Sharding JDBC:数据分片技术实践与兼容性解析
需积分: 36 131 浏览量
更新于2024-08-08
收藏 410KB PDF 举报
Sharding JDBC 是一种轻量级的 Java 数据库分片框架,专为解决大型数据库系统中单表数据量过大导致性能下降的问题而设计。它作为客户端组件,无需额外部署,以jar包形式集成,使得在保持代码侵入性低的同时,实现数据的自动分库分表,显著减轻单点压力。Sharding JDBC 支持多种常见的 ORM 框架(如 JPA、Hibernate 和 Mybatis),以及广泛的数据库连接池(如 DBCP、C3P0 等),具有高度的灵活性和兼容性。
在使用 Sharding JDBC 时,首先要理解的核心概念包括:
1. **逻辑表**:逻辑表是指在应用程序中定义的表,通常基于业务逻辑进行水平拆分,如将订单表 t_order 分成 t_order_0 到 t_order_9,虽然实际存储在不同的物理表中,但在用户看来它们是同一个逻辑表。
2. **真实表**:每个逻辑表在分布式数据库中对应一个或多个真实的物理表,例如上述例子中的 t_order_0 到 t_order_9。
3. **数据节点**:数据节点是数据分片的基本单元,由数据源名和具体表名构成,如 ds_0.t_order_0,表示这个数据节点负责处理来自 ds_0 的 t_order_0 表的数据。
4. **分片键**:这是决定数据如何在不同数据节点间分布的关键字段,如订单表的主键尾数,通过取模运算进行分片。如果没有显式指定分片键,查询将默认为全路由,效率较低。
5. **分片算法**:Sharding JDBC 提供了丰富的分片算法,如基于范围(>=、<=)、比较(>、<)、逻辑运算(BETWEEN、IN)的规则,允许开发者自定义实现更复杂的分片策略,以满足不同场景的需求。
6. **内置分片算法**:目前,Sharding JDBC 内置了四种分片算法,包括哈希、范围、列表和广播分片,每种算法都有其适用场景,开发者可以根据实际项目选择最合适的。
通过Sharding JDBC,项目开发者可以简化分库分表的实现过程,仅需在配置层面定义数据分片规则,无需修改大量代码或SQL语句,从而极大地提高系统的可扩展性和性能。这在处理大数据量、高并发场景下,能够有效降低数据库访问压力,提升整体系统的响应速度和稳定性。
前言
最近在项目中,实现需求时候,发现做有些表的数据量预计会很大,由于关系型数据库大多采用B+树类
型的索引,在数据量超过阈值的情况下,索引深度的增加也将使得磁盘访问的IO次数增加,进而导致查
