Apache Flink:统一流批处理的特性与架构解析
152 浏览量
更新于2024-08-30
收藏 691KB PDF 举报
Apache Flink是一个强大的开源计算平台,其核心优势在于它的兼容性和灵活性。Flink的设计目标是统一处理流处理和批处理,打破了传统开源方案中将两者视为独立应用类型的限制。Flink Runtime是其基础组件,提供了统一的运行环境,使得开发者可以使用相同的工具和技术处理不同类型的业务场景。
流处理方面,Flink的特点包括:
1. 高吞吐量与低延迟:Flink设计初衷就是追求实时性,能处理大量数据流并保持极低的响应时间,这对于许多实时分析和监控系统至关重要。
2. 事件时间窗口:Flink支持基于事件时间的窗口操作,允许根据数据到达的时间而非事件的生成时间进行聚合和分析,这对于时序数据处理非常关键。
3. Exactly-once语义:Flink提供了有状态计算的Exactly-once保证,确保每个事件只被处理一次,即使在系统故障后也能恢复到正确状态。
4. 灵活的窗口操作:Flink支持多种窗口类型,如time-based、count-based、session-based和data-driven,满足不同业务场景的需求。
5. Backpressure机制:Flink采用轻量级的持续流模型,能够有效地管理流量,防止下游任务因处理速度慢而过载。
6. 容错性:通过分布式快照技术,Flink可以在运行时进行恢复,提高系统的可用性和可靠性。
7. 批处理和流处理一体:Flink运行时同时支持Batch on Streaming和Streaming处理,用户可以根据需要灵活切换。
8. 内存管理优化:Flink在JVM内进行了内存优化,减少不必要的内存消耗和垃圾回收,提升性能。
9. 迭代计算:Flink还支持迭代计算,对于需要重复处理的数据集或模式匹配,这是一大优势。
10. 自动优化:Flink通过智能优化机制,避免在不必要的地方进行排序和shuffle操作,提高执行效率。
API支持方面,Flink为不同类型的应用提供了专用接口:
- 对于流数据处理,提供了DataStream API,易于处理实时数据的生产者和消费者。
- 对于批处理,提供了DataSet API,支持Java和Scala,简化了大规模数据的批处理流程。
此外,Flink还集成了一系列机器学习库(FlinkML),使得数据科学家能够轻松地在流处理和批处理环境中进行模型训练和部署。
Apache Flink凭借其独特的优势和全面的功能,成为现代大数据处理领域的一个重要选项,尤其适合那些需要实时性、低延迟以及强大扩展性的应用场景。
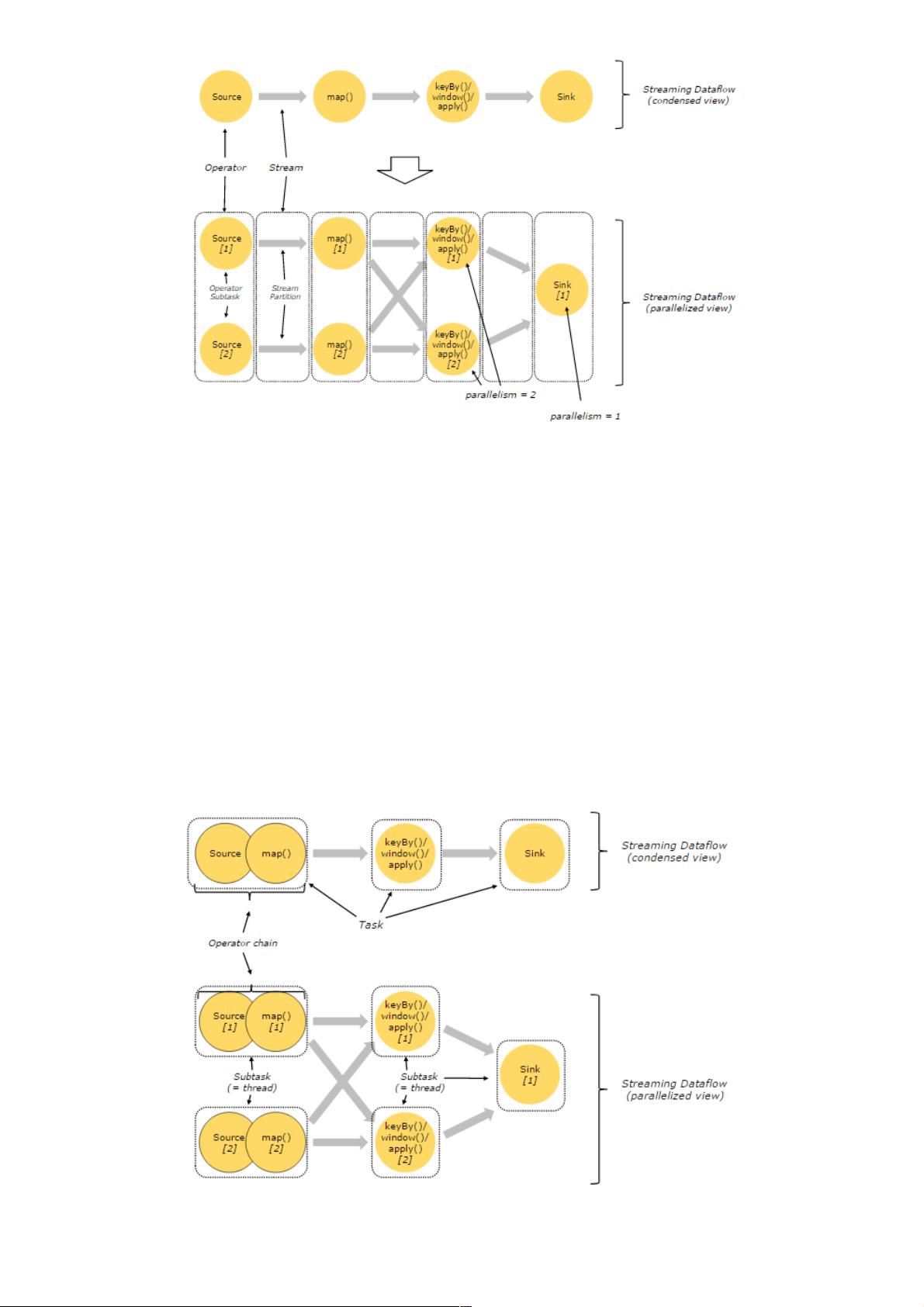
flink-parallel-dataflow
上图Streaming Dataflow的并行视图中,展现了在两个Operator之间的Stream的两种模式:
