有穷自动机是一种在计算机科学中至关重要的理论工具,用于识别特定语言或模式,特别是正规集。正规集是由正规文法或正规式定义的一类语言,它们能够通过有限步骤的操作来确定是否属于该集合。有穷自动机主要分为两类:确定的有穷自动机(DFA)和不确定的有穷自动机(NFA)。
1. **确定的有穷自动机(DFA)**
DFA 是一种结构更明确的自动机模型,其核心特征是对于每一个输入符号和当前状态,都有且仅有一个确定的后续状态。DFA 的定义包括五个关键元素:
- **状态集 K**:包含有限数量的 states,每个状态代表一个计算状态。
- **输入符号集 Σ**:由有限个 symbols 构成,例如字母、数字或特殊字符。
- **转换函数 f**:K × Σ → K,描述了输入符号作用于当前状态时的转移规则。
- **初始状态 S**:系统开始的起点状态。
- **终态集 Z**:表示可以接受输入序列的集合,通常是唯一的。
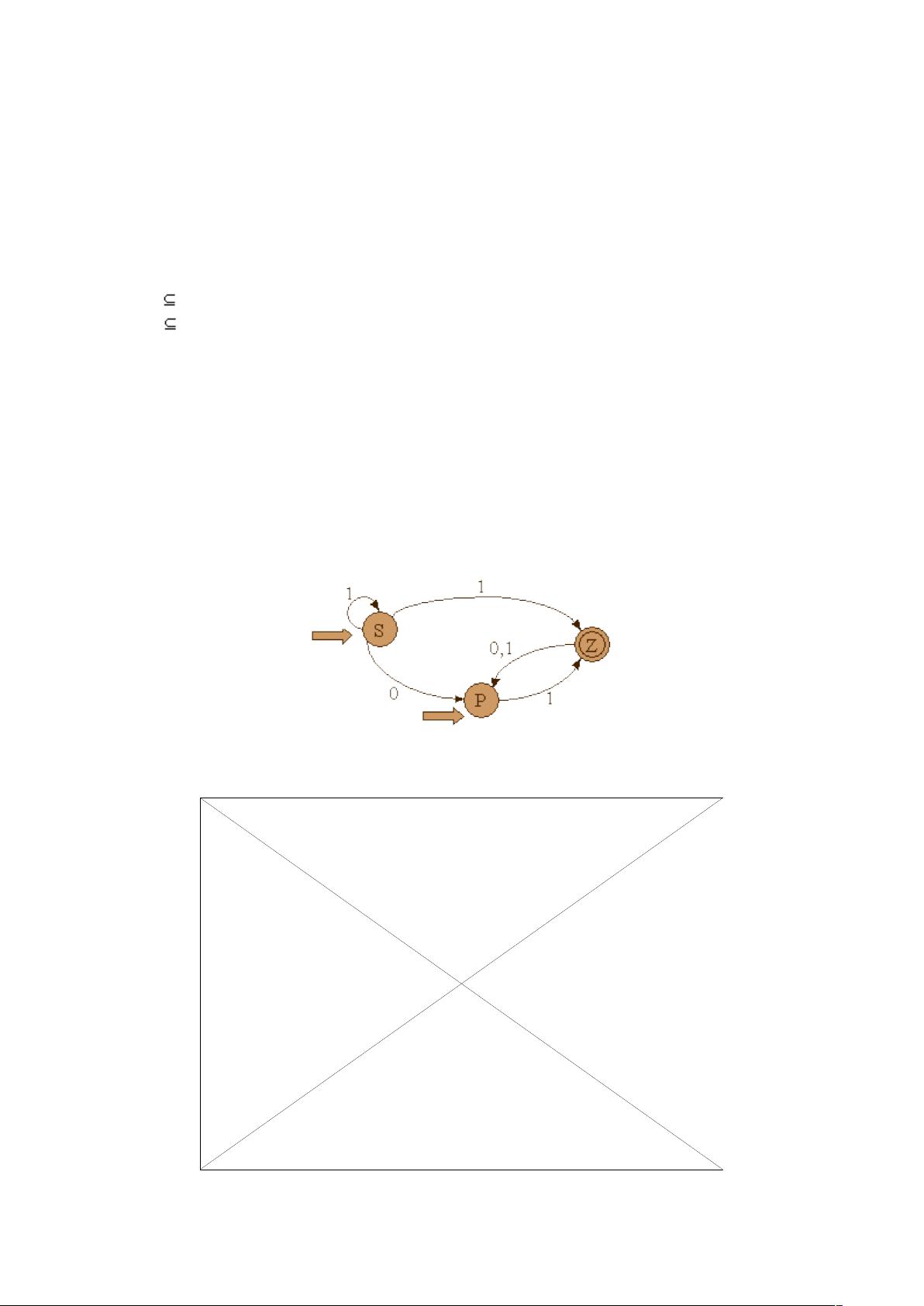
举例说明,给定的 DFA 示例DFAM的定义展示了如何通过状态转移函数f确定输入符号a或b对状态的影响,以及哪些状态是最终状态。
2. **状态图与矩阵表示**
DFA 可以直观地用状态图表示,其中每个节点代表一个状态,带有指向其他状态的弧线,箭头标记输入符号。初始状态用双箭头或减号表示,终态节点则用双圈或加号表示。矩阵形式的DFA描述了状态间的转移关系,行代表当前状态,列代表输入符号,矩阵中的元素表示对应的后续状态。
3. **不确定的有穷自动机(NFA)**
NFA 允许在某些情况下存在多个可能的后续状态,这增加了模型的灵活性,但可能需要额外的确定化步骤来转化为等价的DFA。
4. **理论应用**
有穷自动机理论在编译原理中扮演重要角色,尤其是在词法分析阶段。通过设计DFA,可以自动化识别源代码中的关键字、标识符、运算符等,为后续语法分析和代码生成提供基础。
5. **学习和扩展**
学习有穷自动机包括理解DFA和NFA的概念,掌握状态转换的规则,以及确定化和最小化的算法,这些都是构建高效和可靠的词法分析器的关键技术。
有穷自动机是理论计算机科学的基础,理解并掌握其工作原理,对于理解和设计语言处理系统,特别是编译器的构造至关重要。通过DFA的精确性和NFA的灵活性,程序员可以构建出强大而有效的语言识别工具。