移动端图像相似度算法实战:HessianAffine+SIFT在电商防重复铺货中的应用
158 浏览量
更新于2024-08-28
收藏 1.66MB PDF 举报
移动端图像相似度算法选型是电商场景中一个关键的技术挑战,特别是在防止重复铺货和优化计算资源利用方面。在移动设备上,由于计算能力和存储限制,选择合适的算法至关重要。本文主要关注三种主要的图像相似度计算方法:
1. 感知哈希算法(PHash):这是一种早期的快速图像特征提取技术,如百度识图和Google的图像搜索服务所采用。它通过将图像压缩并转换为二进制码,如AHASH和DHash,以实现快速比较。然而,这种算法精度相对较低,不适合对细节敏感的应用。
2. 基于局部不变性的图像相似度匹配算法:这类算法强调图像局部特征的稳定性,如SIFT(尺度不变特征变换)或SURF(加速稳健特征),它们能够提取出图像的不变特征,即使在缩放、旋转或光照变化下也能保持一致。这些算法虽然精确度较高,但计算复杂度相对较大。
3. 卷积神经网络(CNN):随着深度学习的发展,CNN被用于图像相似度计算,它们能自动学习高级特征,适用于复杂的图像分析任务。尽管CNN在准确性上通常优于传统方法,但训练和推理的计算成本也显著增加。
本文通过设计实验,权衡了这三类算法在计算复杂度(包括内存消耗、运算时间)和检索效率之间的平衡。最终,文章选择HessianAffine进行特征提取,结合SIFT特征描述生成指纹,作为移动端图像相似度计算的解决方案。这种方法兼顾了速度和精度,能够在保证实时性的同时减少云端存储和计算资源的浪费。
在实际应用中,选择移动端图像相似度算法需要考虑设备性能、实时性需求以及资源效率。对于电商场景来说,实时反馈和防止重复铺货是首要目标,因此对算法的性能和资源管理有着严格的要求。通过这种方式,可以在提供良好用户体验的同时,提高业务运营的效率和成本效益。
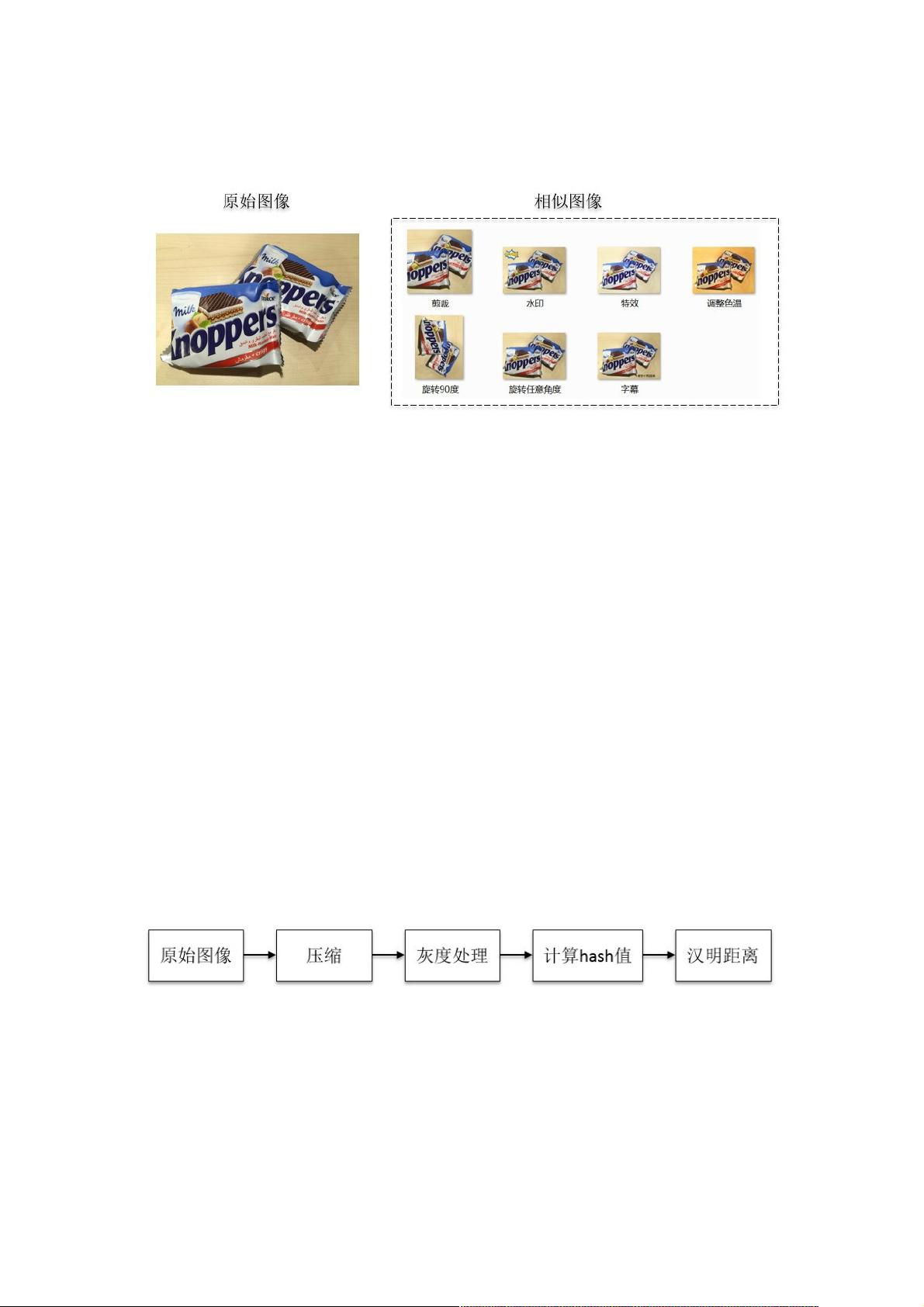
移动端图像相似度算法选型移动端图像相似度算法选型
概述
电商场景中,卖家为获取流量,常常出现重复铺货现象,当用户发布上传图像或视频时,在客户端进行图像特征提取和指纹生
成,再将其上传至云端指纹库对比后,找出相似图片,杜绝重复铺货造成的计算及存储资源浪费。
该方法基于图像相似度计算,可广泛应用于安全、版权保护、电商等领域。
摘要
端上的图像相似度计算与传统图像相似度计算相比,对计算复杂度及检索效率有更高的要求。本文通过设计实验,对比三类图
像相似度计算方法:感知哈希算法、基于局部不变性的图像相似度匹配算法以及基于卷积神经网络的图像相似度算法,权衡其
在计算复杂度及检索效率方面的优劣,最终选取 Hessian Affine进行特征提取,SIFT特征描述生成指纹,作为端上的图像相似
度计算模型。
关键词:图像相似度计算、特征提取、计算复杂度、检索效率
引言
图像相似度计算在当前的云计算处理方式,会将客户端数据上传至云端,进行图像、视频检索相似度计算等一系列复杂逻辑处
理后将结果反馈给终端,虽然在计算能力上云端优势明显,但该方式同时存在严重的存储、计算资源及流量的浪费且无法满足
实时性要求。
随着手机计算能力的提升,一种显而易见的方式是将部分数据在客户端进行处理后,再将有价值的数据上传云端存储及进一步
