Cox比例风险回归与深度学习在痴呆预测中的比较:基于定期健康检查分析
需积分: 9 109 浏览量
更新于2024-08-10
收藏 617KB PDF 举报
Cox比例风险回归与深度学习算法在痴呆症预测中的比较:基于定期健康检查的分析
本文是一篇关于医学研究领域的论文,主要探讨了Cox比例风险回归(Cox Proportional Hazard Regression, CPR)和深度学习算法在痴呆症预测中的应用有效性。Cox比例风险回归是一种统计学方法,用于生存分析中,特别适用于研究事件发生时间的关联性,比如疾病的发生或患者生存期的预测。在这种情况下,作者们通过分析周期性的健康检查数据来评估这两种技术在预测痴呆症发展方面的性能。
论文的作者团队来自韩国多个知名医学院校和研究中心,包括Myongji医院、Yonsei大学医学院、Severance心血管医院以及专注于行为医学和数据分析的机构。他们进行了深入的对比实验,旨在确定哪种方法——传统的Cox比例风险模型还是新兴的深度学习算法——在预测痴呆症风险方面更为准确和可靠。
Cox比例风险回归的优势在于其假设风险比在整个观察期间保持不变,这使得它在处理多变量问题时相对简单且易于解释。然而,随着机器学习技术的进步,深度学习算法如神经网络由于其强大的特征提取能力和非线性建模能力,可能在处理复杂的数据集时表现更优。
通过对比实验,作者们评估了两种方法在处理痴呆症早期指标、患者病史和其他相关因素时的表现,并可能考虑了数据的预处理、特征选择和模型优化等因素。结果可能揭示了在实际临床环境中,深度学习是否能够提供更高的预测精度,或是Cox比例风险回归在某些特定情况下仍具有不可替代的价值。
值得注意的是,这是一项交叉学科的研究,结合了精神病学、心脏病学、数据科学和人工智能技术,为医疗领域中的预测模型提供了新的视角。如果深度学习算法胜出,这将可能是机器学习在公共卫生和个性化医疗领域的一个重要突破;反之,如果Cox比例风险回归持续表现出稳定性和可解释性,它可能会被推荐为常规分析工具的一部分。
论文的最后部分可能包括讨论了这两种方法的局限性、潜在的应用前景,以及未来研究可能需要进一步改进的地方。此外,对于临床实践和决策支持系统的潜在影响,以及对其他类似健康预测问题的启示,也是该研究值得关注的部分。
这篇论文为理解在痴呆症预测中选择最有效工具提供了关键信息,展示了统计学传统方法与现代AI技术之间的竞争与融合,有助于推动医学领域内的进一步研究和实践发展。
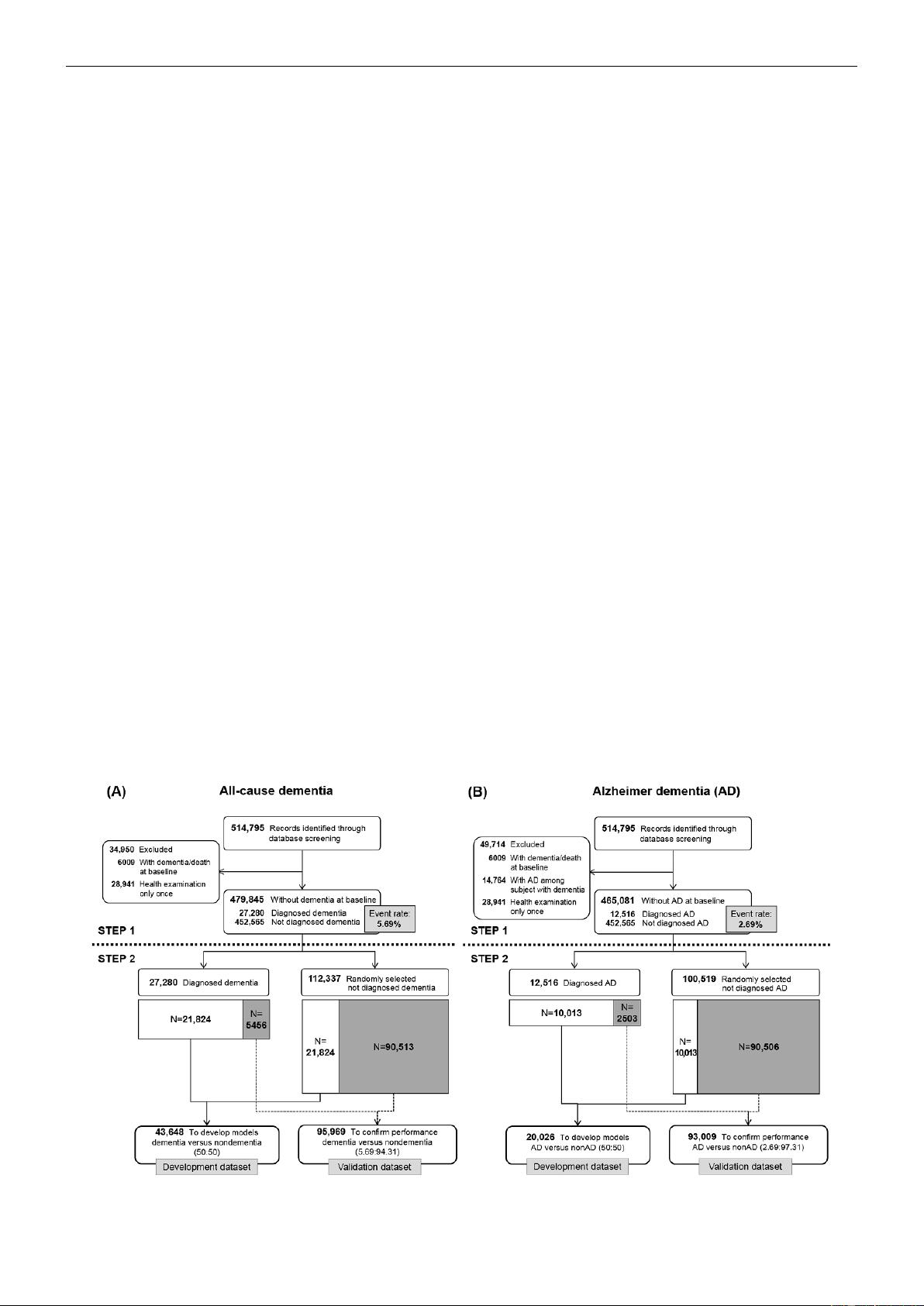
Figure 1 shows the sample selection process in 2 steps (with
all-cause dementia and Alzheimer dementia separately labeled
as A and B). The first step describes the selection of candidate
individuals from the NHIS-HEALS cohort whose data could
be used for predictive modeling. The second step describes the
process of dividing the data into development and validation
datasets for machine learning. The development datasets were
used to fit the parameters of classifiers (ie, criteria that helped
to discriminate individuals who developed dementia during the
study period from those who did not develop dementia) in each
model. The validation datasets were used to assess the
generalization error of the final models.
