HDFS深度解析:写入、读取与故障处理机制
需积分: 10 161 浏览量
更新于2024-09-07
收藏 775KB PDF 举报
"这是关于Hadoop HDFS的一份面试题整理,涵盖了HDFS的写入和读取过程,Namenode的元数据管理,Namenode与SecondaryNamenode的角色,联邦HDFS,处理小文件的策略,安全模式,NameNode的作用,以及HDFS的优缺点。"
在这份资料中,我们深入探讨了Hadoop分布式文件系统(HDFS)的核心概念。首先,HDFS是Hadoop生态系统的重要组成部分,它设计用于存储大规模的数据集,具有高容错性和可扩展性。
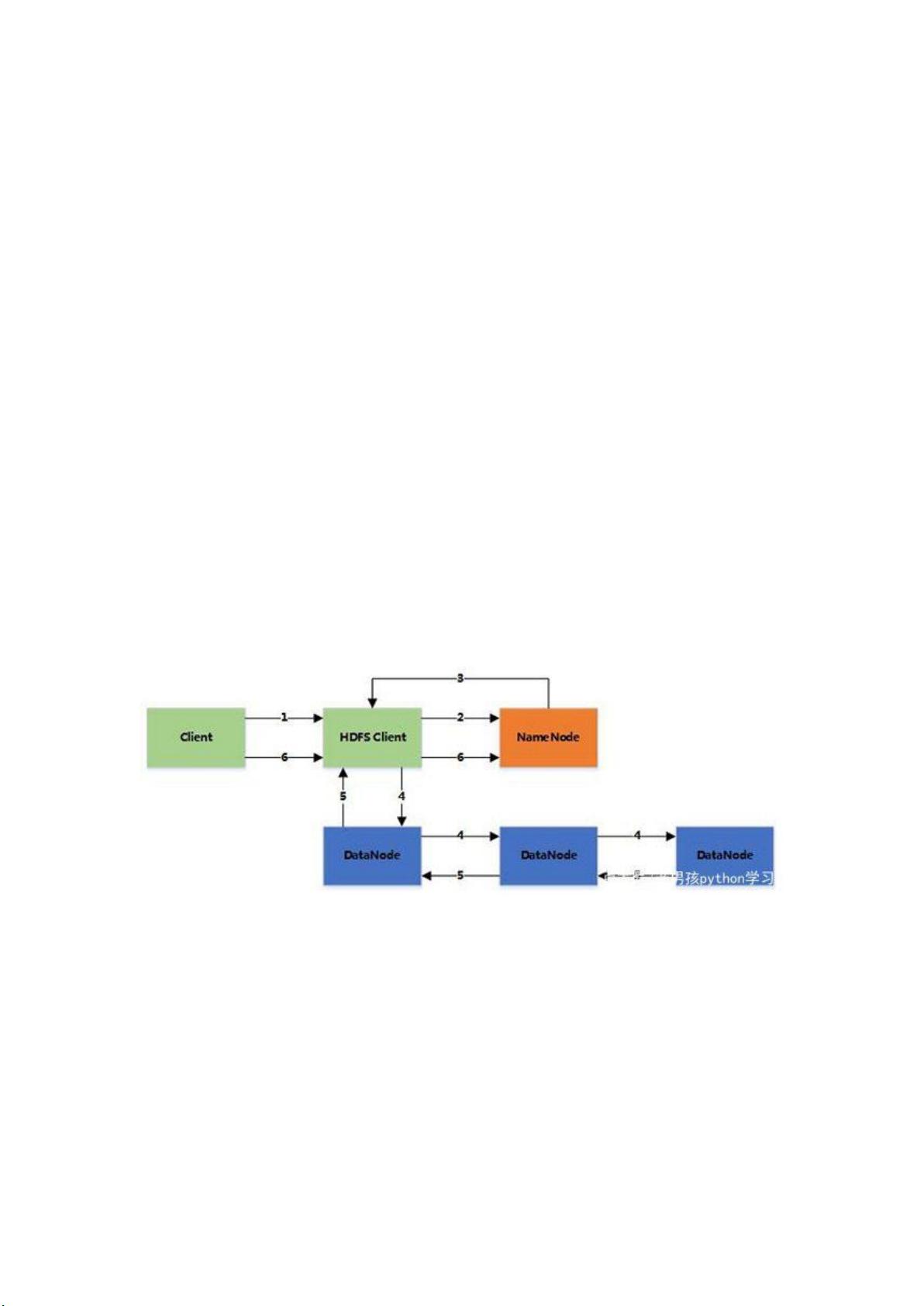
**HDFS写入剖析**:
1. 客户端发起写文件请求到Namenode。
2. Namenode验证文件是否存在及权限,通过后将操作记录到编辑日志,并返回输出流对象给客户端。
3. 文件被切割成128MB的块,形成数据队列。
4. Namenode选择多个Datanode构成一个数据管道并告知客户端。
副本策略通常为:1.客户端节点,2.不同机架的节点,3.同一机架不同节点,4.如有需要,随机节点。
5. 客户端写入数据和校验和,数据流式传输至所有Datanode。
6. 如果某个Datanode故障,其他节点会接收到数据,Namenode会重新安排副本。
7. 每个块写入完成,Datanode之间会确认,最后客户端收到确认。
8. 文件写入完成后,客户端通知Namenode关闭输入流。
**HDFS读取剖析**:
1. 客户端向Namenode请求文件位置。
2. Namenode返回包含文件块位置的列表。
3. 客户端直接从最近或最可用的Datanode读取数据,减少延迟。
**Namenode的元数据**:
Namenode负责维护文件系统的目录结构和文件到数据块的映射,确保数据的正确性和一致性。
**Namenode与SecondaryNamenode**:
SecondaryNamenode不是Namenode的备份,而是帮助Namenode定期合并编辑日志和镜像文件,防止日志过大导致的问题。
**联邦HDFS**:
允许HDFS系统扩展到多个独立的命名空间,提高集群利用率。
**处理小文件的影响和解决方案**:
小文件会导致元数据管理开销增大,解决方案包括使用Har Archive或SequenceFile归档,以及使用MapReduce压缩。
**安全模式**:
在启动时,Namenode进入安全模式,等待大多数Datanode报告,以确保集群的可用性。
**NameNode作用**:
NameNode是HDFS的中央控制节点,管理文件系统的命名空间和数据块映射。
**HDFS的优缺点**:
优点:高容错、可扩展、适合大数据处理。缺点:不支持低延迟访问、不易于文件的修改和重命名,且小文件处理效率较低。
这份资料全面地阐述了HDFS的关键运作机制,对于理解Hadoop大数据存储和处理有极大的帮助。
1
HDFS(分布式文件系统)
目录
HDFS(分布式文件系统) .............................................................................................................................. 1
HDFS 写入剖析: ............................................................................................................................................... 1
