ApacheFlink:统一流批处理,原理与特性解析
83 浏览量
更新于2024-07-15
1
收藏 728KB PDF 举报
Apache Flink是一个强大的开源计算引擎,专为分布式数据流处理和批处理设计。它通过统一的Flink运行时环境,打破了传统的流处理和批处理之间的界限,实现了二者的融合。在传统的解决方案中,流处理和批处理往往由不同的框架单独处理,如MapReduce用于批处理,而Samza或Storm用于流处理。但Flink的独特之处在于,它将批处理视为特殊类型的流处理,即有界数据流。
Flink的核心特性使其在流处理领域表现出色,包括高吞吐、低延迟和高性能。它支持事件时间窗口操作,这使得处理时间与真实事件发生的时间保持一致,尤其适合处理乱序事件。Flink还提供Exactly-once语义,确保在有状态计算中的处理一致性,即使在系统故障后也能恢复准确的状态。
Flink的灵活性体现在其窗口操作上,支持基于时间、计数、会话以及数据驱动的窗口。Backpressure机制保证了在数据流入速率超过处理速率时,系统能够自我调整,避免资源耗尽。此外,Flink通过轻量级分布式快照实现容错,确保系统在故障后的快速恢复。
Flink不仅限于流处理,它还支持批处理,并且在一个运行时环境中同时处理这两种任务。其内存管理在JVM内实现,优化了资源利用率。Flink还包括对迭代计算的支持,这在图计算和机器学习等场景中尤为重要。
在API层面,Flink为流处理应用提供了DataStream API,而对于批处理应用,它提供了DataSet API,两者都支持Java和Scala编程语言。此外,Flink生态系统还包含机器学习库Flink ML,以及其他扩展库,如图处理库Gelly,这些库进一步丰富了Flink的适用场景。
Apache Flink以其统一的处理模型、强大的特性和丰富的API,为开发者提供了构建高效、可靠和灵活的数据处理应用的工具。无论是在实时流处理还是批量数据处理上,Flink都能提供出色的表现,满足各种大数据处理需求。
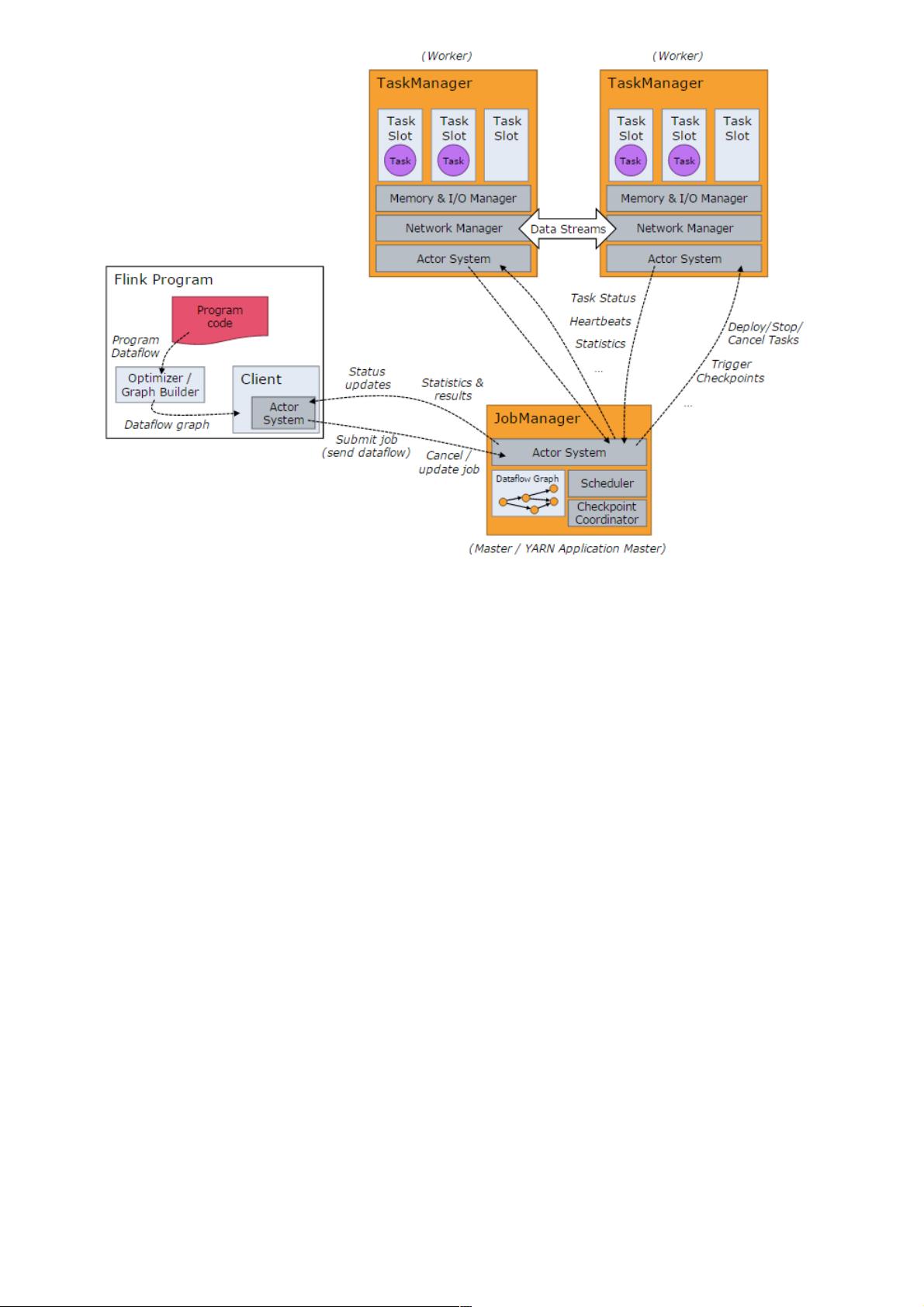
flink-system-architecture
Flink集群启动时,会启动一个JobManager进程、至少一个TaskManager进程。在Local模式下,会在同一个JVM内部
启动一个JobManager进程和TaskManager进程。当Flink程序提交后,会创建一个Client来进行预处理,并转换为一个
并行数据流,这是对应着一个Flink Job,从而可以被JobManager和TaskManager执行。在实现上,Flink基于Actor实
现了JobManager和TaskManager,所以JobManager与TaskManager之间的信息交换,都是通过事件的方式来进行处
理。
如上图所示,Flink系统主要包含如下3个主要的进程:
