Apache Spark 2.3新特性概述:数据处理与性能提升
需积分: 13 52 浏览量
更新于2024-07-18
收藏 554KB PDF 举报
Apache Spark 2.3是一个重要的里程碑,引入了一系列显著的新特性和改进,旨在提升数据处理效率、简化基础设施管理,并增强数据科学家和数据工程师的协作。以下是Spark 2.3的主要亮点:
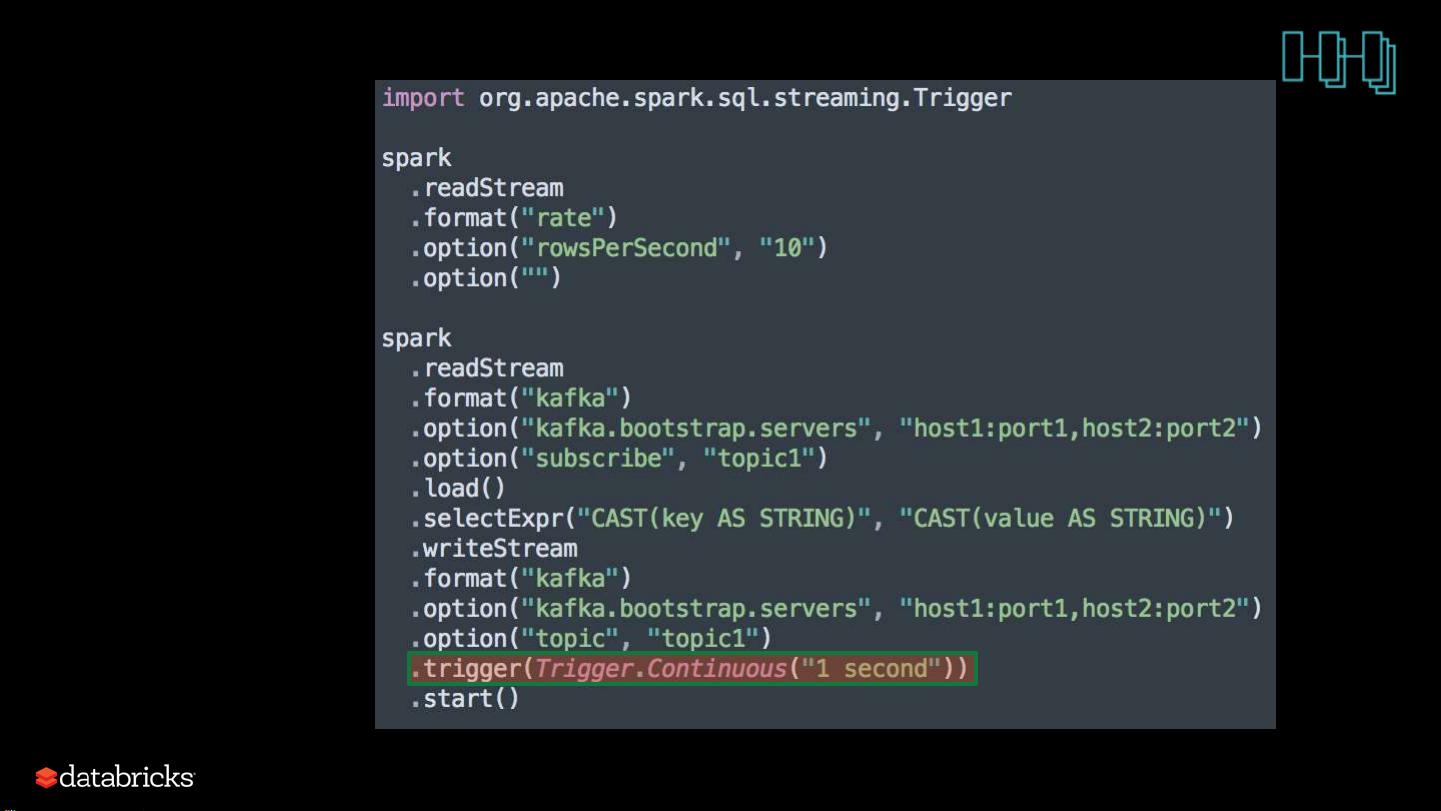
1. **连续处理(Continuous Processing)**:
- **Structured Streaming**:首次在Spark 2.0中引入的Structured Streaming模块得到了进一步加强,它允许实时处理无限数据流,支持流与流之间的连接(stream-stream join),为实时数据分析提供了强大工具。
2. **数据源API V2**:
- 新版本的API提升了数据处理的灵活性,使得开发者能够更方便地接入和操作不同来源的数据,包括API调用、数据库查询等,简化了数据集成过程。
3. **Kubernetes集成**:
- Spark on Kubernetes(Spark-K8s)得到了强化,使得Spark作业可以在容器化环境中更加便捷地部署和运行,提高了部署的弹性和扩展性。
4. **历史服务器V2**:
- 更新后的历史服务器提供更好的性能和稳定性,有助于跟踪和管理Spark应用程序的历史记录,方便故障排查和分析。
5. **用户定义函数(UDF)**:
- UDF功能得到增强,允许用户编写自定义的函数来扩展Spark的功能,增强了数据处理的灵活性和定制化能力。
6. **SQL增强**:
