
3
The following are the key design points,
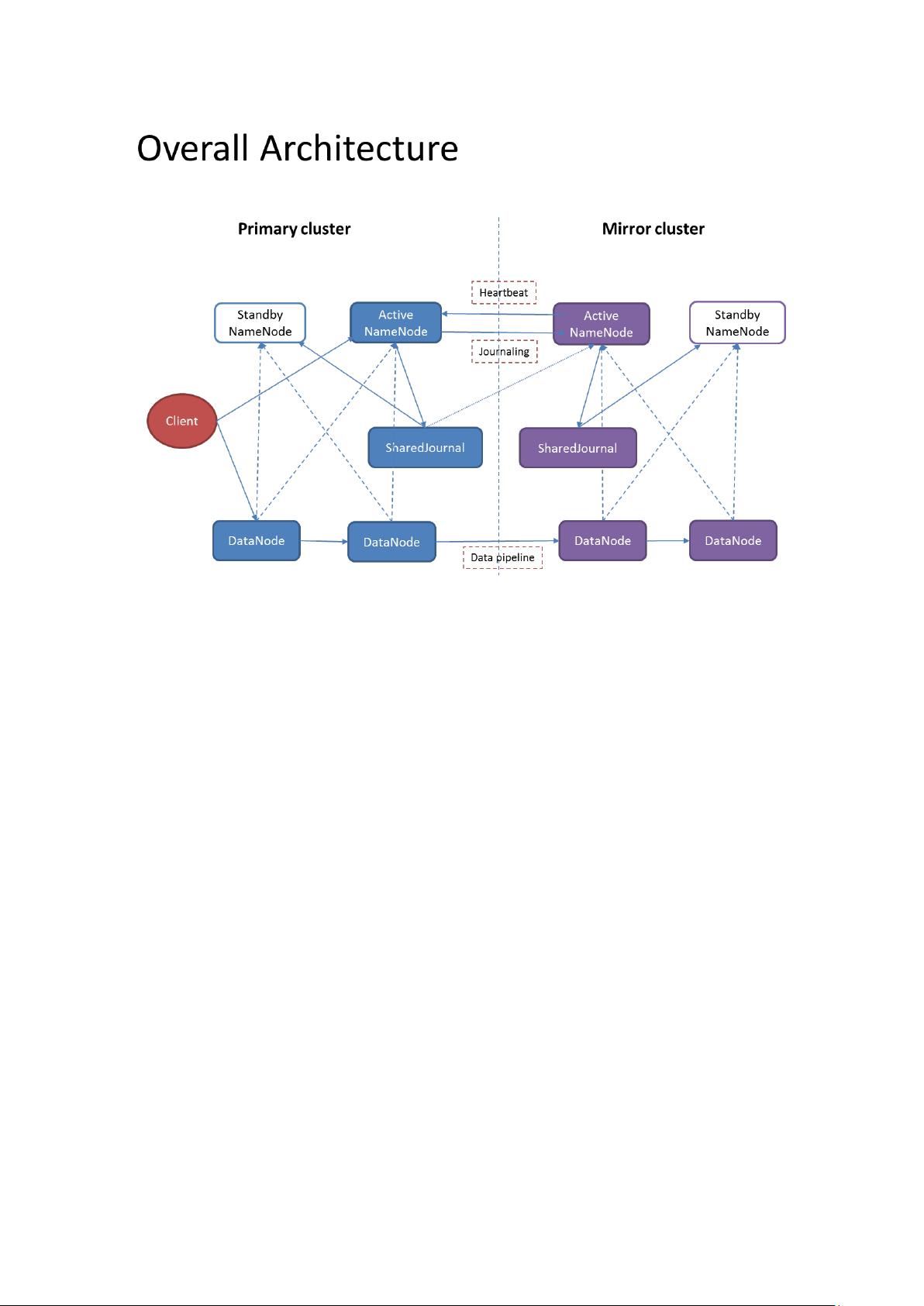
1. By improving the HDFS to support the concept of mirror cluster, we can have a single primary
cluster and multiple mirror clusters across multiple datacenters. Each cluster will still has one
Active NameNode and one Standby NameNode. The Active NameNode in each cluster will
behave different according to their cluster role.
2. There are DataNodes in both primary cluster and the mirror clusters. As normal, the DataNodes
will only heartbeat and report blocks to the NameNodes of its local cluster. That’s to say, all the
DataNodes of the primary cluster heartbeat and report blocks to the Active NameNode and
Standby NameNode of primary cluster. And all the DataNodes of the mirror clusters heartbeat
and report blocks to the Active NameNode and Standby NameNode of mirror cluster.
3. Writing data directly to mirror cluster will have performance drop, but for some users may need
more data availability than performance. So, we target to provide two options to the users in
configurable way. By default we keep the asynchronous data replications to mirror clusters.
4. To achieve synchronous data writing, we can provide new placement policy in primary cluster
which needs to make sure that it is keeping the mirror cluster DataNode in pipeline along with
primary DataNodes. The mirror cluster DataNodes always be at the end of the pipeline. So,
primary cluster should know about the available DataNodes in mirror cluster. Mirror cluster
Active NameNode will heartbeat to the primary Active NameNode with a special command
called MIRROR_DATANODE_AVAILABLE (contains DatanodeInfo with space, load, etc.). The
primary Active NameNode keep this details and will be used by the mirror placement policy
while selecting node for pipeline. To satisfy real synchronous data replication, we make sure at
least one DataNode selected from mirror cluster. But we will not keep this as strict requirement
剩余12页未读,继续阅读