One-to-one模式
比如从Source[1]到map()[1],它保持了Source的分区特性(Partitioning)和分区内元素处理的有序性,也就是说map()[1]的
Subtask看到数据流中记录的顺序,与Source[1]中看到的记录顺序是一致的。
Redistribution模式
这种模式改变了输入数据流的分区,比如从map()[1]、map()[2]到keyBy()/window()/apply()[1]、keyBy()/window()/apply()[2],
上游的Subtask向下游的多个不同的Subtask发送数据,改变了数据流的分区,这与实际应用所选择的Operator有关系。
另外,Source Operator对应2个Subtask,所以并行度为2,而Sink Operator的Subtask只有1个,故而并行度为1。
Task & Operator Chain
在Flink分布式执行环境中,会将多个Operator Subtask串起来组成一个Operator Chain,实际上就是一个执行链,每个执行链
会在TaskManager上一个独立的线程中执行,如下图所示:
flink-tasks-chains
上图中上半部分表示的是一个Operator Chain,多个Operator通过Stream连接,而每个Operator在运行时对应一个Task;图
剩余11页未读,继续阅读
2019-08-28 上传
2017-07-26 上传
点击了解资源详情
2021-06-04 上传
2021-06-05 上传
2021-01-29 上传
2024-11-16 上传
2019-08-29 上传
2021-01-27 上传

weixin_38502915
- 粉丝: 5
- 资源: 914
 我的内容管理
展开
我的内容管理
展开







最新资源
- YandexAfisha
- fastMRI_BB_abnormalities_annotation
- zoo-keeper
- qlogger:快速的Node.js记录器和换行符分隔的数据附加器和传输
- 行业分类-设备装置-可移动式煤制合成气甲烷化催化剂测试平台及测试方法.zip
- 自动点击辅助工具-易语言
- smartcity_seismometer:一个MakeCode项目
- Python飞机大战、坦克大战代码
- 行业分类-设备装置-可降解紫外光固化树脂及其制备方法与在纸张用涂层材料中的应用.zip
- issue-tracking-system:问题跟踪系统-Java课程
- stock-kafka-producer
- Unity对物体进行拆分Demo源代码
- Listagem_equipamentos
- rw-debugging
- 行业分类-设备装置-可编程数字化机器视觉检测平台.zip
- radar实时风控引擎-其他
