
爬取北京市公交线路信息爬取北京市公交线路信息
这篇文章主要讲述了爬取北京市公交线路信息的整个过程,对于小白还是极为友好的,细节解释的比较详细,话不多说,开始探索知识吧。
一、一、Xpath插件插件
1、文件夹格式插件安装
1.首先用户点击谷歌浏览器右上角的自定义及控制按钮,在下拉框中选择设置。
2.在打开的谷歌浏览器的扩展管理器最左侧选择扩展程序。
3.勾选开发者模式,点击加载已解压的扩展程序,将文件夹选择即可安装插件。
2、使用方式
(1)打开方式快捷键
Ctrl+Shift+X,如果打不开,就重新加载一下
(2)取元素的XPath
按住Shift键,将鼠标移到需要定位的元素上,该元素会以黄色底纹高亮。左边的XPath编辑框内会显示该元素的XPath路径,右边的节点文本显示框会显
示该元素的文本内容。
(3)检验XPath路径
在编辑框内输入自己事先写好的XPath路径,检查书写是否有误。
二、爬取第一页所有的导航链接二、爬取第一页所有的导航链接
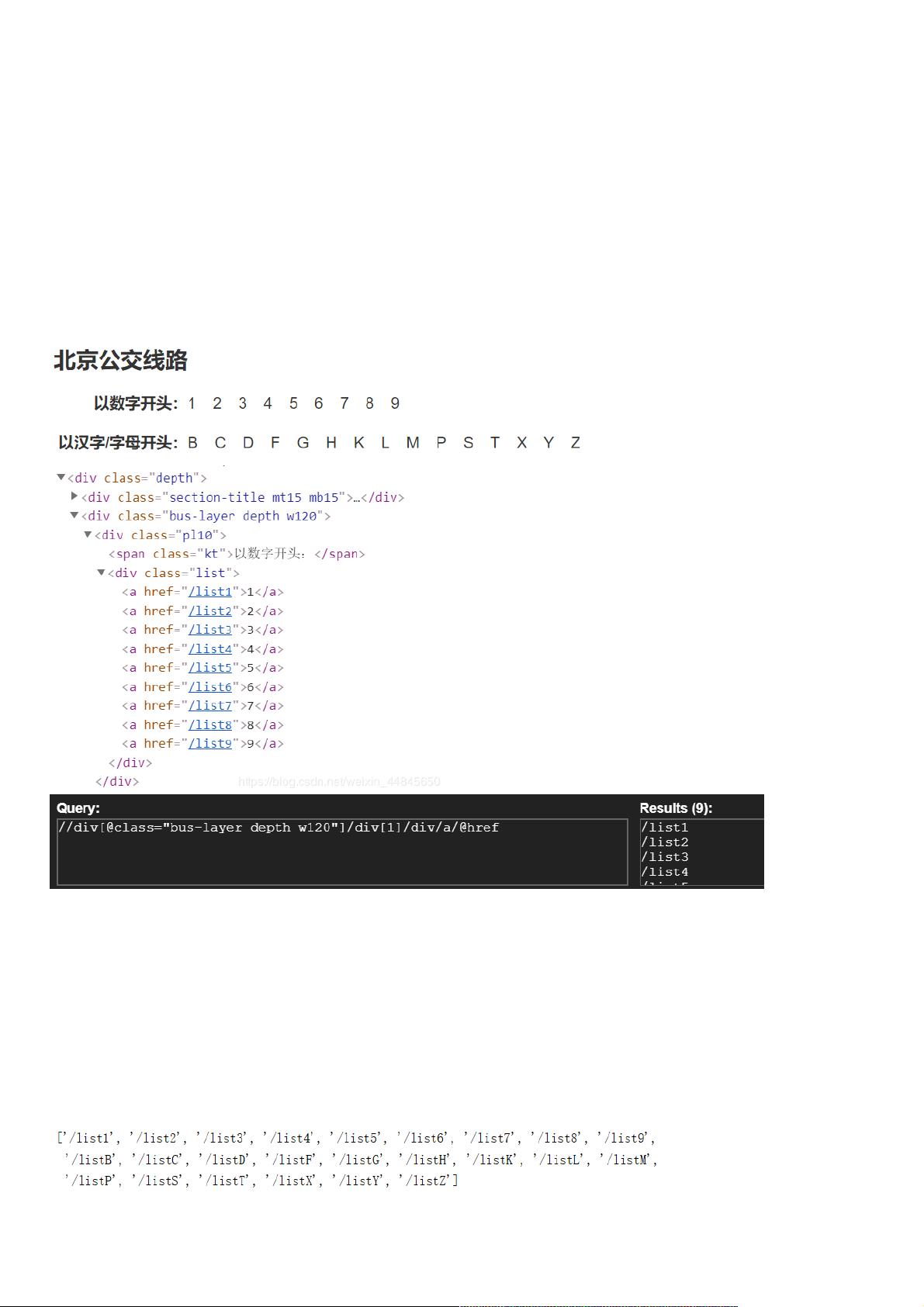
以爬取数字1开头的公交线路为例,一级网页:beijing.8684.cn/,二级网页:beijing.8684.cn/list1,就多了一个/list1,所以就要在一级网页中找到/list1,在一
级网页基础上加上即可,其余以此类推。那么如何准确找到以1开头的公交线路的/list1呢,用xpath。
代码解读为://div[@class=“bus-layer depth w120”]表示要获取class=”bus-layer depth w120″下面的值,/div[1]表示获取class=”bus-layer depth w120″下面第一
个div的值,/div/a/@href表示获取div下a中herf的值,也就是/list1,可以找到lint1-9共9个结果,分别对应1-9开头的公交车。总之就是从上到下,层层递进,找到
你唯一想找到的东东,可以通过/div[@]直接取值,也可以通过div[1]索引取值。
#爬取第一页所有的导航链接
def parse_navigation():
url = 'https://beijing.8684.cn/'
req = requests.get(url, headers=headers)
#解析内容,获取所有的导航链接
tree=etree.HTML(req.text)
#查找以数字开头的所有链接
