
利用利用Python进行心脏病患者特征分析进行心脏病患者特征分析
今天要跟大家说到的一个数据集分析,是关于心脏病的。心脏病作为全球第一大杀手,是我们不得不提前防御的疾病。今天我
们利用Python从一份心脏病数据集中找出一些规律,看下哪些特征对于确诊心脏病影响比较大,从而提醒我们注意平时的生
活规律。
数据集介绍数据集介绍
数据分析之前,先得有数据集,首先先来介绍一下这份kaggle上下载的数据集。
对其中的字段进行分析:
age:年龄。
sex:性别(1:男,0:女)
cp:疼痛类型(1:典型心绞痛,2:非典型心绞痛,3:非心绞痛,4:没有症状(不痛))
trestbps:静息血压。
chol:胆固醇。
fbs:血糖(>120mg/dl为1,否则为0)
restecg:心电图(0:正常,1:异常,2:严重)
thalach:达到的最高心率。
exang:运动诱发心绞痛(1:是的,0:不是)
oldpeak:运动相对于休息引起的ST期抑郁
slope:运动高峰的心电图(1:上坡,2:平和,3:下坡)
ca:主要血管数目(0-3)
thal:地中海贫血(3:普通。6:固定的缺陷,7:可逆的缺陷)。
target:心脏疾病诊断(0:没有心脏病,1:有心脏病)
这份数据集,记录的都是生理的特征,但是我们可以根据这些特征,来反向关注生活习惯。比如胆固醇,蛋黄、猪肝都是引起
胆固醇过高的食物,如果我们后面分析后,发现胆固醇过高会引起心脏病,那么平时就要注意少吃这些食物了。
数据分析数据分析-性别特征性别特征
接下来对这个数据集进行一波分析了,我们尽可能多的分析某些特征对于心脏病的影响。需要说一下,这里我们用到的依然是
pandas+seaborn的技术栈(需要完整代码私信“心脏病”即可获取)。先来看下性别比例吧:
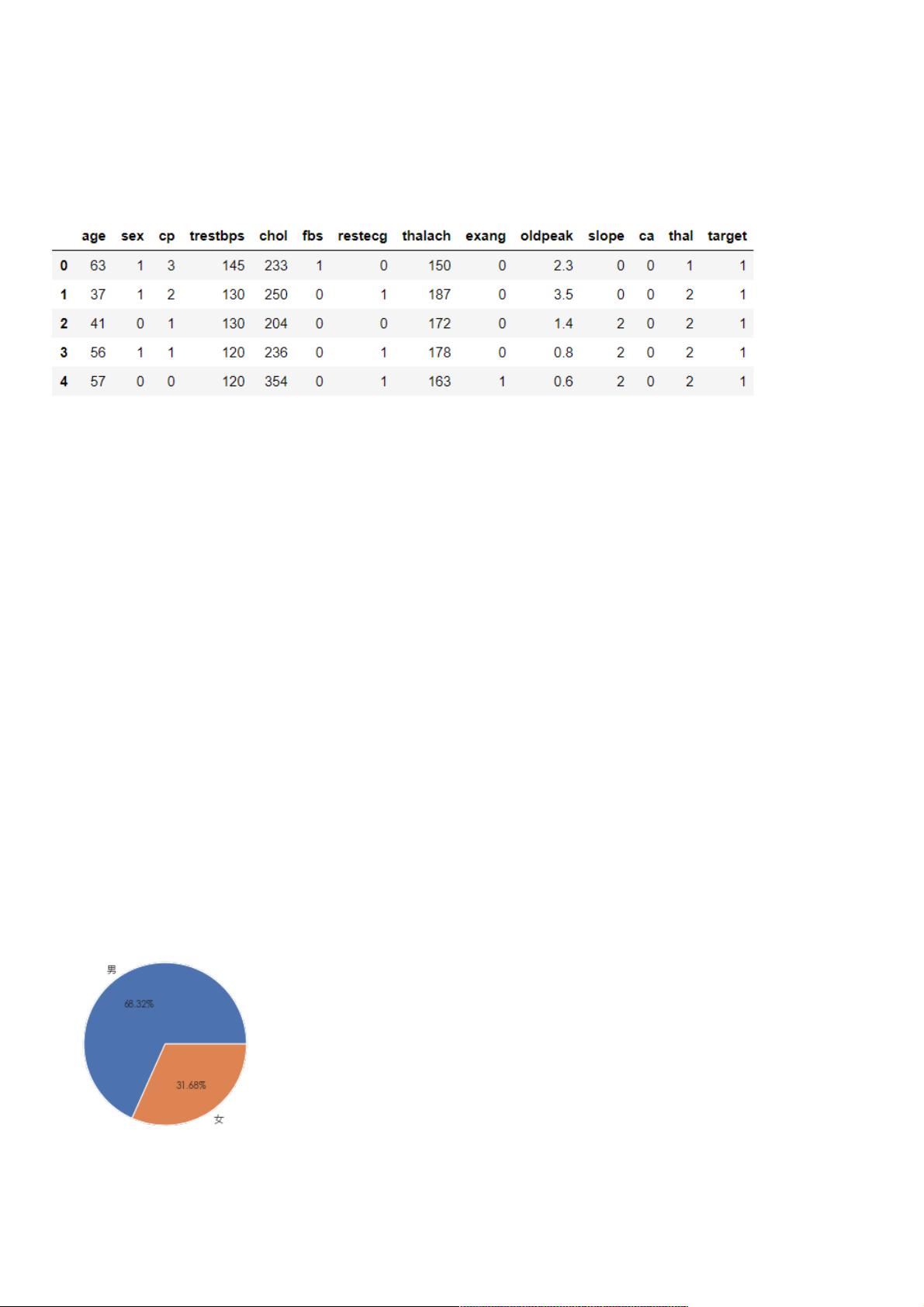
# 性别因素
gender_dist = df['sex'].value_counts()
plt.pie(gender_dist.values,labels=['男','女'],autopct="%.2f%%")
print(gender_dist)
>> 1 207
>> 0 96
其中男性207,女性96,男性的占到了接近70%了。但这个并不是有70%的男性得了心脏病,而是这份数据集的男女比例。那
接下来再来看下,不同的性别患心脏病的分布情况。代码如下:
fig,axes = plt.subplots(1,3,figsize=(15,4))
g_target_dist = df.groupby(['sex','target']).count()['age'].unstack()

等你下课⊙▽⊙
- 粉丝: 290
- 资源: 963
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- zigbee-cluster-library-specification
- JSBSim Reference Manual
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈


