Tensorflow数据读取:预加载、喂养与文件读取解析
17 浏览量
更新于2024-08-29
收藏 163KB PDF 举报
"本文主要介绍了TensorFlow数据读取的三种方式:预加载数据、通过Python喂数据和直接从文件读取。文章详细解释了每种方法的工作原理和优缺点,并结合TensorFlow的工作机制进行了解析。"
在TensorFlow中,数据读取是一个关键步骤,它对训练模型的效率和性能有着直接影响。以下是三种数据读取方式的详细说明:
1. **预加载数据**:
在预加载数据的方式中,我们将数据直接内嵌到TensorFlow的计算图(Graph)中。例如,通过`tf.constant()`创建常量张量,数据在构建图时就被确定。这种方式简洁明了,适用于小规模数据。然而,当数据量大时,由于整个Graph包含了大量的数据,这可能导致内存压力和效率问题,因为Graph的大小会随着数据量的增加而增加,同时在传输Graph到Session时可能会变得缓慢。
2. **通过Python产生数据并喂给后端(Feeding)**:
使用`tf.placeholder()`创建占位符张量,它们在运行时通过`sess.run()`的`feed_dict`参数接收Python中产生的数据。这种方式更灵活,可以在运行时动态输入数据,尤其适合处理动态大小或不确定的数据集。然而,每次运行`sess.run()`都需要提供`feed_dict`,增加了代码的复杂性和运行时间,对于大规模数据处理也可能不高效。
3. **直接从文件读取**:
TensorFlow提供了直接从文件读取数据的能力,如`tfrecords`文件格式,这是一种高效的存储和读取大量数据的方式。文件读取操作可以在C++后端执行,避免了Python的内存限制和速度瓶颈。这种方式更适合处理大数据集,可以利用多线程和多进程提高读取速度,但需要编写额外的代码来实现数据的序列化和反序列化。
每种方法都有其适用场景,选择哪种方式取决于数据的大小、处理需求以及性能要求。在实际应用中,通常会结合使用这些方法,比如预加载小规模验证集,通过Python喂食训练数据,或者在生产环境中直接从文件流式加载数据。
理解TensorFlow的工作模式也很重要。Python用于设计计算图,提供高级接口和灵活性,而C++后端则负责高效地执行计算图。这种分离使得TensorFlow能充分利用两种语言的优点,但在处理大规模数据时,需要合理设计数据读取策略以避免性能瓶颈。
在面临大型数据集时,可以考虑使用队列(Queues)和数据加载器(Data Loaders)等工具,它们能够异步加载数据,减少等待时间,提高整体效率。此外,使用数据增强(Data Augmentation)可以进一步优化处理流程,增加模型的泛化能力。选择合适的数据读取策略对于优化TensorFlow模型的训练过程至关重要。
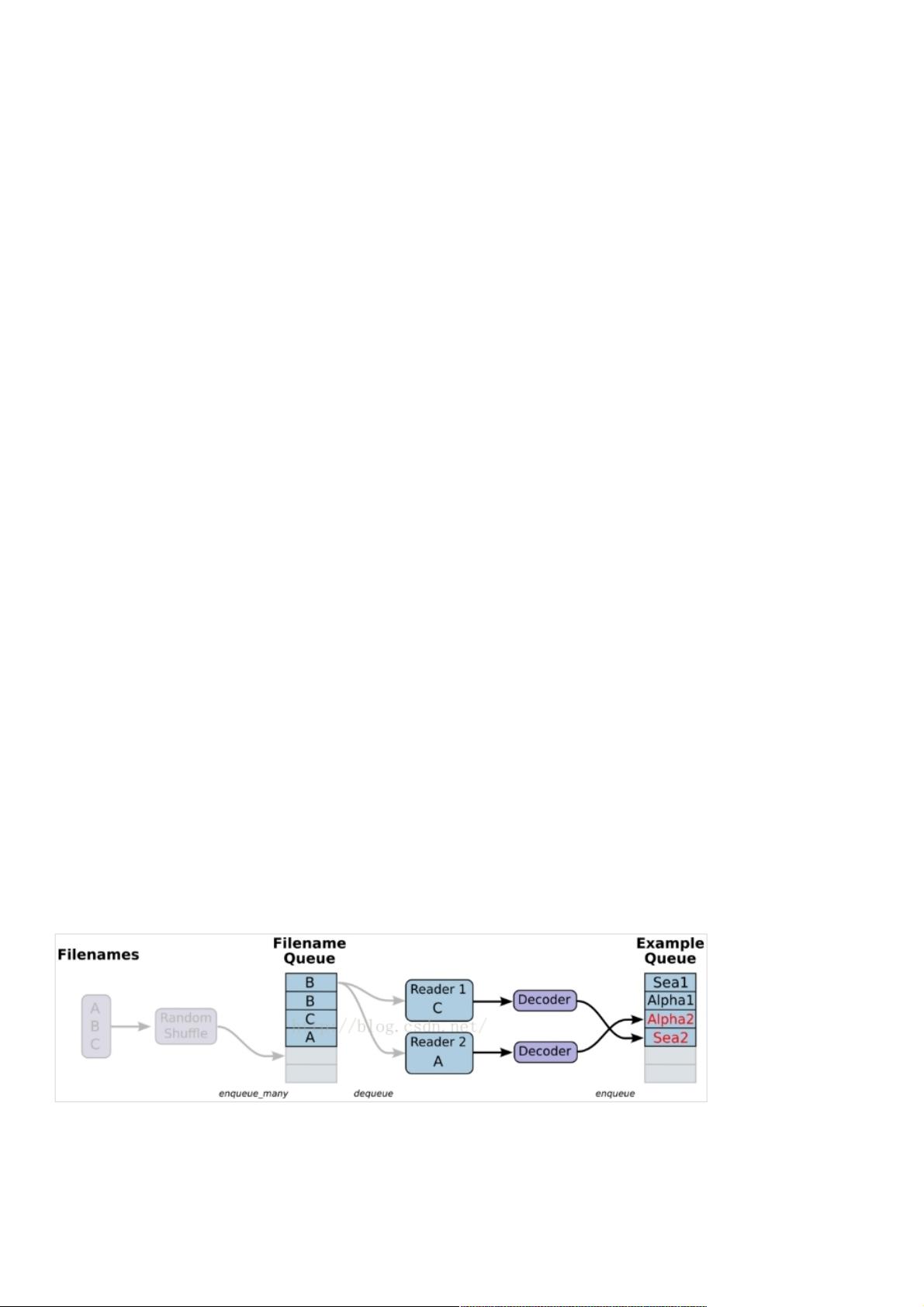
详解详解Tensorflow数据读取有三种方式(数据读取有三种方式(next_batch))
Tensorflow数据读取有三种方式:数据读取有三种方式:
Preloaded data: 预加载数据
Feeding: Python产生数据,再把数据喂给后端。
Reading from file: 从文件中直接读取
这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的。
TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活。而Python恰好相反,所以结合两种语言的优势。涉及计
算的核心算子和运行框架是用C++写的,并提供API给Python。Python调用这些API,设计训练模型(Graph),再将设计好的