- Spark 2.3包含多种SQL改进,如更丰富的内置函数和优化,提升了SQL查询的性能和易用性。
7. **PySpark**:
- Python接口PySpark也得到了优化,提供了更好的性能和开发体验,使得Python开发者可以更高效地利用Spark进行大数据处理。
8. **性能优化**:
- 通过内建ORC支持和稳定代码生成机制,Spark 2.3在处理大规模数据时的性能有了显著提升,特别是在读取和写入文件方面。
9. **图像读取器**:
- 新增或改进的图像读取器功能,可能是对大数据中的图像数据处理的支持,进一步扩大了Spark的应用领域。
10. **机器学习在流处理(ML on Streaming)**:
- 在流处理场景下,Spark的机器学习工具包得以优化,使得实时模型训练和预测成为可能,支持数据驱动的业务决策。
据统计,Spark 2.3解决了大约1400个问题,这表明社区在持续完善和修复旧版中的漏洞,确保用户能使用到更稳定、更健壮的产品。Spark 2.3的这些新特性和改进无疑为数据驱动的业务提供了更强大的工具集,帮助企业在大数据时代更好地进行分析和决策。
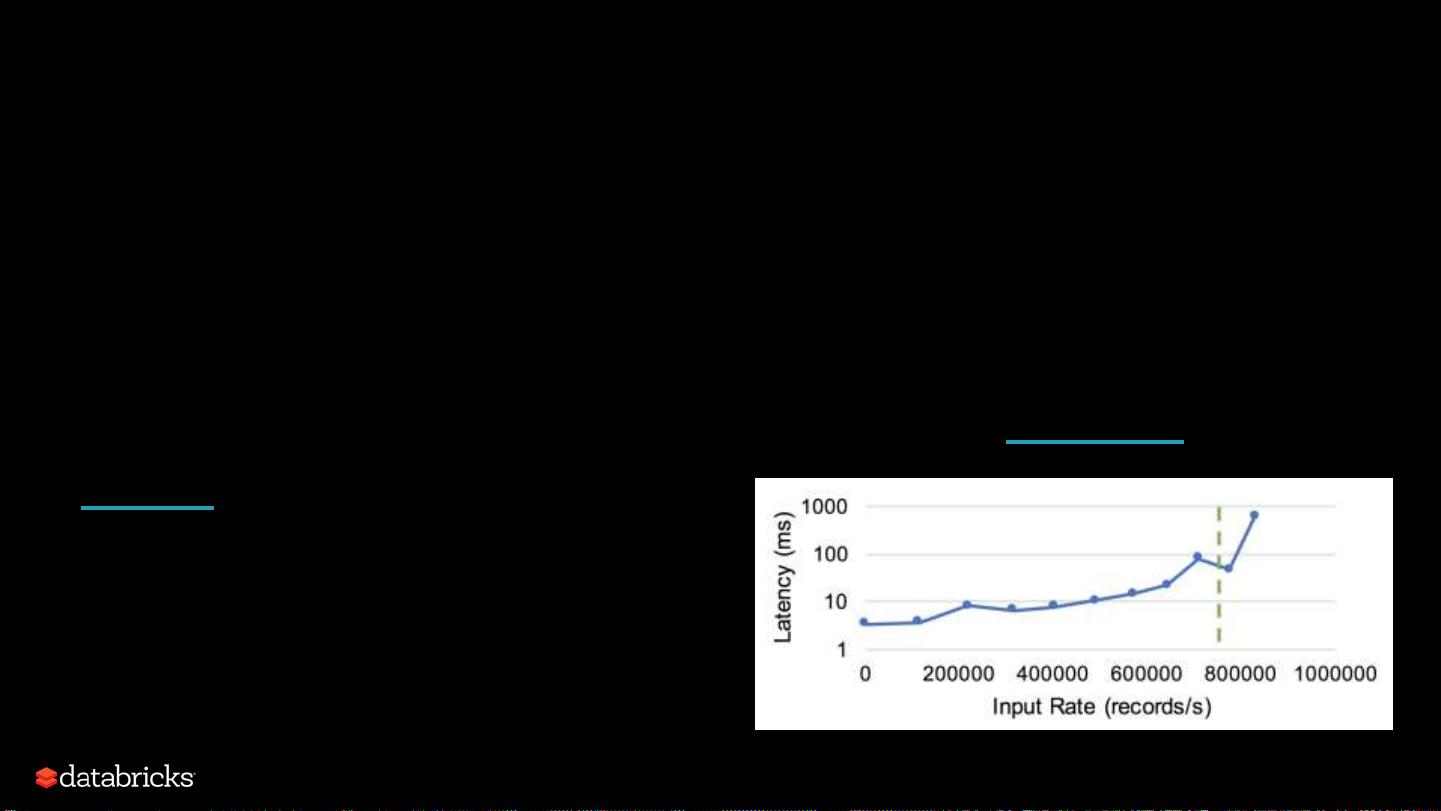
Continuous Processing Execution
Mode
Micro-batch Processing (since 2.0 release)
• Lower end-to-end latencies of ~100ms
• Exactly-once fault-tolerance guarantees
Continuous Processing (since 2.3 release) [SPARK-
20928]
