Spark2.3 HA集群分布式安装详教程:图文实战
33 浏览量
更新于2024-09-09
收藏 1.11MB PDF 举报
Spark学习笔记(二)详细介绍了Spark 2.3版本的高可用性(High Availability, HA)集群的分布式安装过程。该指南以图文并茂的形式,涵盖了从下载Spark安装包、安装前提条件、安装步骤到实际操作的各个环节。
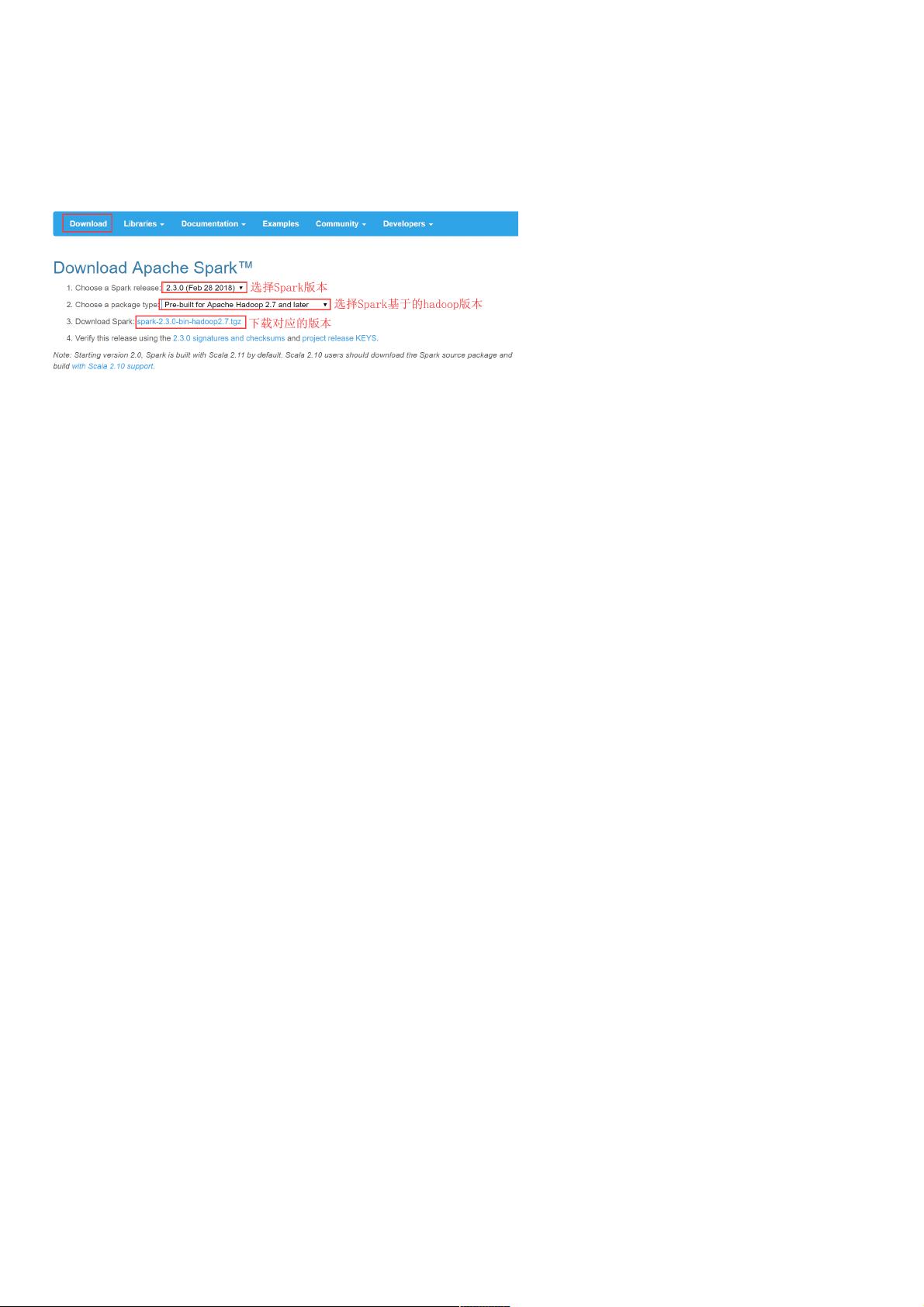
首先,作者建议从Apache官网(<http://spark.apache.org/downloads.html>)、微软镜像站(<http://mirrors.hust.edu.cn/apache/>)或清华大学镜像站(<https://mirrors.tuna.tsinghua.edu.cn/apache/>)下载Spark 2.3的安装包,确保使用的是与Hadoop 2.7.5兼容的版本。
安装前,需要确保Java 8、Zookeeper以及Hadoop 2.7.5已经成功安装。Java是Spark运行的基础,Zookeeper负责集群的协调服务,而Hadoop是Spark构建在之上的大数据处理框架。Scala语言(尽管不是必需的,但Spark的很多应用需要用到)也需要预先安装。
安装过程中,用户需要将下载的Spark安装包`spark-2.3.0-bin-hadoop2.7.tgz`解压到`apps`目录,并创建一个软链接指向Spark的bin目录,以便于后续的命令行操作。这一步对于在多个节点间共享Spark环境至关重要。
接着,读者可以按照文章中的示例进行操作,例如查看当前目录的文件结构,确认安装包的存在,以及创建软链接等。这些步骤旨在确保Spark环境的整洁和一致性。
最后,通过实例演示了如何启动Spark HA集群,包括配置环境变量、启动Spark Master和Worker节点,以及执行Spark程序。这些操作涉及配置核心的spark-env.sh文件,设置SPARK_HOME和HADOOP_CONF_DIR等环境变量,以及启动`sbin/start-master.sh`和`sbin/start-slave.sh`命令。
这篇Spark学习笔记提供了详细的Spark 2.3 HA集群分布式安装指导,帮助读者理解并实践如何在一个集群环境中部署和管理Spark,这对于任何希望在大数据处理场景中使用Spark的开发者来说,都是非常实用的参考资料。
Spark学习笔记学习笔记 (二)(二)Spark2.3 HA集群的分布式安装图文详解集群的分布式安装图文详解
主要介绍了Spark2.3 HA集群的分布式安装,结合图文与实例形式详细分析了Spark2.3 HA集群分布式安装具体下载、安装、配置、启动及执行spark程序等相关操作技巧,需要的朋友
可以参考下
本文实例讲述了Spark2.3 HA集群的分布式安装。分享给大家供大家参考,具体如下:
一、下载一、下载Spark安装包安装包
1、从官网下载、从官网下载
http://spark.apache.org/downloads.html
2、从微软的镜像站下载、从微软的镜像站下载
http://mirrors.hust.edu.cn/apache/
3、从清华的镜像站下载、从清华的镜像站下载
https://mirrors.tuna.tsinghua.edu.cn/apache/
二、安装基础二、安装基础
1、Java8安装成功
2、zookeeper安装成功
3、hadoop2.7.5 HA安装成功
4、Scala安装成功(不安装进程也可以启动)
三、三、Spark安装过程安装过程
1、上传并解压缩、上传并解压缩
[hadoop@hadoop1 ~]$ ls