询性能的下降,同时,高并发访问请求也使得集中式数据库成为系统的最大瓶颈。因此,借助了一些分
库分表的中间件,来实现自动化分库分表的实现,这里采用Sharding JDBC 来实现数据分片。
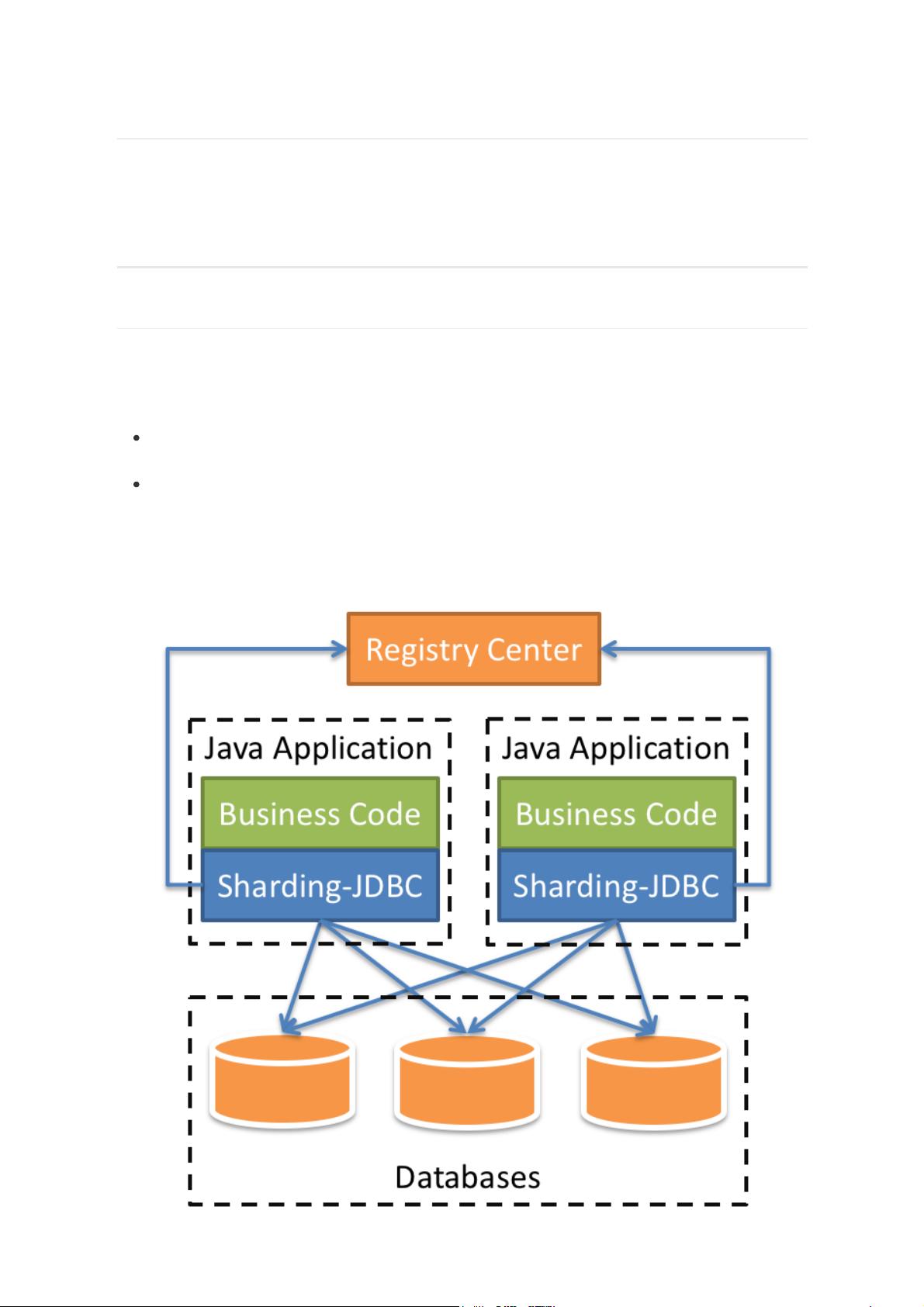
Sharding-JDBC介绍
Sharding-JDBC 是一款轻量级 Java 框架,以 jar 包形式提供服务,是属于客户端产品不需要额外部署,
它相当于是个增强版的 JDBC 驱动;相比之下像 Mycat 这类需要单独的部署服务的服务端产品,就稍显
复杂了。
sharding-jdbc的兼容性也非常强大,适用于任何基于 JDBC 的 ORM 框架,如:JPA,
Hibernate,Mybatis,Spring JDBC Template 或直接使用的 JDBC。
完美兼容任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP,Druid, HikariCP 等,几乎
对所有关系型数据库都支持。
不难发现确实是比较强大的一款工具,而且它对项目的侵入性很小,几乎不用做任何代码层的修改,也
无需修改 SQL 语句,只需配置待分库分表的数据表即可。
下载后可阅读完整内容,剩余5页未读,立即下载
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
点击了解资源详情
2023-03-31 上传

夜风_BLOG
- 粉丝: 53
- 资源: 24
 我的内容管理
展开
我的内容管理
展开







最新资源
- Hadoop生态系统与MapReduce详解
- MDS系列三相整流桥模块技术规格与特性
- MFC编程:指针与句柄获取全面解析
- LM06:多模4G高速数据模块,支持GSM至TD-LTE
- 使用Gradle与Nexus构建私有仓库
- JAVA编程规范指南:命名规则与文件样式
- EMC VNX5500 存储系统日常维护指南
- 大数据驱动的互联网用户体验深度管理策略
- 改进型Booth算法:32位浮点阵列乘法器的高速设计与算法比较
- H3CNE网络认证重点知识整理
- Linux环境下MongoDB的详细安装教程
- 压缩文法的等价变换与多余规则删除
- BRMS入门指南:JBOSS安装与基础操作详解
- Win7环境下Android开发环境配置全攻略
- SHT10 C语言程序与LCD1602显示实例及精度校准
- 反垃圾邮件技术:现状与前景
