Spark核心算子详解:Transformations操作
需积分: 24 11 浏览量
更新于2024-09-09
收藏 372KB PDF 举报
"Spark基本算子操作主要涵盖了对数据集的各种转换和操作,包括但不限于映射、过滤、扁平化映射、分区映射、分区索引映射、随机采样、联合、交集和去重等。这些算子帮助用户在Spark中处理和分析大规模数据。以下是对这些算子的详细解释:
1. `map(func)`:这是一个非常基础的算子,它接收一个函数`func`,将数据集中的每个元素通过`func`进行转换,然后返回一个新的数据集,其中的元素是原元素经过函数处理后的结果。
2. `filter(func)`:此算子用于筛选数据,返回一个新的数据集,只包含那些经过`func`函数计算后返回值为`true`的元素。
3. `flatMap(func)`:与`map`类似,但`flatMap`允许函数`func`返回一个集合(如数组或列表),而不是单一元素。所有返回的集合会被扁平化,形成一个新的数据集。
4. `mapPartitions(func)`:这个算子在每个数据集的分区上运行`func`,`func`的输入是分区的迭代器,返回另一个迭代器。这样可以对整个分区进行操作,而不是单个元素,通常用于批量处理。
5. `mapPartitionsWithIndex(func)`:与`mapPartitions`类似,但`func`还接收分区的索引作为参数,允许根据分区位置执行特定的操作。
6. `sample(withReplacement, fraction, seed)`:此算子用于对数据集进行随机采样,`withReplacement`表示是否允许重复采样,`fraction`是采样比例,`seed`用于设置随机数生成器的种子。
7. `union(otherDataset)`:将当前数据集与另一个数据集合并,返回一个新的数据集,包含两者的全部元素。
8. `intersection(otherDataset)`:返回当前数据集与另一个数据集的交集,即两个数据集中都存在的元素。
9. `distinct([numTasks])`:去除数据集中的重复元素,可选地通过`numTasks`参数设置任务数量来控制并行度。
10. `groupByKey([numTasks])`:对于键值对的数据集,将所有具有相同键的值收集到一起,形成`(K, Seq[V])`对的新数据集。默认情况下,任务数等于数据的分区数,但可以通过`numTasks`调整。
在Spark中,这些基本算子是构建复杂数据处理流水线的基础,它们支持分布式计算,能够在大规模数据上高效运行,并且通过惰性评估优化性能,只有在真正需要结果时才执行计算。"
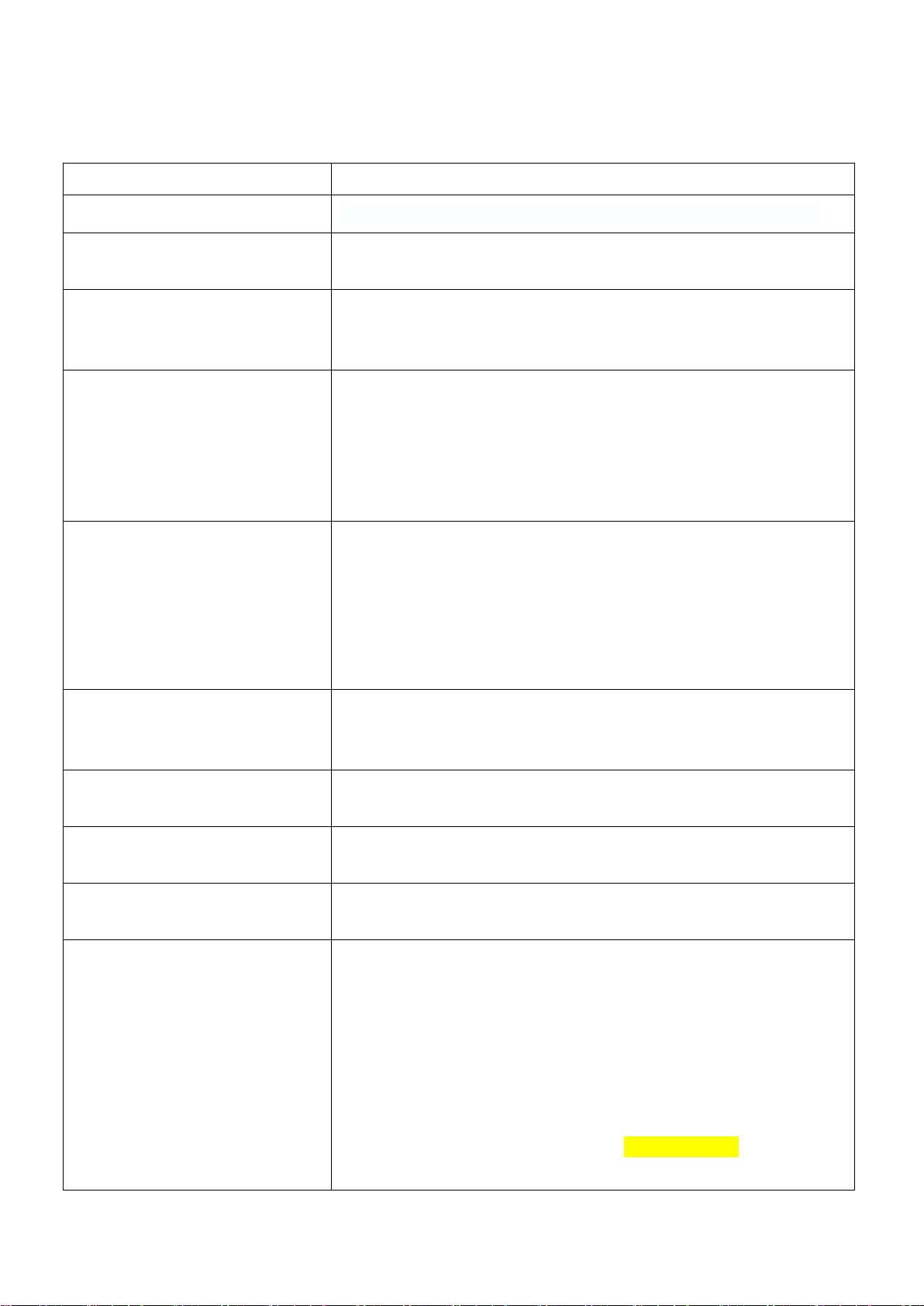
Transformations
Transformation
Meaning
map(func)
返回一个数据集,由每一个输入元素经过 func 函数转换后成.
