
kaggle练习练习-共享单车数据分析共享单车数据分析
项目背景:提供两年的每小时租金数据。训练集是每个月的前19天,而测试集是每月的20号到月底。必须仅使用租借期之前的可用信息来预测测试集涵盖的每个小时内租用的自行车
总数。
一、载入数据一、载入数据
1.1收集数据收集数据
一般而言,数据由甲方提供。若甲方不提供数据,则需要根据相关问题从网络爬取,或者以问卷调查形式收集。本次共享单车数据分析项目数据源于Kaggle
[https://www.kaggle.com/c/bike-sharing-demand/data]。
1.2 载入数据载入数据
// 载入工具包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from datetime import datetime
import matplotlib
from sklearn.ensemble import RandomForestRegressor
from sklearn.grid_search import GridSearchCV
%matplotlib inline
// 载入数据
train=pd.read_csv('/python/bike-sharingdemand/train.csv')
test=pd.read_csv('/python/bike-sharing-demand/test.csv')
//查看数据前5行
train.head()
//查看数据基本信息
train.info()
test.info()
训练数据共有12列,10886样本,并且数据无缺失;测试数据共有9列,6493样本。测试数据相对于训练数据,缺少casual(未注册用户租车数量)、registered(注册用户租车数
量)、count(总租车数量)三列,这需要通过最终的模型预测得出。
特征说明特征说明
datetime:时间。年月日小时格式
season:季节。1:春天;2:夏天;3:秋天;4:冬天
holiday:是否节假日。0:否;1:是
workingday:是否工作日。0:否;1:是
weather:天气。1:晴天;2:阴天;3:小鱼或小雪;4:恶劣天气
temp:实际温度
atemp:体感温度
humidity:湿度
windspeed:风速
casual:未注册用户租车数量
registered:注册用户租车数量
count:总租车数量
二、数据预处理二、数据预处理
2.1数据缺失值处理数据缺失值处理
//查看数据基本信息
train.info()
test.info()
数据没有缺失值,因此不需要进行缺失值的处理
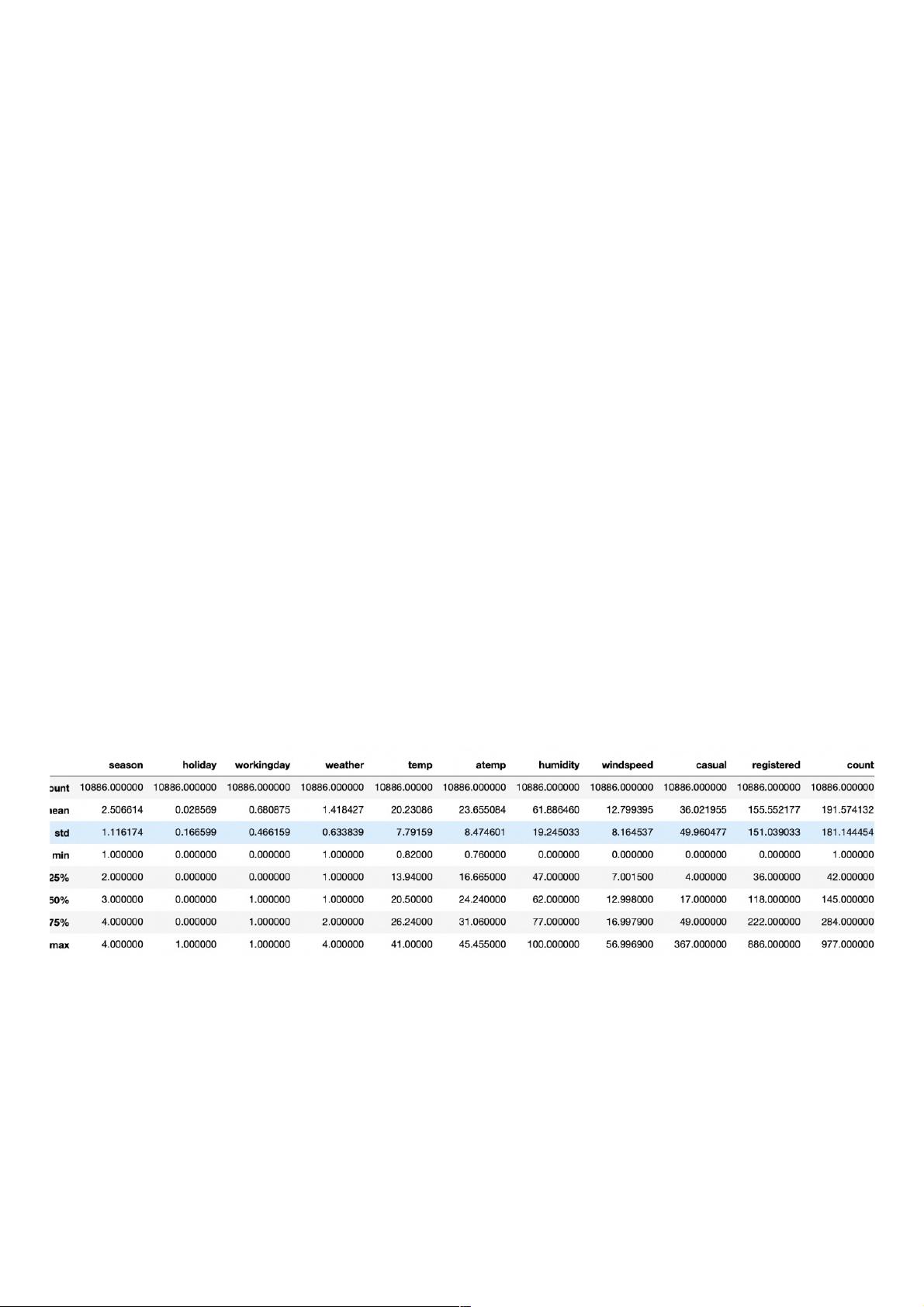
2.2 数据异常值处理数据异常值处理
//数据描述
train.describe()
原创文章 1获赞 0访问量 21
关注
私信
展开阅读全文
作者:muxuehan0

weixin_38607026
- 粉丝: 8
- 资源: 914
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0