number_herf_list=tree.xpath('//div[@class="bus-layer depth w120"]/div[1]/div/a/@href')
#查找以字母开头的所有链接
char_herf_list=tree.xpath('//div[@class="bus-layer depth w120"]/div[2]/div/a/@href')
#将所有爬取到的链接返回
return number_herf_list+char_herf_list
# return number_herf_list
运行结果:
三、爬取二级页面,需要找到以三、爬取二级页面,需要找到以1开头的所有路线的开头的所有路线的url
思路与上面一致,先看看该网页与上级网页网址有什么区别,一级网页:beijing.8684.cn/,三级页面:https://beijing.8684.cn/x_322e21c5,现在的目标就是
爬取以1开头所有公交车的值,为请求三级页面打基础。
遍历上面的列表,依次发送请求,解析内容,获取每一个页面所有公交线路的url,先进入二级网页,再解析二级网页的内容。

weixin_38618094
- 粉丝: 4
- 资源: 912
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- VMP技术解析:Handle块优化与壳模板初始化
- C++ Primer 第四版更新:现代编程风格与标准库
- 计算机系统基础实验:缓冲区溢出攻击(Lab3)
- 中国结算网上业务平台:证券登记操作详解与常见问题
- FPGA驱动的五子棋博弈系统:加速与创新娱乐体验
- 多旋翼飞行器定点位置控制器设计实验
- 基于流量预测与潮汐效应的动态载频优化策略
- SQL练习:查询分析与高级操作
- 海底数据中心散热优化:从MATLAB到动态模拟
- 移动应用作业:MyDiaryBook - Google Material Design 日记APP
- Linux提权技术详解:从内核漏洞到Sudo配置错误
- 93分钟快速入门 LaTeX:从入门到实践
- 5G测试新挑战与罗德与施瓦茨解决方案
- EAS系统性能优化与故障诊断指南
- Java并发编程:JUC核心概念解析与应用
- 数据结构实验报告:基于不同存储结构的线性表和树实现
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


