MapReduce编程模型:大规模数据处理详解
版权申诉
162 浏览量
更新于2024-08-04
收藏 222KB DOC 举报
"本文主要探讨了MapReduce编程模型在处理大数据集中的应用,以及Google的分布式计算实践。MapReduce简化了并行计算的复杂性,允许程序员专注于业务逻辑,而无需深入理解分布式系统的底层细节。"
MapReduce是Google提出的一种处理和生成大规模数据集的编程模型,它为分布式计算提供了一种抽象方式。用户只需要定义两个核心函数:Map和Reduce。Map函数接收键值对输入,处理后生成中间键值对;Reduce函数则负责对拥有相同中间键的值进行聚合处理。
MapReduce的核心思想是将任务分解为可并行处理的部分,然后在大规模的普通机器集群上自动进行数据分片、任务调度、错误恢复和通信管理。这种设计使得即使没有分布式系统经验的程序员也能高效地利用大规模分布式计算资源。
在Google的实际应用中,MapReduce系统能够灵活扩展,处理TB级别的数据,并在数千台机器上运行。由于其易用性和高效性,已经编写了数百个MapReduce程序,每天有超过1000个程序在Google的集群上执行,涵盖了诸如文档爬取、Web请求日志分析、倒排索引构建等多种任务。
MapReduce的引入解决了分布式计算中的复杂性问题。通常,大型数据处理任务涉及到数据分发、错误处理、负载均衡等多个方面,这使得原本简单的计算变得复杂。MapReduce通过抽象出Map和Reduce操作,使得程序员可以专注于业务逻辑,而将并行化、容错和数据分布等底层细节交由系统处理。这种设计借鉴了函数式编程语言中的映射和归约概念,使得大规模并行化变得简单,同时也通过任务重试实现了容错机制。
在1.介绍部分,作者指出过去五年中,Google内部实施了许多针对海量原始数据的计算任务,但这些任务的复杂性在于如何有效地并行化处理和处理错误。为了解决这个问题,MapReduce模型应运而生,它提供了简洁的编程接口,隐藏了分布式计算的复杂性,使程序员能够专注于计算本身,而无需担心分布式系统的底层实现。
MapReduce是一种强大的工具,它通过简化分布式计算的复杂性,使得处理大规模数据变得更加高效和便捷,对于大数据处理领域有着深远的影响。
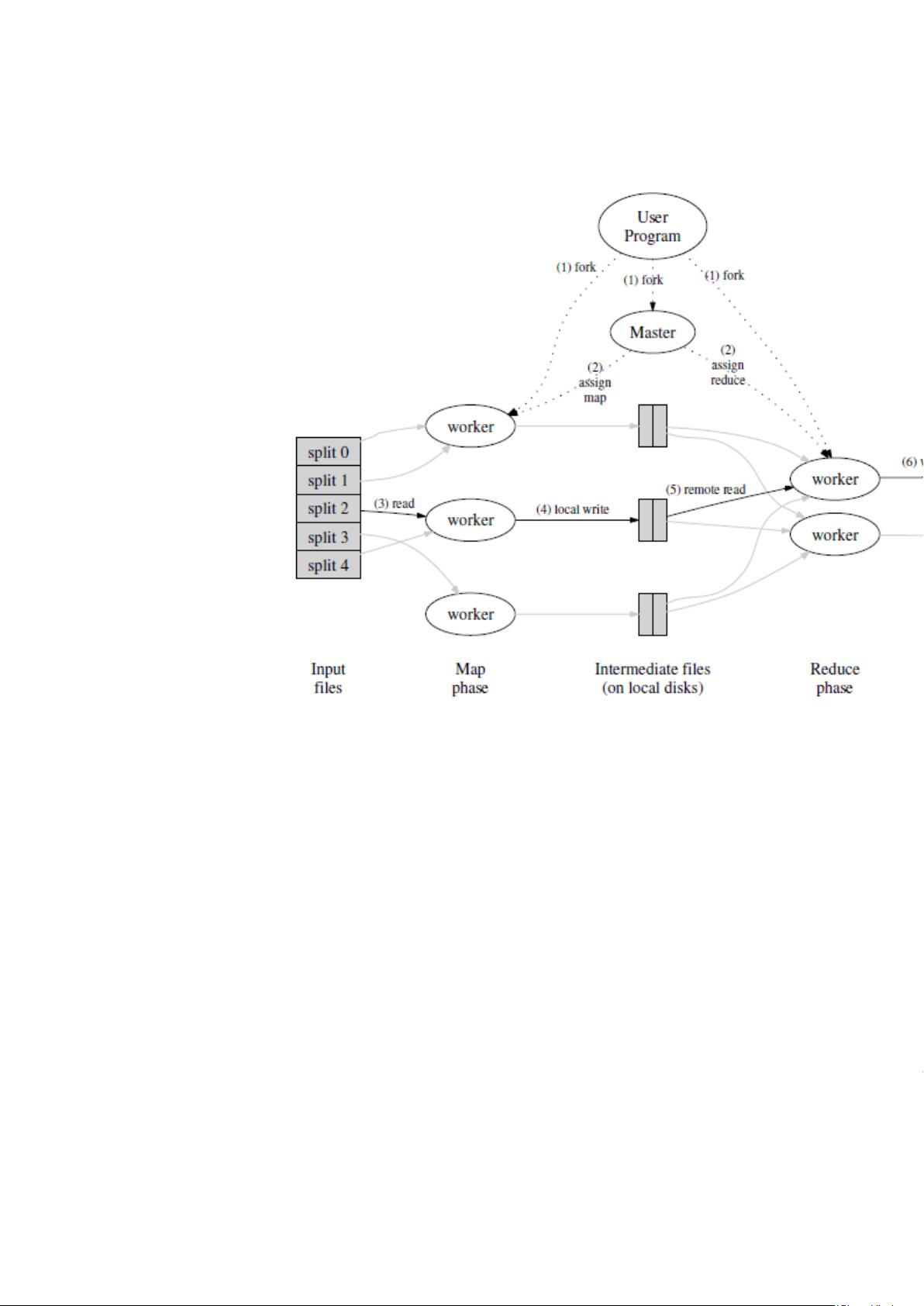
通过自动分割输入数据成一个有 M 个 split 的集,map 调用被分布到多台机器上.输入的 split 能够在不同的机器上被并行
处理.通过用分割函数分割中间 key,来形成 R 个片(例如,hash(key) mod R),reduce 调用被分布到多台机器上.分割数量(R)和分
割函数由用户来指定.
图 1
图 1 显示了我们实现的 MapReduce 操作的全部流程.当用户的程序调用 MapReduce 的函数的时候,将发生下面的一系列动作
(下面的数字和图 1 中的数字标签相对应):
1.在用户程序里的 MapReduce 库首先分割输入文件成 M 个片,每个片的大小一般从 16 到 64MB(用户可以通过可选的参数来
控制).然后在机群中开始大量的拷贝程序.
2.这些程序拷贝中的一个是 master,其他的都是由 master 分配任务的 worker.有 M 个 map 任务和 R 个 reduce 任务将
