
Python机器学习算法之机器学习算法之k均值聚类(均值聚类(k-means))
主要为大家详细介绍了Python机器学习算法之k均值聚类,具有一定的参考价值,感兴趣的小伙伴们可以参考一
下
一开始的目的是学习十大挖掘算法(机器学习算法),并用编码实现一遍,但越往后学习,越往后实现编码,越发现自己的编
码水平低下,学习能力低。这一个k-means算法用Python实现竟用了三天时间,可见编码水平之低,而且在编码的过程中看了
别人的编码,才发现自己对numpy认识和运用的不足,在自己的代码中有很多可以优化的地方,比如求均值的地方可以用
mean直接对数组求均值,再比如去最小值的下标,我用的是argsort排序再取列表第一个,但是有argmin可以直接用啊。下面
的代码中这些可以优化的并没有改,这么做的原因是希望做到抛砖引玉,欢迎大家丢玉,如果能给出优化方法就更好了
一一.k-means算法算法
人以类聚,物以群分,k-means聚类算法就是体现。数学公式不要,直接用白话描述的步骤就是:
1.随机选取k个质心(k值取决于你想聚成几类)
2.计算样本到质心的距离,距离质心距离近的归为一类,分为k类
3.求出分类后的每类的新质心
4.判断新旧质心是否相同,如果相同就代表已经聚类成功,如果没有就循环2-3直到相同
用程序的语言描述就是:
1.输入样本
2.随机去k个质心
3.重复下面过程知道算法收敛:
计算样本到质心距离(欧几里得距离)
样本距离哪个质心近,就记为那一类
计算每个类别的新质心(平均值)
二二.需求分析需求分析
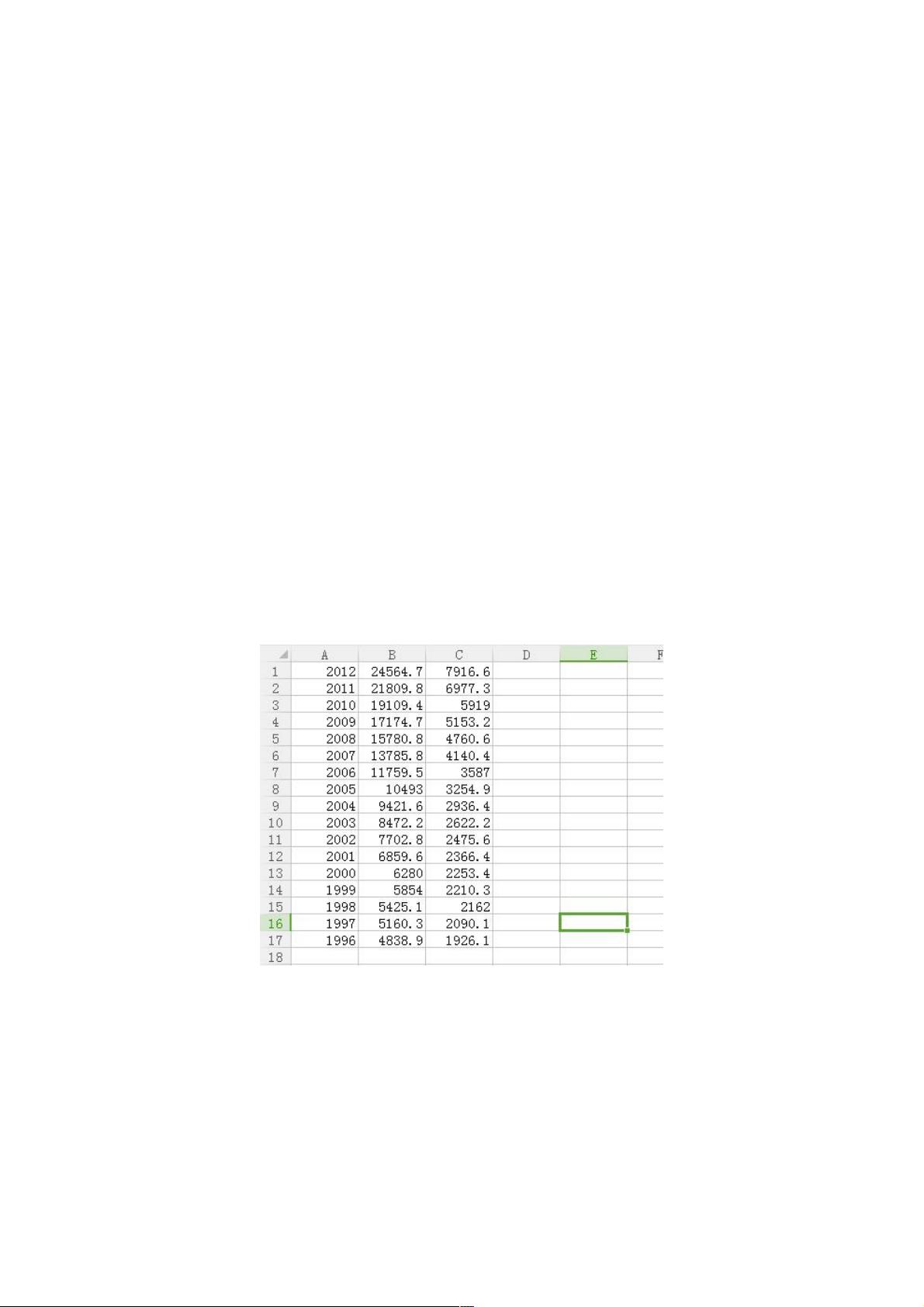
数据来源:从国际统计局down的数据,数据为城乡居民家庭人均收入及恩格尔系数(点击这里下载)
数据描述:
1.横轴:城镇居民家庭人均可支配收入和农村居民家庭人均纯收入,
2.纵轴:1996-2012年。
3.数据为年度数据
需求说明:我想把这数据做个聚类分析,看人民的收入大概经历几个阶段(感觉我好高大上啊)
需求分析:
1.由于样本数据有限,就两列,用k-means聚类有很大的准确性
2.用文本的形式导入数据,结果输出聚类后的质心,这样就能看出人民的收入经历了哪几个阶段
三三.Python实现实现
引入numpy模块,借用其中的一些方法进行数据处理,上代码:

weixin_38701312
- 粉丝: 8
- 资源: 947
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论0