HDFS 读取剖析: ............................................................................................................................................... 2
Namenode 的元数据 (目录中的文件) ........................................................................................................ 3
Namenode 和 Secondary Namenode ......................................................................................................... 3
Namenode 如何记录文件位置信息(简要回答) ................................................................................. 4
联邦 HDFS ............................................................................................................................................................. 4
HDFS 存小文件的影响和解决方案: .......................................................................................................... 4
安全模式 ................................................................................................................................................................ 5
NameNode 作用 ................................................................................................................................................. 5
HDFS 的优缺点 .................................................................................................................................................... 5
HDFS 写入剖析:
1. 发请求:客户端向 Namenode 发出写文件请求。
2. 检查:Namenode 检查是否已存在文件、检查权限。(若通过检查,直
接先将操作写入编辑日志(详情见 Namenode 文件目录)),并返回输出流
对象。
3. 切块:client 端按 128MB(默认)一块切分文件,形成数据队列。
4. 返回管线:Namenode 挑选一组合适的 Datanode(按照默认副本存放
策略),称为一个管线。将其返回给客户端。
默认副本存放策略:副本 1.客户端所在节点(离客户端最近);副本 2.不同于第一
下载后可阅读完整内容,剩余5页未读,立即下载
2017-09-07 上传
2021-11-23 上传
2019-08-17 上传
2023-08-27 上传
2024-09-08 上传
2023-08-17 上传
2023-06-15 上传
2023-09-11 上传
2023-09-24 上传









