
下载
即使从最应用性的角度,经济计量学的学习也要求对统计学有较好的了解。我们假设大多
数读者学过统计学,但我们知道这些知识需要更新。在继续学习计量经济学之前,我们将复习
统计学的观点,这些知识将在以后的各阶段中发挥它们的作用。为帮助读者把注意力放在重要
的观点而不是细节上,我们把大部分推导放在附录 2 - 1 中。
2.1 随机变量
随机变量是变量,它可以取不同的值,并且取每一个值的概率小于等于 1。我们可以通过
研究随机变量生成各个取值的过程来描述一个随机变量,这个过程称做概率分布。概率分布列
出所有可能出现的结果及每个结果发生的概率。我们可以将随机变量定义为一个函数,这个函
数为每一个试验结果赋予一个实数值。例如,假设抛硬币出现正面的取值为 1,反面的取值为
0 ( 如果硬币是均匀的,出现正面的概率将为 1 / 2 ) 。此例中我们可以把抛硬币的取值看作一个随
机变量;生成这个随机变量的过程是二项概率分布。
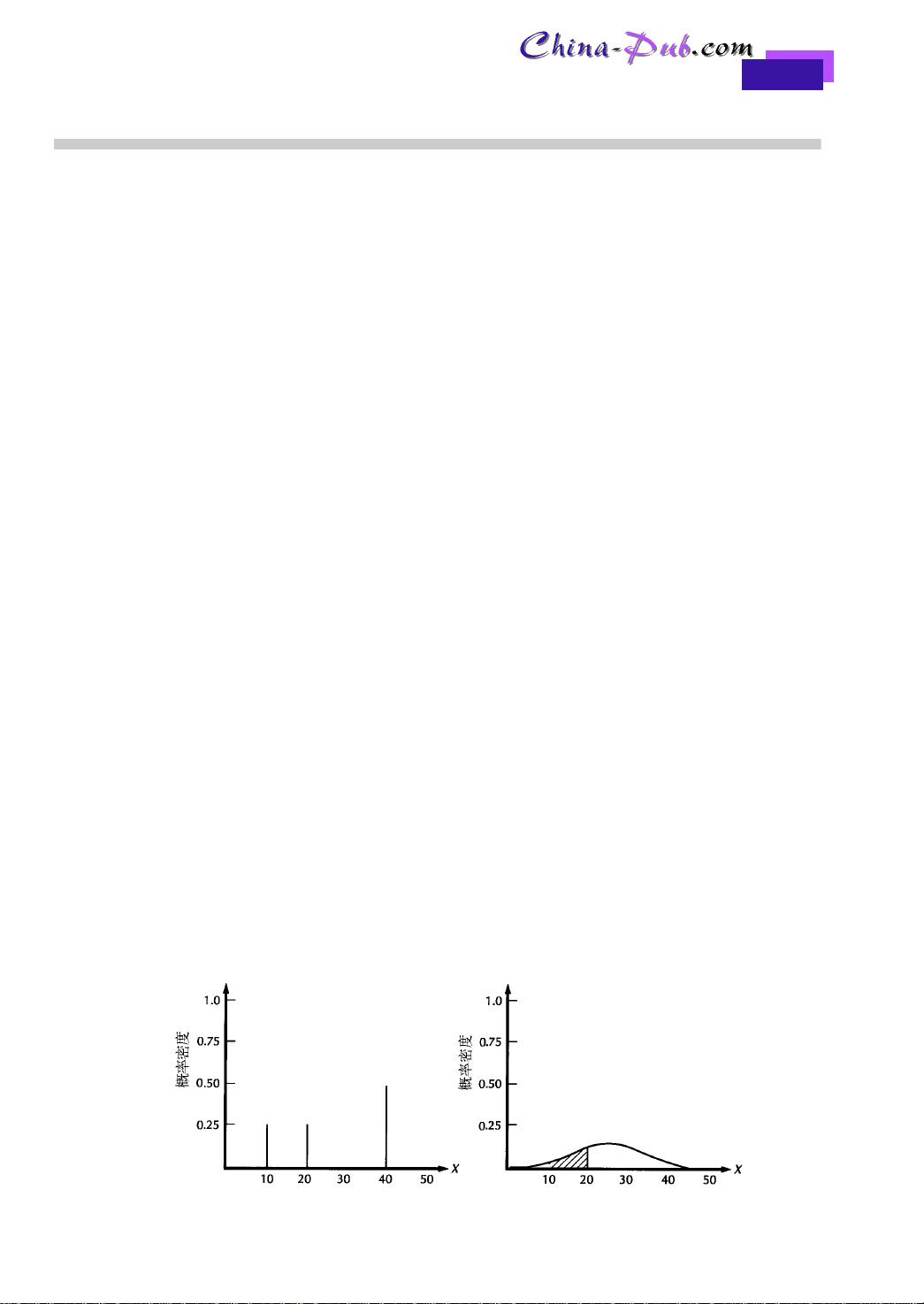
弄清离散型随机变量和连续型随机变量之间的区别是很有用的。一个连续型随机变量可以
取实数轴上的任何值,而一个离散型随机变量只能取若干特定的实数值。图 2 - 1 表示的是离散
型随机变量和连续型随机变量的概率函数。由图 2 - 1 中离散型随机变量的分布,我们看到取值
1 0 和2 0 发生的概率都是0 . 2 5,而取值4 0 发生的概率为0 . 5 0。在图2 - 1的连续型分布中,随机变量
的取值位于某两个值之间的概率是由这两个值之间连续密度函数之下的面积决定的。在此例中,
随机变量取值位于1 0和2 0 之间的概率约等于0 . 3,即图中的阴影部分。
图2-1 概率密度
第
2
章
■ 统计基础知识复习
a) 离散型 b) 连续型


剩余379页未读,继续阅读

清风抚白发
- 粉丝: 1
- 资源: 12
 我的内容管理
收起
我的内容管理
收起
- 我的资源
快来上传第一个资源
 我的收益 登录查看自己的收益
我的收益 登录查看自己的收益 我的积分
登录查看自己的积分
我的积分
登录查看自己的积分
 我的C币
登录后查看C币余额
我的C币
登录后查看C币余额
 我的收藏
我的收藏  我的下载
我的下载  下载帮助
下载帮助

会员权益专享




最新资源
- RTL8188FU-Linux-v5.7.4.2-36687.20200602.tar(20765).gz
- c++校园超市商品信息管理系统课程设计说明书(含源代码) (2).pdf
- 建筑供配电系统相关课件.pptx
- 企业管理规章制度及管理模式.doc
- vb打开摄像头.doc
- 云计算-可信计算中认证协议改进方案.pdf
- [详细完整版]单片机编程4.ppt
- c语言常用算法.pdf
- c++经典程序代码大全.pdf
- 单片机数字时钟资料.doc
- 11项目管理前沿1.0.pptx
- 基于ssm的“魅力”繁峙宣传网站的设计与实现论文.doc
- 智慧交通综合解决方案.pptx
- 建筑防潮设计-PowerPointPresentati.pptx
- SPC统计过程控制程序.pptx
- SPC统计方法基础知识.pptx
资源上传下载、课程学习等过程中有任何疑问或建议,欢迎提出宝贵意见哦~我们会及时处理!
点击此处反馈



评论1