Generating Long-term Trajectories Using Deep
Hierarchical Networks
Stephan Zheng
Caltech
stzheng@caltech.edu
Yisong Yue
Caltech
yyue@caltech.edu
Patrick Lucey
STATS
plucey@stats.com
Abstract
We study the problem of modeling spatiotemporal trajectories over long time
horizons using expert demonstrations. For instance, in sports, agents often choose
action sequences with long-term goals in mind, such as achieving a certain strategic
position. Conventional policy learning approaches, such as those based on Markov
decision processes, generally fail at learning cohesive long-term behavior in such
high-dimensional state spaces, and are only effective when fairly myopic decision-
making yields the desired behavior. The key difficulty is that conventional models
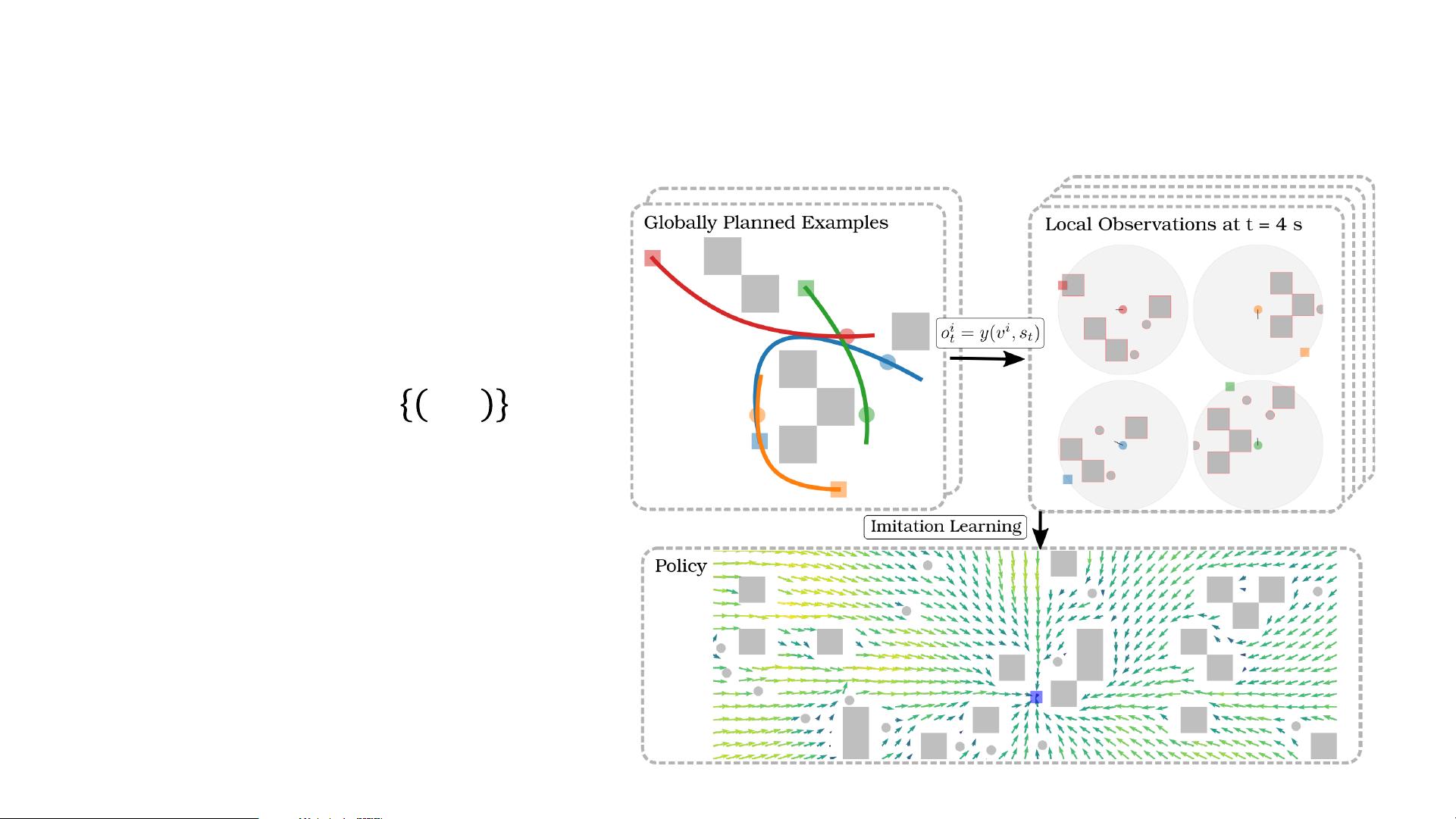
are “single-scale” and only learn a single state-action policy. We instead propose a
hierarchical policy class that automatically reasons about both long-term and short-
term goals, which we instantiate as a hierarchical neural network. We showcase our
approach in a case study on learning to imitate demonstrated basketball trajectories,
and show that it generates significantly more realistic trajectories compared to
non-hierarchical baselines as judged by professional sports analysts.