Graph给后端去执行。简而言之,Python的角色是Design,C++是Run。
一、预加载数据:一、预加载数据:
import tensorflow as tf
# 设计Graph
x1 = tf.constant([2, 3, 4])
x2 = tf.constant([4, 0, 1])
y = tf.add(x1, x2)
# 打开一个session --> 计算y
with tf.Session() as sess:
print sess.run(y)
二、二、python产生数据,再将数据喂给后端产生数据,再将数据喂给后端
import tensorflow as tf
# 设计Graph
x1 = tf.placeholder(tf.int16)
x2 = tf.placeholder(tf.int16)
y = tf.add(x1, x2)
# 用Python产生数据
li1 = [2, 3, 4] li2 = [4, 0, 1] # 打开一个session --> 喂数据 --> 计算y
with tf.Session() as sess:
print sess.run(y, feed_dict={x1: li1, x2: li2})
说明:在这里x1, x2只是占位符,没有具体的值,那么运行的时候去哪取值呢?这时候就要用到sess.run()中的feed_dict参
数,将Python产生的数据喂给后端,并计算y。
这两种方案的缺点:
1、预加载:将数据直接内嵌到Graph中,再把Graph传入Session中运行。当数据量比较大时,Graph的传输会遇到效率问
题。
2、用占位符替代数据,待运行的时候填充数据。
前两种方法很方便,但是遇到大型数据的时候就会很吃力,即使是Feeding,中间环节的增加也是不小的开销,比如数据类型
转换等等。最优的方案就是在Graph定义好文件读取的方法,让TF自己去从文件中读取数据,并解码成可使用的样本集。
三、从文件中读取,简单来说就是将数据读取模块的图搭好三、从文件中读取,简单来说就是将数据读取模块的图搭好
1、准备数据,构造三个文件,A.csv,B.csv,C.csv
$ echo -e "Alpha1,A1Alpha2,A2Alpha3,A3" > A.csv
$ echo -e "Bee1,B1Bee2,B2Bee3,B3" > B.csv
$ echo -e "Sea1,C1Sea2,C2Sea3,C3" > C.csv
2、单个Reader,单个样本
下载后可阅读完整内容,剩余5页未读,立即下载
1238 浏览量
431 浏览量
156 浏览量
175 浏览量
2023-09-01 上传
144 浏览量
2023-06-07 上传
108 浏览量

weixin_38577648
- 粉丝: 3
 我的内容管理
展开
我的内容管理
展开







最新资源
- 教学专用变压器设计文档解析与应用
- 森锐最新版身份证阅读软件发布,支持多终端系统
- 墨西哥漫画艺术研究:鲁斯与战斗漫画家
- 安川SGDV-R70F01A伺服驱动器异常处理与输入回路安全指南
- 使用Openclassroom开发后备箱项目
- 快速实现zbar二维码扫描应用
- Matlab实现人口预测:从指数增长到阻滞增长模型分析
- 创意小清新彩虹主题响应式前台模板
- 打造个性化的文本编辑器工具
- 特拉维斯与地形自动化工具Terraform的整合
- 轿车底盘提升平台设计装置的技术文档
- 绿色汉化版ProcDump32 v1.62中文终极版发布
- FusionCMS快速下载器:使用CLI安装最新版本
- DWZ图标拓展工具:提升审美体验
- 纸基摩擦盘设计与拖拉机制动器应用研究
- Android App自动更新功能的实现方法