apps data exam inithive.conf movie spark-2.3.0-bin-hadoop2.7.tgz udf.jar
cookies data.txt executions json.txt projects student zookeeper.out
course emp hive.sql log sougou temp
[hadoop@hadoop1 ~]$ tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C apps/
2、为安装包创建一个软连接、为安装包创建一个软连接
[hadoop@hadoop1 ~]$ cd apps/
[hadoop@hadoop1 apps]$ ls
hadoop-2.7.5 hbase-1.2.6 spark-2.3.0-bin-hadoop2.7 zookeeper-3.4.10 zookeeper.out
[hadoop@hadoop1 apps]$ ln -s spark-2.3.0-bin-hadoop2.7/ spark
[hadoop@hadoop1 apps]$ ll
总用量 36
drwxr-xr-x. 10 hadoop hadoop 4096 3月 23 20:29 hadoop-2.7.5
drwxrwxr-x. 7 hadoop hadoop 4096 3月 29 13:15 hbase-1.2.6
lrwxrwxrwx. 1 hadoop hadoop 26 4月 20 13:48 spark -> spark-2.3.0-bin-hadoop2.7/
drwxr-xr-x. 13 hadoop hadoop 4096 2月 23 03:42 spark-2.3.0-bin-hadoop2.7
drwxr-xr-x. 10 hadoop hadoop 4096 3月 23 2017 zookeeper-3.4.10
-rw-rw-r--. 1 hadoop hadoop 17559 3月 29 13:37 zookeeper.out
[hadoop@hadoop1 apps]$
3、进入、进入spark/conf修改配置文件修改配置文件
(1)进入配置文件所在目录
[hadoop@hadoop1 ~]$ cd apps/spark/conf/
[hadoop@hadoop1 conf]$ ll
总用量 36
-rw-r--r--. 1 hadoop hadoop 996 2月 23 03:42 docker.properties.template
-rw-r--r--. 1 hadoop hadoop 1105 2月 23 03:42 fairscheduler.xml.template
-rw-r--r--. 1 hadoop hadoop 2025 2月 23 03:42 log4j.properties.template
-rw-r--r--. 1 hadoop hadoop 7801 2月 23 03:42 metrics.properties.template
-rw-r--r--. 1 hadoop hadoop 865 2月 23 03:42 slaves.template
-rw-r--r--. 1 hadoop hadoop 1292 2月 23 03:42 spark-defaults.conf.template
-rwxr-xr-x. 1 hadoop hadoop 4221 2月 23 03:42 spark-env.sh.template
[hadoop@hadoop1 conf]$
(2)复制spark-env.sh.template并重命名为spark-env.sh,并在文件最后添加配置内容
