预训练语言模型驱动的机器阅读理解进展与挑战
需积分: 47 40 浏览量
更新于2024-07-09
收藏 17.21MB PDF 举报
机器阅读理解(Machine Reading Comprehension, MRC)是自然语言处理(Natural Language Processing, NLP)领域的一个核心挑战,其目标是使机器能够理解并从文本中获取信息。随着深度学习技术的兴起,特别是上下文语言模型(Contextualized Language Models, CLM)的进步,MRC的研究经历了一次显著的飞跃。在21世纪信息技术会议上,Zhuosheng Zhang和Hai Zhao两位专家将通过IJCAI-21教程深入探讨这一主题。
MRC可以分为两大类:一是基础NLP,涵盖了语言模型、语言表示、语法结构分析等核心任务,如词法分析和句法语义解析;二是应用NLP,其中MRC作为关键应用,目的是训练机器理解并回答问题,比如像SNLI和GLUE这样的文本蕴含或自然语言推理任务。此外,MRC还涉及问答系统和对话系统,以及机器翻译等领域。
预训练语言模型在MRC中扮演了至关重要的角色。这些模型,如BERT、GPT等,通过对大量未标注数据进行自我监督学习,学会了捕捉词汇和句子级别的上下文依赖关系,从而极大地提高了理解和生成文本的能力。预训练后,模型可以通过微调适应特定任务,如问答系统中的提取式问答或生成式问答,显著提升性能。
在教程中,第一部分由Zhuosheng Zhang介绍MRC的基本概念和最新进展,包括不同类型的阅读理解任务及其挑战。接着,Hai Zhao将详细讲解预训练语言模型的工作原理、优势以及在MRC中的实际应用案例。最后,两位专家会讨论技术方法、当前研究热点及未来前沿方向,包括模型的优化、多模态融合以及跨语言MRC等。
整个教程旨在帮助参与者掌握MRC的基础理论,理解预训练语言模型如何驱动技术进步,并引导他们探索这个领域的潜在研究方向。通过这次深入的分享,与会者不仅能提升自己的专业知识,还能紧跟MRC技术的最新动态。

