"1999年全国31省消费水平的无监督聚类分析"
需积分: 0 3 浏览量
更新于2024-01-05
收藏 653KB PDF 举报
K-means是一种常用的无监督学习算法,用于对数据进行聚类。聚类是将具有相似特征的样本划分到同一个组或簇中,从而实现对数据的分组和分类。K-means算法以k为参数,将n个对象划分为k个簇,使得簇内的样本具有较高的相似度,而簇间的相似度较低。
其处理过程如下:
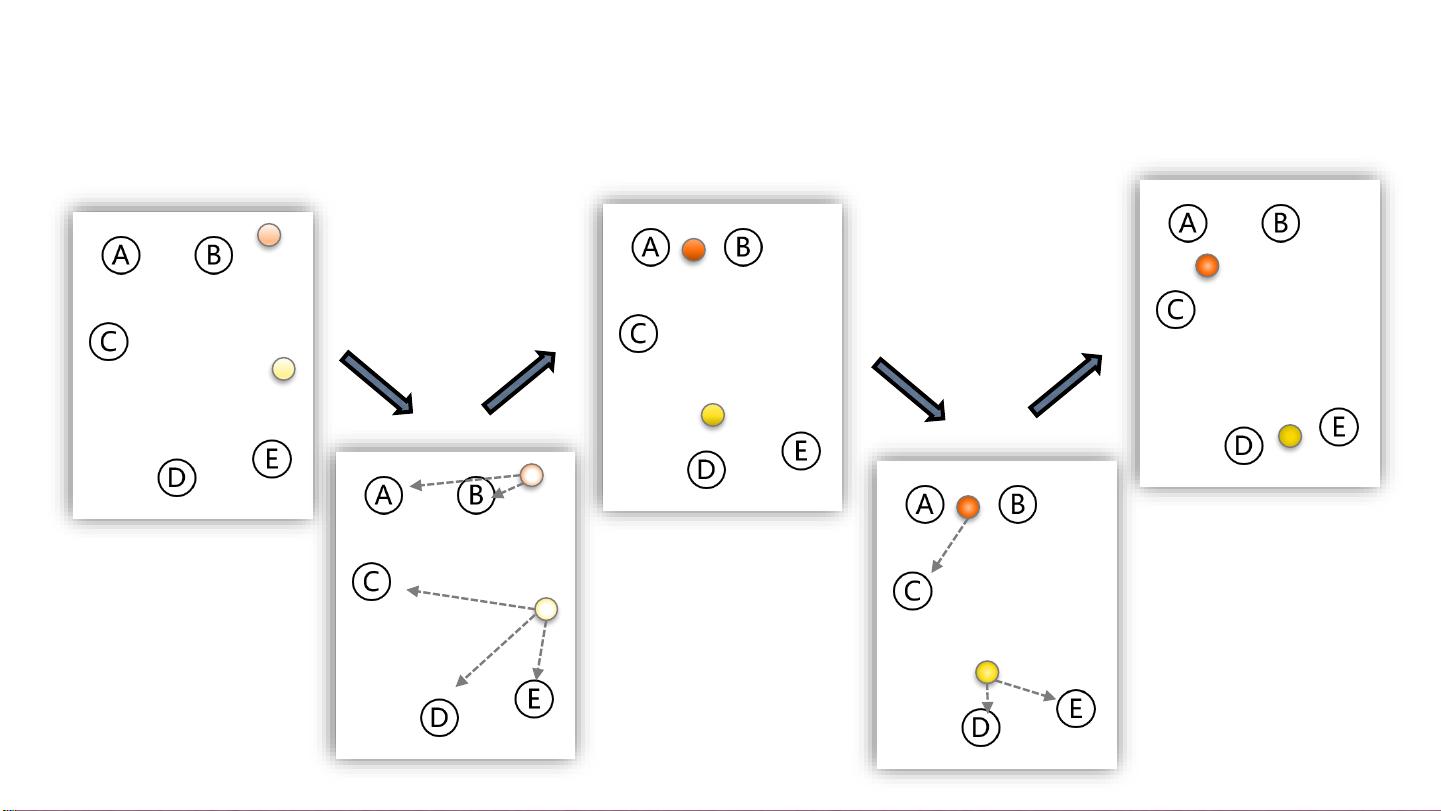
1. 随机选择k个点作为初始的聚类中心。在K-means算法中,一般是从样本集中随机选择k个样本作为初始的聚类中心点。
2. 对于剩下的点,根据其与聚类中心的距离,将其归入最近的簇。通过计算样本点与各个聚类中心的距离,将每个样本点归入与之最近的簇。
3. 对每个簇,计算所有点的均值作为新的聚类中心。通过计算每个簇中所有样本点的均值,得到新的聚类中心。
4. 重复2、3步骤,直到聚类中心不再发生改变。当聚类中心不再发生改变时,即每个样本点都与最近的聚类中心对应,则算法收敛,聚类过程结束。
K-means算法具有一定的局限性,包括对初始聚类中心的敏感性、簇的个数需要事先指定、对异常值较为敏感等。因此,在实际应用时需要根据数据的特点和需求进行适当的调整和优化。
本次实验使用sklearn库中的K-means算法对1999年全国31个省份的消费水平进行聚类。数据包含8个主要变量,包括食品、衣着、家庭设备用品及服务、医疗保健、交通和通讯、娱乐教育文化服务、居住以及杂项商品和服务。通过对这些变量进行聚类分析,可以了解各个省份之间在消费水平上的差异和相似性。
实验的技术路线是使用sklearn库中的K-means算法实现聚类分析。首先导入相关的库和数据,然后调用KMeans类进行聚类分析。在聚类的过程中,选择了适当的聚类中心数目,用于划分样本集合。聚类分析完成后,可以通过可视化的方式展示各个省份在消费水平上的聚类结果,进一步分析和解读数据。