[hadoop@hadoop1 conf]$ cp spark-env.sh.template spark-env.sh
[hadoop@hadoop1 conf]$ vi spark-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_73
#export SCALA_HOME=/usr/share/scala
export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.5
export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-2.7.5/etc/hadoop
export SPARK_WORKER_MEMORY=500m
export SPARK_WORKER_CORES=1
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181 -Dspark.deploy.zookeeper.dir=/spark"
注:
#export SPARK_MASTER_IP=hadoop1 这个配置要注释掉。
集群搭建时配置的spark参数可能和现在的不一样,主要是考虑个人电脑配置问题,如果memory配置太大,机器运行很慢。
说明:
-Dspark.deploy.recoveryMode=ZOOKEEPER #说明整个集群状态是通过zookeeper来维护的,整个集群状态的恢复也是通过zookeeper来维护的。就是说用zookeeper做了spark的HA配
置,Master(Active)挂掉的话,Master(standby)要想变成Master(Active)的话,Master(Standby)就要像zookeeper读取整个集群状态信息,然后进行恢复所有Worker和Driver的状态信息,和
所有的Application状态信息;
-Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181#将所有配置了zookeeper,并且在这台机器上有可能做master(Active)的机器都配置进来;(我用
下载后可阅读完整内容,剩余9页未读,立即下载
2024-03-08 上传
2022-08-07 上传
2023-06-14 上传
2024-07-18 上传
2021-05-26 上传
2024-09-16 上传
2021-05-26 上传

weixin_38625599
- 粉丝: 8
- 资源: 867
 我的内容管理
展开
我的内容管理
展开







最新资源
- Raspberry Pi OpenCL驱动程序安装与QEMU仿真指南
- Apache RocketMQ Go客户端:全面支持与消息处理功能
- WStage平台:无线传感器网络阶段数据交互技术
- 基于Java SpringBoot和微信小程序的ssm智能仓储系统开发
- CorrectMe项目:自动更正与建议API的开发与应用
- IdeaBiz请求处理程序JAVA:自动化API调用与令牌管理
- 墨西哥面包店研讨会:介绍关键业绩指标(KPI)与评估标准
- 2014年Android音乐播放器源码学习分享
- CleverRecyclerView扩展库:滑动效果与特性增强
- 利用Python和SURF特征识别斑点猫图像
- Wurpr开源PHP MySQL包装器:安全易用且高效
- Scratch少儿编程:Kanon妹系闹钟音效素材包
- 食品分享社交应用的开发教程与功能介绍
- Cookies by lfj.io: 浏览数据智能管理与同步工具
- 掌握SSH框架与SpringMVC Hibernate集成教程
- C语言实现FFT算法及互相关性能优化指南