处理。对于电商场景中的重复铺货现象,可在用户发布上传图像、视频时,在客户端进行图像相似度计算,做到实时反馈,对
于重复图像及视频不进行云端存储,避免了存储及计算资源的浪费。
图像检索算法的基本步骤包括特征提取、指纹生成和相似度匹配。业界常用的图像相似度计算方法大致分为三类,传统的感知
哈希算法、基于局部不变性的图像相似度匹配算法以及利用深度学习算法进行的图像相似度计算方法。
1.传统的hash算法
自2011年百度借助TinEye发布百度识图后不久,google发布了类似的以图搜图图片搜索服务,“感知哈希算法”在图像搜索过程
中发挥了重要作用。大致流程如下:
1.1感知哈希算法理论简介:
1.均值hash: 通过对原始图像进行压缩(8*8)和灰度处理后计算压缩后的图像像素均值,用8*8图像的64个像素与均值对比,
大于均值为1,小于均值为0,得到的64位二进制编码即为原图像的ahash值。算法速度快,但精确度较低。
2.差异hash:与均值hash相比,差异hash同样要进行图像压缩和灰度处理,然后用每行的前一个像素与后一个像素对比,大
于为1,小于为0,来生成指纹信息。算法精确度较高,速度较快。
3.感知hash:通过对原始图像进行压缩(32*32)和灰度处理后计算压缩,对其进行离散余弦变换后,用32*32图像的前8*8像
素计算均值,8*8像素值大于均值为1,小于均值为0,得到64位指纹信息为原始图像的phash值。算法精准度较高,速度较
差。
根据以上三种算法可计算出两张图像响应的hash值,利用两张图像hash值得汉明距离,可判别出其相似程度,其中汉明距离
越大,相似度越低,汉明距离越小,相似度越高。
下载后可阅读完整内容,剩余9页未读,立即下载
2014-04-07 上传
2021-09-10 上传
2022-05-28 上传
2023-06-08 上传
2023-08-18 上传
2023-05-16 上传
2023-07-08 上传
2023-05-29 上传
2023-04-05 上传

weixin_38705788
- 粉丝: 6
- 资源: 907
 我的内容管理
展开
我的内容管理
展开







最新资源
- Java毕业设计项目:校园二手交易网站开发指南
- Blaseball Plus插件开发与构建教程
- Deno Express:模仿Node.js Express的Deno Web服务器解决方案
- coc-snippets: 强化coc.nvim代码片段体验
- Java面向对象编程语言特性解析与学生信息管理系统开发
- 掌握Java实现硬盘链接技术:LinkDisks深度解析
- 基于Springboot和Vue的Java网盘系统开发
- jMonkeyEngine3 SDK:Netbeans集成的3D应用开发利器
- Python家庭作业指南与实践技巧
- Java企业级Web项目实践指南
- Eureka注册中心与Go客户端使用指南
- TsinghuaNet客户端:跨平台校园网联网解决方案
- 掌握lazycsv:C++中高效解析CSV文件的单头库
- FSDAF遥感影像时空融合python实现教程
- Envato Markets分析工具扩展:监控销售与评论
- Kotlin实现NumPy绑定:提升数组数据处理性能