filter(func)
返回一个新数据集,由经过 func 函数计算后返回值为 true 的输入元
素组成
flatMap(func)
类似于 map,每个元素通过 func 函数被映射成为集合或者字符串,然
后将每个结果集合进行合并(::)形成新的集合(因此 func 应该返回一
个序列,而不是单一元素)
mapPartitions(func)
在类型为 T 的 RDD 上运行时,func 的函数类型必须是 Iterator[T]
=> Iterator[U]。
mapPartitions 将会被每一个数据集分区调用一次。各个数据集分区
的全部内容将作为顺序的数据流传入函数 func 的参数中,func 必须
返回另一个 Iterator[T]。
mapPartitionsWithIndex(fu
nc)
类似于 mapPartitions, 函数原型是:
def mapPartitionsWithIndex(f:(Int,Iterator[T]) =>
Iterator[U], preservesPartitioning : Boolean =
false) :Iterator [U]
mapPartitionsWithIndex 的 func 接受两个参数,第一个参数是
分区的索引,第二个是一个数据集分区的迭代器。而输出的是一个包含
经过该函数转换的迭代器。
sample(withReplacement, f
raction, seed)
随机采样
根据 fraction 指定的比例,对数据进行采样,可以选择是否用随机数
进行替换(withReplacement),seed 用于指定随机数生成器
union(otherDataset)
返回一个新的数据集,新数据集是由源数据集和参数数据集联合而成。
intersection(otherDataset
)
返回一个新的数据集,新数据集是由源数据集和参数数据集的差
集.(A-B=[只存在 A,而不存在 B 的元素]
distinct([numTasks]))
去除重复元素
groupByKey([numTasks])
在一个(K,V)对的数据集上调用,返回一个(K,Seq[V])对的数据集.
注意:默认情况下,Task 数目是数据分区数目,但是可以传入一个可
选的 numTasks 参数来改变它。
如果分组是用来计算聚合操作(如 sum 或 average),那么应该使
用 reduceByKey 或 combineByKey 来提供更好的性能。
groupByKey, reduceByKey 等 transformation 操作涉及到了
shuffle 操作,所以这里引出两个概念宽依赖和窄依赖。
窄依赖(narrow dependencies)
下载后可阅读完整内容,剩余3页未读,立即下载
353 浏览量
166 浏览量
2024-08-10 上传
161 浏览量
2023-10-16 上传
232 浏览量
158 浏览量

tiechui1994
- 粉丝: 2201
 我的内容管理
展开
我的内容管理
展开







最新资源
- 乘风多用户PHP统计系统v4.1:源码与项目实践指南
- Vue.js拖放组件:vue-smooth-dnd的封装与应用
- WPF图片浏览器开发教程与源码分享
- 泰坦尼克号获救预测:分享完整版机器学习训练测试数据
- 深入理解雅克比和高斯赛德尔迭代法在C++中的实现
- 脉冲序列调制与跳周期调制相结合的Buck变换器研究
- 探索OpenCV中的PCA人脸检测技术
- Oracle分区技术:表、索引与索引分区深入解析
- Windows 64位SVN客户端下载安装指南
- SSM与Shiro整合的实践案例分析
- 全局滑模控制Buck变换器设计及其仿真分析
- 1602液晶动态显示实现源码及使用教程下载
- Struts2、Hibernate与Spring整合在线音乐平台源码解析
- 掌握.NET Reflector 8.2.0.42:反编译及源码调试技巧
- 掌握grunt-buddha-xiaofangmoon插件的入门指南
- 定频滑模控制在Buck变换器设计中的应用
