成,最多等待spark.yarn.applicationMaster.waitTries次数(默认为10),如果等待了的次数超
过了配置的,程序将会退出;否则用SparkContext初始化yarnAllocator;
下载后可阅读完整内容,剩余5页未读,立即下载
2020-07-26 上传
2023-03-16 上传
2021-02-04 上传
2018-12-28 上传
2017-11-20 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

weixin_38742421
- 粉丝: 2
- 资源: 954
 我的内容管理
展开
我的内容管理
展开







最新资源
- 构建基于Django和Stripe的SaaS应用教程
- Symfony2框架打造的RESTful问答系统icare-server
- 蓝桥杯Python试题解析与答案题库
- Go语言实现NWA到WAV文件格式转换工具
- 基于Django的医患管理系统应用
- Jenkins工作流插件开发指南:支持Workflow Python模块
- Java红酒网站项目源码解析与系统开源介绍
- Underworld Exporter资产定义文件详解
- Java版Crash Bandicoot资源库:逆向工程与源码分享
- Spring Boot Starter 自动IP计数功能实现指南
- 我的世界牛顿物理学模组深入解析
- STM32单片机工程创建详解与模板应用
- GDG堪萨斯城代码实验室:离子与火力基地示例应用
- Android Capstone项目:实现Potlatch服务器与OAuth2.0认证
- Cbit类:简化计算封装与异步任务处理
- Java8兼容的FullContact API Java客户端库介绍