1 Introduction
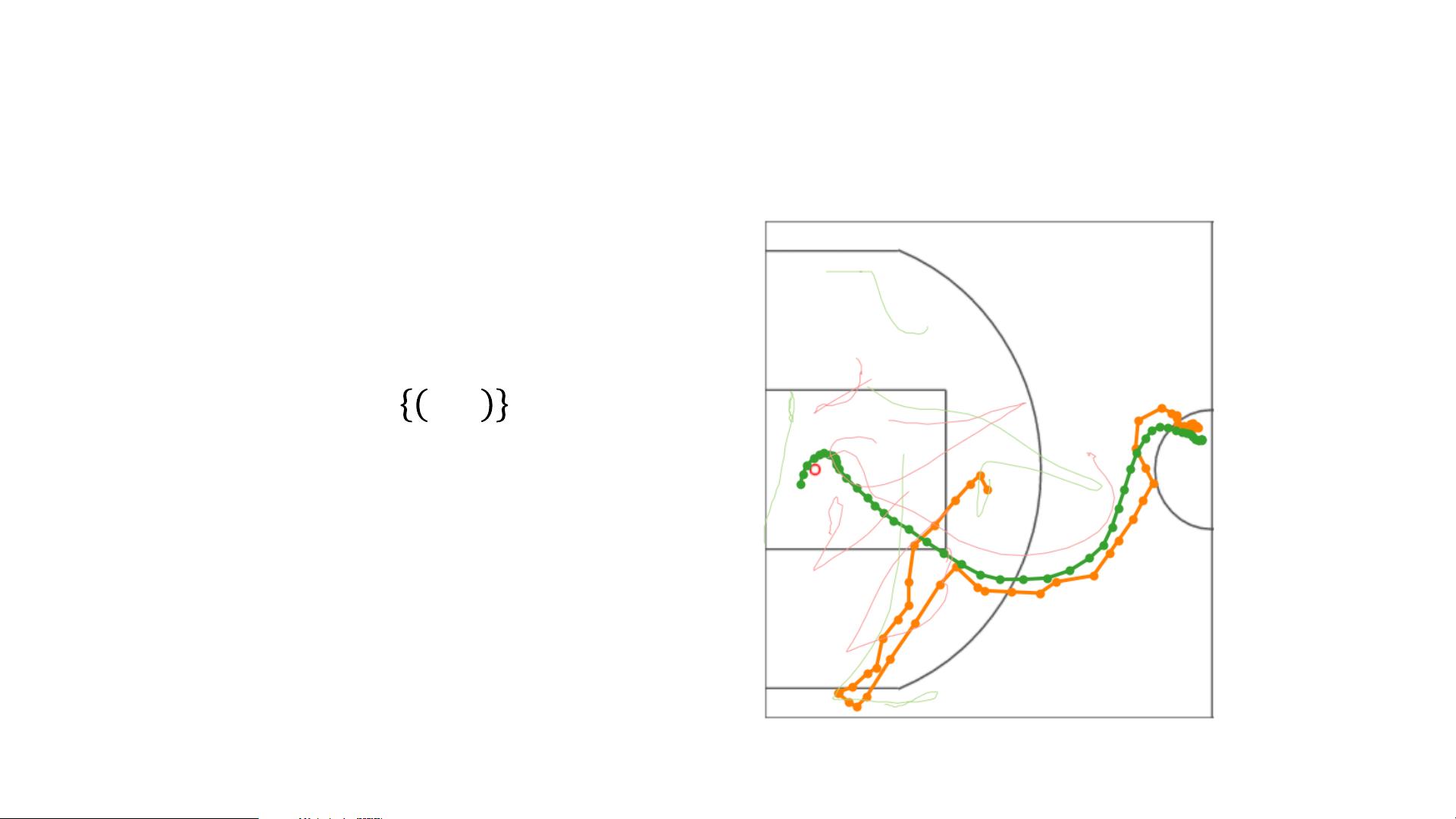
Figure 1: The player (green)
has two macro-goals: 1)
pass the ball (orange) and
2) move to the basket.
Modeling long-term behavior is a key challenge in many learning prob-
lems that require complex decision-making. Consider a sports player
determining a movement trajectory to achieve a certain strategic position.
The space of such trajectories is prohibitively large, and precludes conven-
tional approaches, such as those based on simple Markovian dynamics.
Many decision problems can be naturally modeled as requiring high-level,
long-term macro-goals, which span time horizons much longer than the
timescale of low-level micro-actions (cf. He et al.
[8]
, Hausknecht and
Stone
[7]
). A natural example for such macro-micro behavior occurs in
spatiotemporal games, such as basketball where players execute complex
trajectories. The micro-actions of each agent are to move around the
court and, if they have the ball, dribble, pass or shoot the ball. These
micro-actions operate at the centisecond scale, whereas their macro-goals,
such as "maneuver behind these 2 defenders towards the basket", span
multiple seconds. Figure 1 depicts an example from a professional basketball game, where the player
must make a sequence of movements (micro-actions) in order to reach a specific location on the
basketball court (macro-goal).
Intuitively, agents need to trade-off between short-term and long-term behavior: often sequences of
individually reasonable micro-actions do not form a cohesive trajectory towards a macro-goal. For
instance, in Figure 1 the player (green) takes a highly non-linear trajectory towards his macro-goal of
positioning near the basket. As such, conventional approaches are not well suited for these settings,
as they generally use a single (low-level) state-action policy, which is only successful when myopic
or short-term decision-making leads to the desired behavior.
30th Conference on Neural Information Processing Systems (NIPS 2016), Barcelona, Spain.




 我的内容管理
收起
我的内容管理
收起
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助 







评论0