JobManager
JobManager是Flink系统的协调者,它负责接收Flink Job,调度组成Job的多个Task的执行。同时,JobManager还负
责收集Job的状态信息,并管理Flink集群中从节点TaskManager。JobManager所负责的各项管理功能,它接收到并处
理的事件主要包括:
RegisterTaskManager
在Flink集群启动的时候,TaskManager会向JobManager注册,如果注册成功,则JobManager会向TaskManager回复
消息AcknowledgeRegistration。
SubmitJob
Flink程序内部通过Client向JobManager提交Flink Job,其中在消息SubmitJob中以JobGraph形式描述了Job的基本信
息。
CancelJob
请求取消一个Flink Job的执行,CancelJob消息中包含了Job的ID,如果成功则返回消息CancellationSuccess,失败则
返回消息CancellationFailure。
UpdateTaskExecutionState
TaskManager会向JobManager请求更新ExecutionGraph中的ExecutionVertex的状态信息,更新成功则返回true。
RequestNextInputSplit
运行在TaskManager上面的Task,请求获取下一个要处理的输入Split,成功则返回NextInputSplit。
JobStatusChanged
剩余22页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2019-08-28 上传
2017-07-26 上传
2021-06-04 上传
2021-06-05 上传
2021-01-29 上传
2024-11-16 上传

weixin_38627826
- 粉丝: 5
- 资源: 939
 我的内容管理
展开
我的内容管理
展开







最新资源
- 网页常用英语命令说明
- Oracle PLSQL 编程手册(SQL大全)
- 开源报表系统birt学习指南
- ARM经典300问,值得下载收藏!
- MF RC500-高集成ISO14443A 读卡芯片
- GridView72绝技
- DIV+CSS布局大全
- JDBC AND JAVA .pdf
- Linux开发环境介绍.pdf
- java虚拟机简介 jvm介绍
- openGL材料设置入门
- linux零基础教程
- JPA 教程 -Java EE 5.0平台标准的ORM规范
- Linux Enterprise AS 4.0上安装Oracle 10G步骤.txt
- Altiris® 6 Client Management Suite™
- Windows Vista 双引导配置
