百度分布式文件系统演进:AFS到CCDB-NFS的突破与优化
在CCTC 2016中国云计算技术大会上,百度基础架构部的架构师王耀分享了题为“百度的分布式文件系统之路”的精彩演讲,深入探讨了百度在构建高效、可靠的分布式文件系统方面的经验和挑战。演讲内容涵盖了从开源时代的探索,如GlusterFS、MooseFS和HDFS,到百度内部自主研发的CCDB-NFS和PETA,以及AFS等关键组件。
首先,王耀介绍了分布式文件系统的概念,以MFS(MooseFS)为例,它是基于开源C实现的,提供类似Google File System (GFS) 的功能,支持POSIX标准,具有良好的易用性和数据冗余机制,可以实现数据容错和在线访问。然而,MFS存在单点元信息存储和性能瓶颈的问题,王耀团队通过引入epoll替代poll、增大hash桶大小以及优化fuse参数等方式进行了改进,提升了系统的并发能力和稳定性。
随后,他着重讲述了百度自研的CCDB-NFS,这是基于CCDB(Cloud Control and Data Base)存储体系的分布式文件系统,用于大规模的生产环境部署,支持高可用、强一致性、多租户以及随机读写等功能。CCDB-NFS的架构设计包括分布式元信息管理、文件服务器以及文件数据的存储和管理,采用了链式复制策略来确保数据的一致性。
在CCDB-NFS中,Master节点负责目录树管理和集群控制,而FileServer负责实际的文件数据存储。为了保证性能和可靠性,CCDB采用了多种存储级别,包括内存、SSD、磁盘,并通过ReplicaBlockSystem和Raid-likeBlockSystem实现数据冗余。此外,CCDB还提供了多种引擎,如TableEngine、FileEngine和KVEngine,分别处理元信息、文件数据和对象存储等不同类型的存储需求。
整个演讲不仅揭示了百度在分布式文件系统领域的技术积累,还展示了如何通过技术创新解决分布式系统中的核心问题,如单点故障、性能瓶颈和数据一致性。这是一次关于分布式存储技术的实际应用与优化案例研究,对理解大型互联网公司的技术实践具有很高的参考价值。
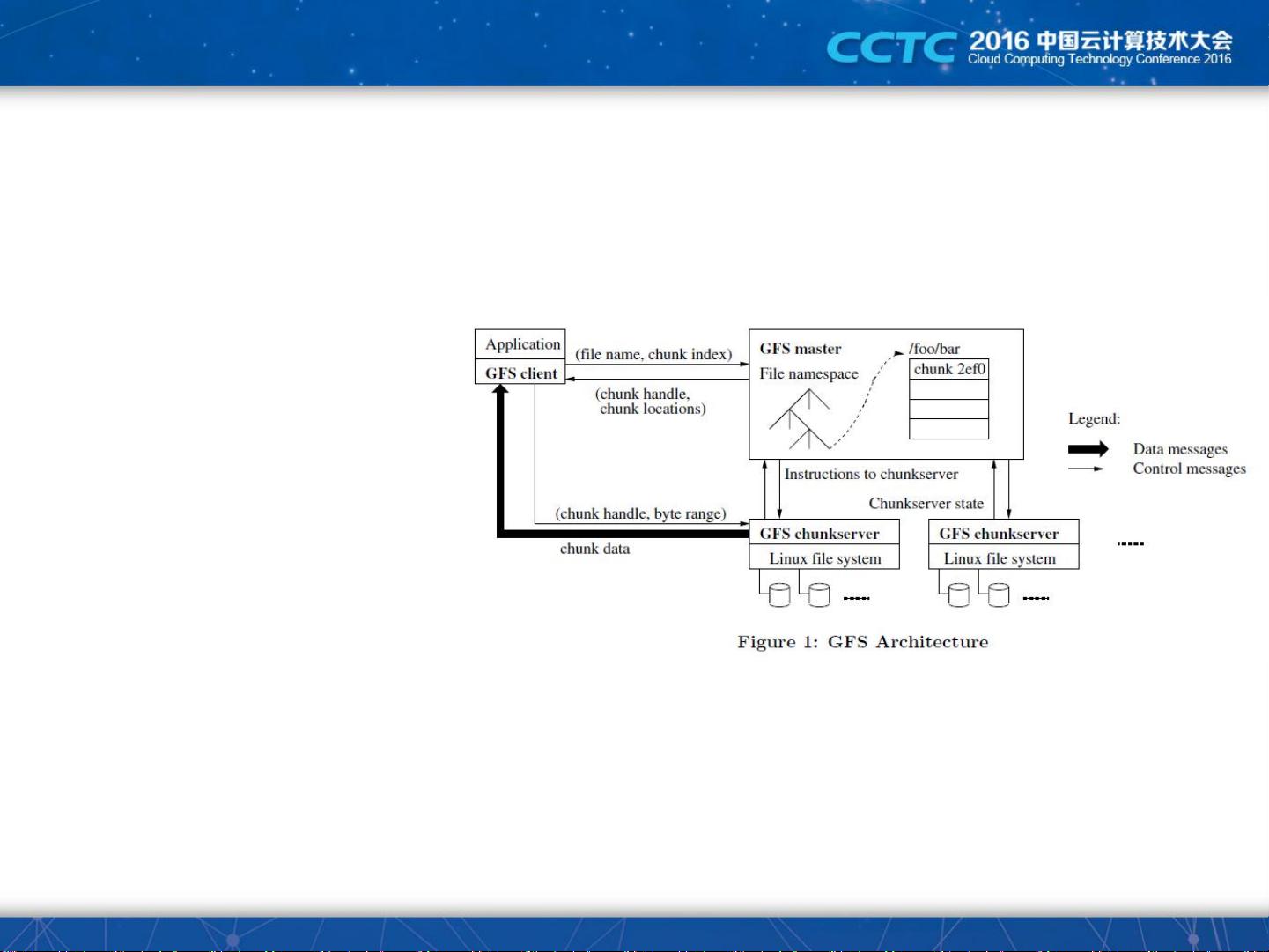
• Client
• Master
• NameSpace
• FileMeta
• DataNode
• FileData
分布式文件系统

剩余25页未读,继续阅读
189 浏览量
156 浏览量
281 浏览量
189 浏览量
362 浏览量
154 浏览量
138 浏览量
2024-06-23 上传
466 浏览量

csdn_csdn__AI
- 粉丝: 2245
- 资源: 117
 我的内容管理
展开
我的内容管理
展开







