KafkaStream分布式流式处理的新贵分布式流式处理的新贵-Kafka设计解析(七)设计解析(七)
本文是系列文章的第4篇,
第一篇 "Kafka设计解析(一)- Kafka背景及架构介绍"
第二篇 "Kafka设计解析(二)- Kafka High Availability (上)
第三篇 Kafka设计解析(三)- Kafka High Availability (中)
第四篇 Kafka设计解析(四)- Kafka High Availability (下)
第五篇 Kafka设计解析(五)- Kafka Consumer设计解析
第六篇 Kafka设计解析(六)- Kafka性能测试方法及Benchmark报告
《Kafka设计解析》系列上一篇《Kafka高性能架构之道——Kafka设计解析(六)》从宏观架构到具体实现分析了Kafka实现
高性能的原理。本文介绍了Kafka Stream的架构和并发模型,同时分析了Kafka Stream如何解决流式计算的关键问题。
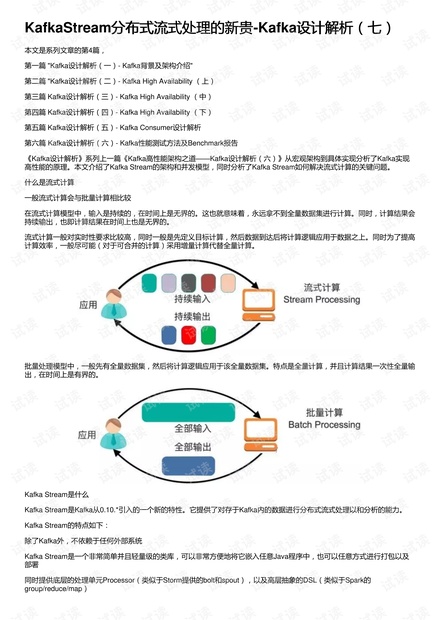
什么是流式计算
一般流式计算会与批量计算相比较
在流式计算模型中,输入是持续的,在时间上是无界的。这也就意味着,永远拿不到全量数据集进行计算。同时,计算结果会
持续输出,也即计算结果在时间上也是无界的。
流式计算一般对实时性要求比较高,同时一般是先定义目标计算,然后数据到达后将计算逻辑应用于数据之上。同时为了提高
计算效率,一般尽可能(对于可合并的计算)采用增量计算代替全量计算。
批量处理模型中,一般先有全量数据集,然后将计算逻辑应用于该全量数据集。特点是全量计算,并且计算结果一次性全量输
出,在时间上是有界的。
Kafka Stream是什么
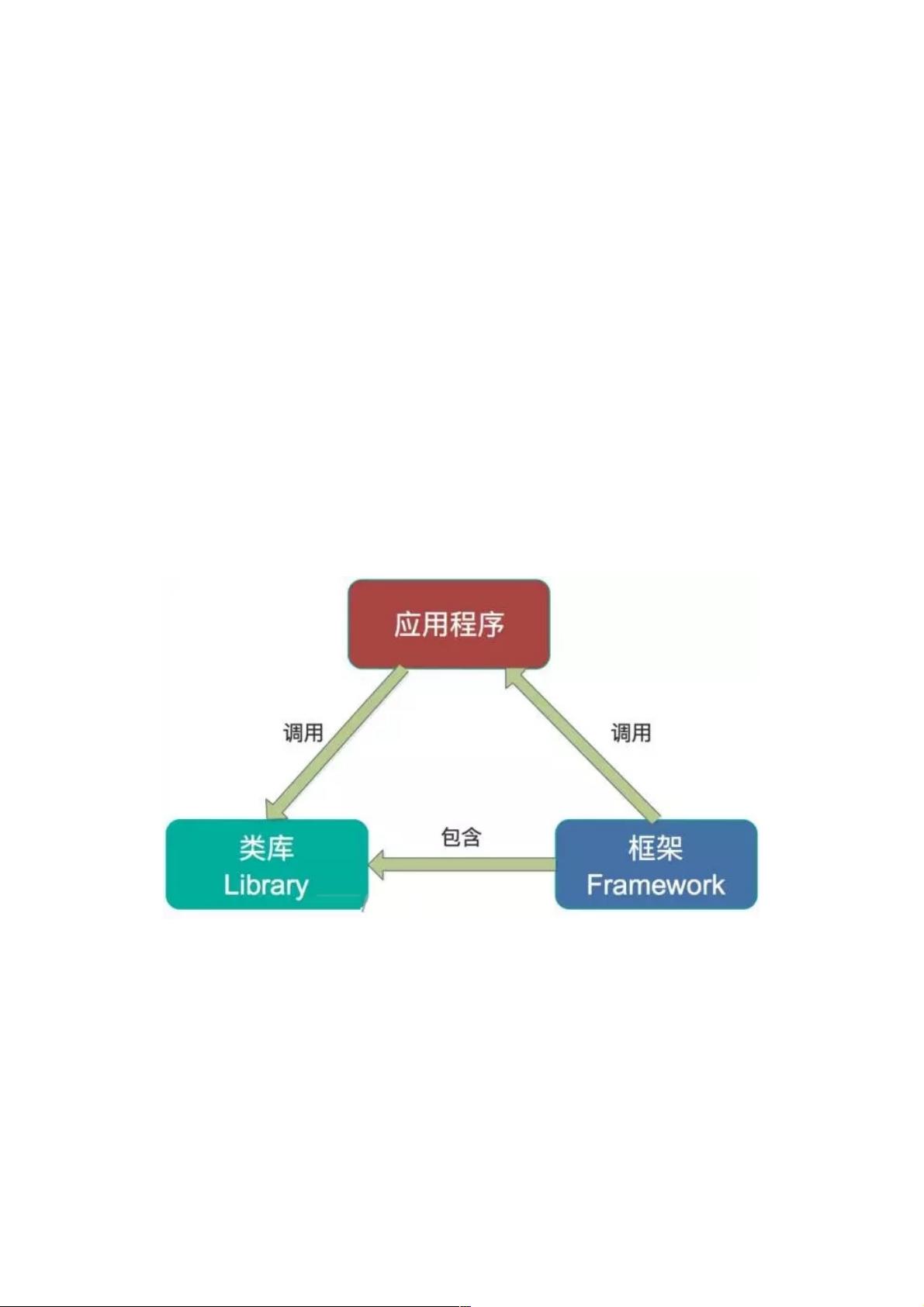
Kafka Stream是Kafka从0.10.*引入的一个新的特性。它提供了对存于Kafka内的数据进行分布式流式处理以和分析的能力。
Kafka Stream的特点如下:
除了Kafka外,不依赖于任何外部系统
Kafka Stream是一个非常简单并且轻量级的类库,可以非常方便地将它嵌入任意Java程序中,也可以任意方式进行打包以及
部署
同时提供底层的处理单元Processor(类似于Storm提供的bolt和spout),以及高层抽象的DSL(类似于Spark的
group/reduce/map)
剩余11页未读,继续阅读