被分配.管理者分配一个 map 任务或 reduce 任务给一个空闲的 worker.
3.一个被分配了 map 任务的 worker 读取相关输入 split 的内容.它从输入数据中分析出 key/value 对,然后把 key/value
对传递给用户自定义的 map 函数.由 map 函数产生的中间 key/value 对被缓存在内存中.
4.缓存在内存中的 key/value 对被周期性的写入到本地磁盘上,通过分割函数把它们写入 R 个区域.在本地磁盘上的缓存对
的位置被传送给 master,master 负责把这些位置传送给 reduce worker.
5.当一个 reduce worker 得到 master 的位置通知的时候,它使用远程过程调用来从 map worker 的磁盘上读取缓存的数据.当
reduce worker 读取了所有的中间数据后,它通过排序使具有相同 key 的内容聚合在一起.因为许多不同的 key 映射到相同的
reduce 任务,所以排序是必须的.如果中间数据比内存还大,那么还需要一个外部排序.
6.reduce worker 迭代排过序的中间数据,对于遇到的每一个唯一的中间 key,它把 key 和相关的中间 value 集传递给用
户自定义的 reduce 函数.reduce 函数的输出被添加到这个 reduce 分割的最终的输出文件中.
7.当所有的 map 和 reduce 任务都完成了,管理者唤醒用户程序.在这个时候,在用户程序里的 MapReduce 调用返回到用户代
码.
在成功完成之后,mapreduce 执行的输出存放在 R 个输出文件中(每一个 reduce 任务产生一个由用户指定名字的文件).一般,
剩余13页未读,继续阅读
点击了解资源详情
点击了解资源详情
点击了解资源详情
2022-05-05 上传
2022-11-29 上传
2021-10-11 上传
2022-07-07 上传
2021-09-21 上传
2021-10-03 上传

小小哭包
- 粉丝: 2082
- 资源: 4263
 我的内容管理
展开
我的内容管理
展开







最新资源
- spring-data-orientdb:SpringData的OrientDB实现
- 施耐德PLC通讯样例.zip昆仑通态触摸屏案例编程源码资料下载
- Sort-Text-by-length-and-alphabetically:EKU的CSC 499作业1
- Resume
- amazon-corretto-crypto-provider:Amazon Corretto加密提供程序是通过标准JCAJCE接口公开的高性能加密实现的集合
- array-buffer-concat:连接数组缓冲区
- api-annotations
- 行业数据-20年春节期间(20年1月份24日-2月份9日)中国消费者线上购买生鲜食材平均每单价格调查.rar
- ex8Loops1
- react-travellers-trollies
- Bootcamp:2021年的训练营
- SpookyHashingAtADistance:纳米服务革命的突破口
- 蛇怪队
- address-semantic-search:基于TF-IDF余弦相似度的地址语义搜索解析匹配服务
- 摩尔斯键盘-项目开发
- Terraria_Macrocosm:空间