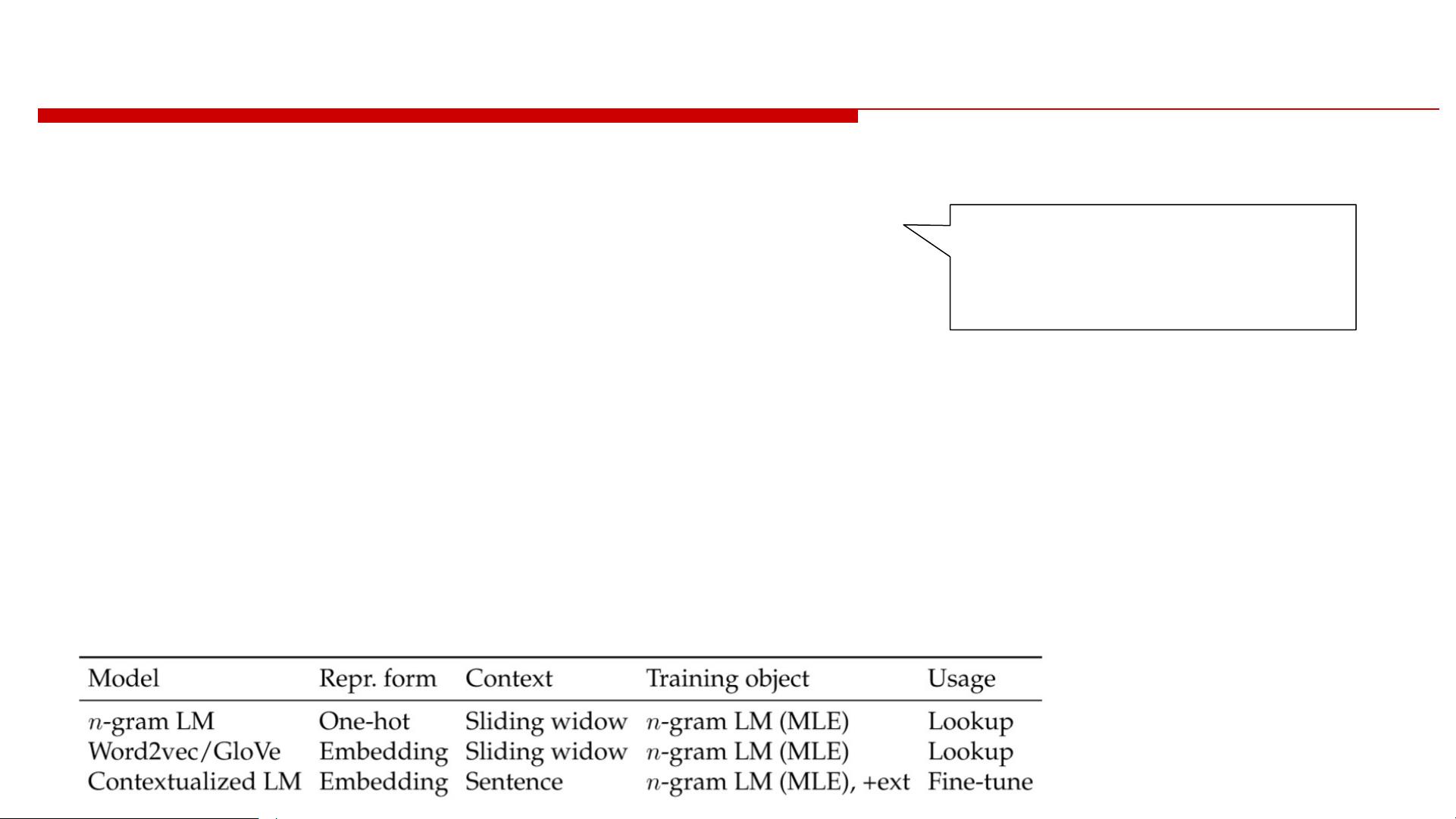
(Sentence/Contextual) Encoder as a Standard Network Block
o Word embeddings have changed NLP
o However, sentence is the least unit that delivers complete meaning as
human use language
o Deep learning for NLP quickly found it is a frequent requirement on
using a network component encoding a sentence input.
l Encoder for encoding the complete sentence-level Context
o Encoder differs from sliding window input that it covers a full sentence.
o It especially matters when we have to handle passages in MRC tasks,
where passage always consists of a lot of sentences (not words).
l When the model faces passages, sentence becomes the basic unit
l Usually building blocks for an encoder: RNN, especially LSTM
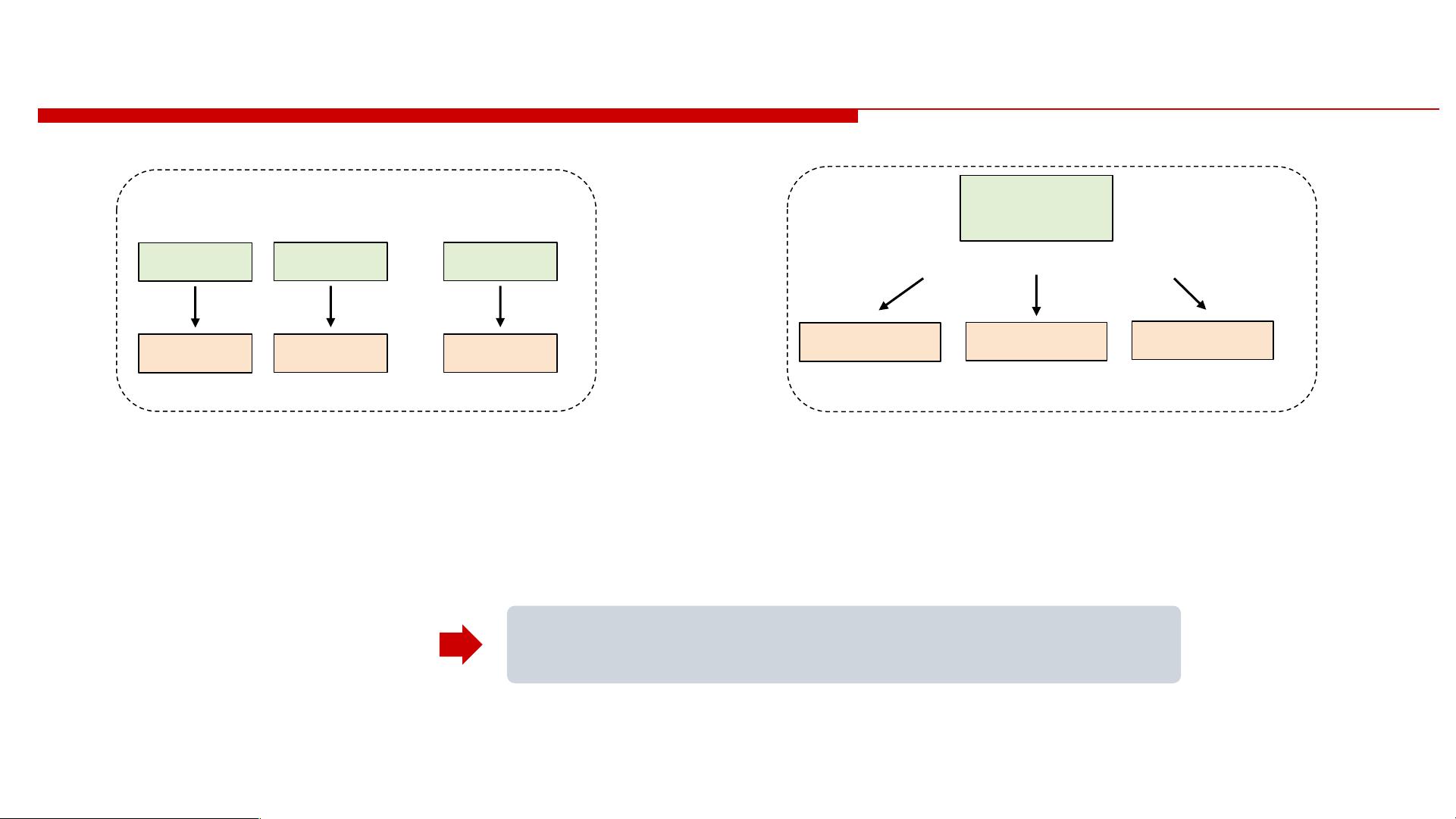
Contextualized Language Encoding
Page 16
Traditional
Contextualization:
Word embedding
+
Sentence Encoder


剩余98页未读,继续阅读
2023-05-18 上传
2021-09-01 上传
2022-04-21 上传
2024-01-06 上传
2024-01-07 上传
2024-12-02 上传
点击了解资源详情
点击了解资源详情
点击了解资源详情

syp_net
- 粉丝: 158
- 资源: 1187
 我的内容管理
展开
我的内容管理
展开