通过K-means聚类分析,我们可以获得1999年全国31个省份的消费水平在国内的情况,从而为相关决策提供参考依据。此外,K-means算法还可以应用于其他领域,如推荐系统、图像处理和自然语言处理等。
总之,K-means聚类算法是一种常用的无监督学习算法,能够将数据集划分为具有相似特征的簇。通过实验和分析,我们可以利用K-means算法对数据进行聚类,实现对数据的分组和分类。在实际应用中,我们可以根据需求对算法进行调整和优化,以获得更好的聚类结果。
K-means聚类算法
剩余15页未读,继续阅读
2022-08-04 上传
2022-01-16 上传
2021-09-09 上传
2021-12-09 上传
2021-10-01 上传
2021-09-02 上传
2021-07-28 上传

朱王勇
- 粉丝: 30
- 资源: 305
 我的内容管理
展开
我的内容管理
展开







最新资源
- C语言数组操作:高度检查器编程实践
- 基于Swift开发的嘉定单车LBS iOS应用项目解析
- 钗头凤声乐表演的二度创作分析报告
- 分布式数据库特训营全套教程资料
- JavaScript开发者Robert Bindar的博客平台
- MATLAB投影寻踪代码教程及文件解压缩指南
- HTML5拖放实现的RPSLS游戏教程
- HT://Dig引擎接口,Ampoliros开源模块应用
- 全面探测服务器性能与PHP环境的iprober PHP探针v0.024
- 新版提醒应用v2:基于MongoDB的数据存储
- 《我的世界》东方大陆1.12.2材质包深度体验
- Hypercore Promisifier: JavaScript中的回调转换为Promise包装器
- 探索开源项目Artifice:Slyme脚本与技巧游戏
- Matlab机器人学习代码解析与笔记分享
- 查尔默斯大学计算物理作业HP2解析
- GitHub问题管理新工具:GIRA-crx插件介绍