• A new streaming execution mode
(experimental)
• Low (~1 ms) end-to-end latency
• At-least-once guarantees
8

剩余45页未读,继续阅读
2018-10-04 上传
2018-12-19 上传
2018-02-11 上传
2023-02-17 上传
2023-06-13 上传
2023-06-28 上传
2023-06-12 上传
2023-05-13 上传
2023-04-21 上传
2023-06-11 上传

abc333
- 粉丝: 0
- 资源: 6
 我的内容管理
展开
我的内容管理
展开







最新资源
- WPF渲染层字符绘制原理探究及源代码解析
- 海康精简版监控软件:iVMS4200Lite版发布
- 自动化脚本在lspci-TV的应用介绍
- Chrome 81版本稳定版及匹配的chromedriver下载
- 深入解析Python推荐引擎与自然语言处理
- MATLAB数学建模算法程序包及案例数据
- Springboot人力资源管理系统:设计与功能
- STM32F4系列微控制器开发全面参考指南
- Python实现人脸识别的机器学习流程
- 基于STM32F103C8T6的HLW8032电量采集与解析方案
- Node.js高效MySQL驱动程序:mysqljs/mysql特性和配置
- 基于Python和大数据技术的电影推荐系统设计与实现
- 为ripro主题添加Live2D看板娘的后端资源教程
- 2022版PowerToys Everything插件升级,稳定运行无报错
- Map简易斗地主游戏实现方法介绍
- SJTU ICS Lab6 实验报告解析