To create the development and validation datasets for all-cause
dementia and Alzheimer dementia, we first identified 514,795
individuals with records of a health examination in the baseline
year (2002-2003). To analyze all-cause dementia, we excluded
individuals with records of all-cause dementia or death at
baseline and those with no further health examinations after the
baseline year. Of the remaining 479,845 individuals, 27,280
developed all-cause dementia during the study period, resulting
in an event rate of 5.69% (Figure 1). We applied the same
procedure to analyze Alzheimer dementia among 465,081
individuals and found an event rate of 2.69% (Figure 1).
The deep learning method has the advantage that it can identify
patterns in each outcome (eg, yes or no; or event or nonevent).
Deep learning is considered to have high predictive accuracy
in classification studies; however, an extremely imbalanced
dataset can pose a challenge to the detection of patterns in
outcome variables. The fundamental cause of that problem is
that smaller amount of data provides less concrete evidence for
specific patterns than larger amounts of data. Thus, we attempted
to deal with this limitation by generating 1:1 allocation through
undersampling, which has been used in previous studies [24,25].
To build a precise and predictive deep learning model, we used
undersampling to adjust the imbalance between the number of
dementia cases and the number of nondementia cases in the
development datasets, resulting in a more precise and predictive
deep learning model. The numbers of cases in the validation
datasets still reflected the actual event rates in the NHIS-HEALS
cohort.
To finish the construction of the development and validation
datasets for all-cause dementia, we divided the 27,280
individuals who developed all-cause dementia into 2 datasets
with a size ratio of 8:2, corresponding to the development and
validation datasets. The development dataset of 43,648
individuals consisted of 21,824 with dementia (80.00% of
27,280 individuals with dementia) and 21,824 without dementia
as a 1:1 ratio to solve the imbalance problem in classification.
The validation dataset included 5456 individuals who developed
all-cause dementia (20.00% of 27,280 who developed all-cause
dementia) along with 90,513 randomly selected individuals who
did not develop all-cause dementia, for a total of 95,969
individuals. In the development dataset, there were 946 deaths
(4.30%) among the 21,824 individuals who did not develop
all-cause dementia. In the validation dataset, there were 3905
deaths (4.30%) among the 90,513 individuals who did not
develop all-cause dementia. Thus, the event rates of all-cause
dementia in the development and validation datasets were
50.00% and 5.69%, respectively.
We constructed the development and validation datasets for
Alzheimer dementia by the same process. The event rates of
Alzheimer dementia in the development and validation datasets
were 50.00% (n=20,026) and 2.69% (n=93,009), respectively.
Secondary analyses by age group are presented in Multimedia
Appendix 1.
Figure 1. Study design and sample selection. (A) All-cause dementia; (B) Alzheimer dementia.
JMIR Med Inform 2019 | vol. 7 | iss. 3 | e13139 | p. 3http://medinform.jmir.org/2019/3/e13139/
(page number not for citation purposes)
Kim et alJMIR MEDICAL INFORMATICS
XSL
•
FO
RenderX
剩余13页未读,继续阅读
2022-07-15 上传
2020-05-04 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情
2024-11-02 上传
2024-12-26 上传
2024-12-26 上传

Data+Science+Insight
- 粉丝: 1w+
- 资源: 54
 我的内容管理
展开
我的内容管理
展开







最新资源
- node-auth:采用nodejs编写的权限管理系统,通过URL转发,反向代理实现。集成身份验证,用户管理等功能
- Excel模板体温记录表.zip
- hackerrank-python:HackerRank实践
- url-resolve:解析多个 url 段,如 path.resolve
- 毕业设计&课设--毕业设计之数据分析.zip
- Smart-Car-Parking
- dnd-project
- parking-control-ticket:停车场管理系统停车控制系统小票端
- Excel模板财务费用支出明细.zip
- 【地产资料】房产中介绩效方案(XX地产2011年).zip
- Datajarlabs-Data-Science-Bootcamp:Datajarlabs数据科学训练营-作业笔记本
- amazon-cloudfront-functions
- CoffeeOrderSystemHibernate
- 木偶样本
- vue-element-template:基于vue2 + vuecli3 + vue-route + vuex + typescript + axios + element-ui2的中台系统模版
- angulardeploytest
